 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJust Enough Thinking: Efficient Reasoning with Adaptive Length Penalties Reinforcement Learning
Jun 06, 2025Large reasoning models (LRMs) achieve higher performance on challenging reasoning tasks by generating more tokens at inference time, but this verbosity often wastes computation on easy problems. Existing solutions, including supervised finetuning on shorter traces, user-controlled budgets, or RL with uniform penalties, either require data curation, manual configuration, or treat all problems alike regardless of difficulty. We introduce Adaptive Length Penalty (ALP), a reinforcement learning objective tailoring generation length to per-prompt solve rate. During training, ALP monitors each prompt's online solve rate through multiple rollouts and adds a differentiable penalty whose magnitude scales inversely with that rate, so confident (easy) prompts incur a high cost for extra tokens while hard prompts remain unhindered. Posttraining DeepScaleR-1.5B with ALP cuts average token usage by 50\% without significantly dropping performance. Relative to fixed-budget and uniform penalty baselines, ALP redistributes its reduced budget more intelligently by cutting compute on easy prompts and reallocating saved tokens to difficult ones, delivering higher accuracy on the hardest problems with higher cost.
Reliable and Efficient Amortized Model-based Evaluation
Mar 17, 2025Comprehensive evaluations of language models (LM) during both development and deployment phases are necessary because these models possess numerous capabilities (e.g., mathematical reasoning, legal support, or medical diagnostic) as well as safety risks (e.g., racial bias, toxicity, or misinformation). The average score across a wide range of benchmarks provides a signal that helps guide the use of these LMs in practice. Currently, holistic evaluations are costly due to the large volume of benchmark questions, making frequent evaluations impractical. A popular attempt to lower the cost is to compute the average score on a subset of the benchmark. This approach, unfortunately, often renders an unreliable measure of LM performance because the average score is often confounded with the difficulty of the questions in the benchmark subset. Item response theory (IRT) was designed to address this challenge, providing a reliable measurement by careful controlling for question difficulty. Unfortunately, question difficulty is expensive to estimate. Facing this challenge, we train a model that predicts question difficulty from its content, enabling a reliable measurement at a fraction of the cost. In addition, we leverage this difficulty predictor to further improve the evaluation efficiency through training a question generator given a difficulty level. This question generator is essential in adaptive testing, where, instead of using a random subset of the benchmark questions, informative questions are adaptively chosen based on the current estimation of LLM performance. Experiments on 22 common natural language benchmarks and 172 LMs show that this approach is more reliable and efficient compared to current common practice.
CarcassFormer: An End-to-end Transformer-based Framework for Simultaneous Localization, Segmentation and Classification of Poultry Carcass Defect
Apr 17, 2024In the food industry, assessing the quality of poultry carcasses during processing is a crucial step. This study proposes an effective approach for automating the assessment of carcass quality without requiring skilled labor or inspector involvement. The proposed system is based on machine learning (ML) and computer vision (CV) techniques, enabling automated defect detection and carcass quality assessment. To this end, an end-to-end framework called CarcassFormer is introduced. It is built upon a Transformer-based architecture designed to effectively extract visual representations while simultaneously detecting, segmenting, and classifying poultry carcass defects. Our proposed framework is capable of analyzing imperfections resulting from production and transport welfare issues, as well as processing plant stunner, scalder, picker, and other equipment malfunctions. To benchmark the framework, a dataset of 7,321 images was initially acquired, which contained both single and multiple carcasses per image. In this study, the performance of the CarcassFormer system is compared with other state-of-the-art (SOTA) approaches for both classification, detection, and segmentation tasks. Through extensive quantitative experiments, our framework consistently outperforms existing methods, demonstrating remarkable improvements across various evaluation metrics such as AP, AP@50, and AP@75. Furthermore, the qualitative results highlight the strengths of CarcassFormer in capturing fine details, including feathers, and accurately localizing and segmenting carcasses with high precision. To facilitate further research and collaboration, the pre-trained model and source code of CarcassFormer is available for research purposes at: \url{https://github.com/UARK-AICV/CarcassFormer}.
Bridging Associative Memory and Probabilistic Modeling
Feb 15, 2024Associative memory and probabilistic modeling are two fundamental topics in artificial intelligence. The first studies recurrent neural networks designed to denoise, complete and retrieve data, whereas the second studies learning and sampling from probability distributions. Based on the observation that associative memory's energy functions can be seen as probabilistic modeling's negative log likelihoods, we build a bridge between the two that enables useful flow of ideas in both directions. We showcase four examples: First, we propose new energy-based models that flexibly adapt their energy functions to new in-context datasets, an approach we term \textit{in-context learning of energy functions}. Second, we propose two new associative memory models: one that dynamically creates new memories as necessitated by the training data using Bayesian nonparametrics, and another that explicitly computes proportional memory assignments using the evidence lower bound. Third, using tools from associative memory, we analytically and numerically characterize the memory capacity of Gaussian kernel density estimators, a widespread tool in probababilistic modeling. Fourth, we study a widespread implementation choice in transformers -- normalization followed by self attention -- to show it performs clustering on the hypersphere. Altogether, this work urges further exchange of useful ideas between these two continents of artificial intelligence.
GAUCHE: A Library for Gaussian Processes in Chemistry
Dec 06, 2022We introduce GAUCHE, a library for GAUssian processes in CHEmistry. Gaussian processes have long been a cornerstone of probabilistic machine learning, affording particular advantages for uncertainty quantification and Bayesian optimisation. Extending Gaussian processes to chemical representations, however, is nontrivial, necessitating kernels defined over structured inputs such as graphs, strings and bit vectors. By defining such kernels in GAUCHE, we seek to open the door to powerful tools for uncertainty quantification and Bayesian optimisation in chemistry. Motivated by scenarios frequently encountered in experimental chemistry, we showcase applications for GAUCHE in molecular discovery and chemical reaction optimisation. The codebase is made available at https://github.com/leojklarner/gauche
VLTinT: Visual-Linguistic Transformer-in-Transformer for Coherent Video Paragraph Captioning
Nov 28, 2022Video paragraph captioning aims to generate a multi-sentence description of an untrimmed video with several temporal event locations in coherent storytelling. Following the human perception process, where the scene is effectively understood by decomposing it into visual (e.g. human, animal) and non-visual components (e.g. action, relations) under the mutual influence of vision and language, we first propose a visual-linguistic (VL) feature. In the proposed VL feature, the scene is modeled by three modalities including (i) a global visual environment; (ii) local visual main agents; (iii) linguistic scene elements. We then introduce an autoregressive Transformer-in-Transformer (TinT) to simultaneously capture the semantic coherence of intra- and inter-event contents within a video. Finally, we present a new VL contrastive loss function to guarantee learnt embedding features are matched with the captions semantics. Comprehensive experiments and extensive ablation studies on ActivityNet Captions and YouCookII datasets show that the proposed Visual-Linguistic Transformer-in-Transform (VLTinT) outperforms prior state-of-the-art methods on accuracy and diversity.
AOE-Net: Entities Interactions Modeling with Adaptive Attention Mechanism for Temporal Action Proposals Generation
Oct 05, 2022Temporal action proposal generation (TAPG) is a challenging task, which requires localizing action intervals in an untrimmed video. Intuitively, we as humans, perceive an action through the interactions between actors, relevant objects, and the surrounding environment. Despite the significant progress of TAPG, a vast majority of existing methods ignore the aforementioned principle of the human perceiving process by applying a backbone network into a given video as a black-box. In this paper, we propose to model these interactions with a multi-modal representation network, namely, Actors-Objects-Environment Interaction Network (AOE-Net). Our AOE-Net consists of two modules, i.e., perception-based multi-modal representation (PMR) and boundary-matching module (BMM). Additionally, we introduce adaptive attention mechanism (AAM) in PMR to focus only on main actors (or relevant objects) and model the relationships among them. PMR module represents each video snippet by a visual-linguistic feature, in which main actors and surrounding environment are represented by visual information, whereas relevant objects are depicted by linguistic features through an image-text model. BMM module processes the sequence of visual-linguistic features as its input and generates action proposals. Comprehensive experiments and extensive ablation studies on ActivityNet-1.3 and THUMOS-14 datasets show that our proposed AOE-Net outperforms previous state-of-the-art methods with remarkable performance and generalization for both TAPG and temporal action detection. To prove the robustness and effectiveness of AOE-Net, we further conduct an ablation study on egocentric videos, i.e. EPIC-KITCHENS 100 dataset. Source code is available upon acceptance.
Wildfire Forecasting with Satellite Images and Deep Generative Model
Aug 22, 2022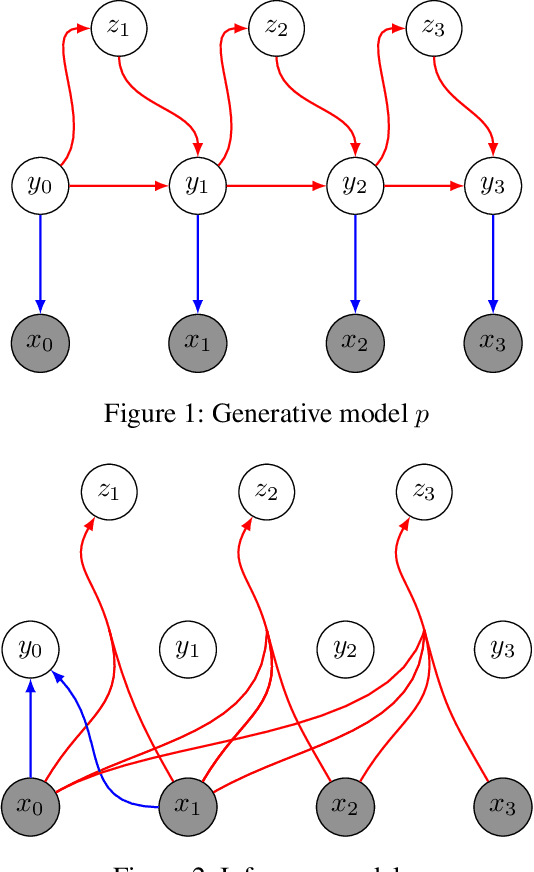

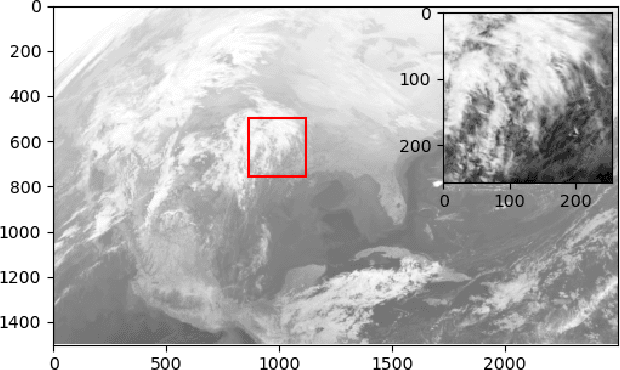
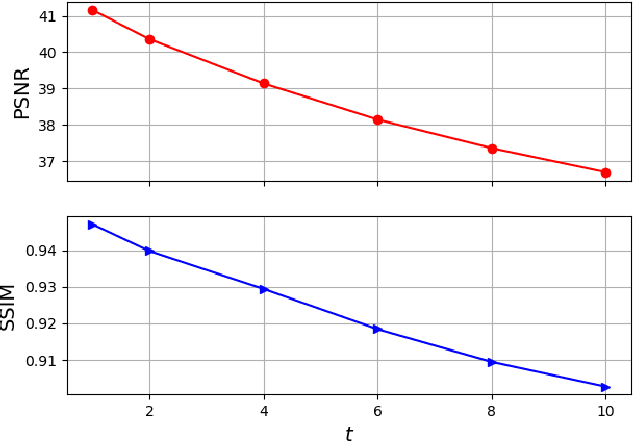
Wildfire forecasting has been one of the most critical tasks that humanities want to thrive. It plays a vital role in protecting human life. Wildfire prediction, on the other hand, is difficult because of its stochastic and chaotic properties. We tackled the problem by interpreting a series of wildfire images as a video and used it to anticipate how the fire would behave in the future. However, creating video prediction models that account for the inherent uncertainty of the future is challenging. The bulk of published attempts is based on stochastic image-autoregressive recurrent networks, which raises various performance and application difficulties, such as computational cost and limited efficiency on massive datasets. Another possibility is to use entirely latent temporal models that combine frame synthesis and temporal dynamics. However, due to design and training issues, no such model for stochastic video prediction has yet been proposed in the literature. This paper addresses these issues by introducing a novel stochastic temporal model whose dynamics are driven in a latent space. It naturally predicts video dynamics by allowing our lighter, more interpretable latent model to beat previous state-of-the-art approaches on the GOES-16 dataset. Results will be compared towards various benchmarking models.
VLCap: Vision-Language with Contrastive Learning for Coherent Video Paragraph Captioning
Jun 26, 2022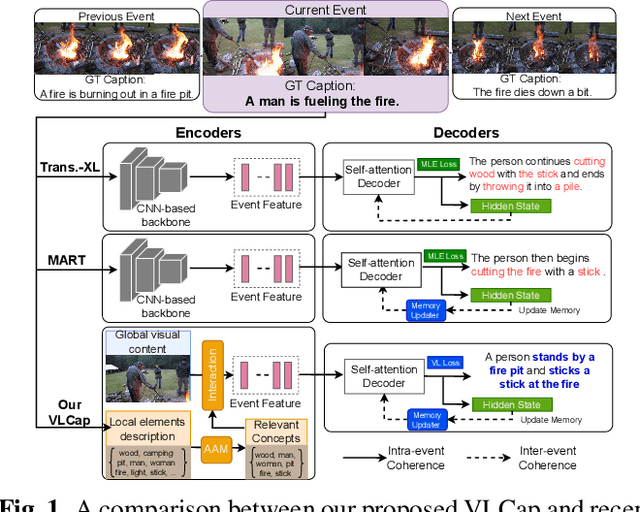
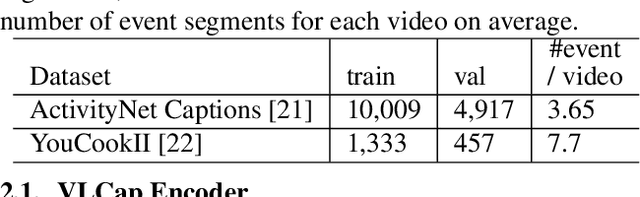
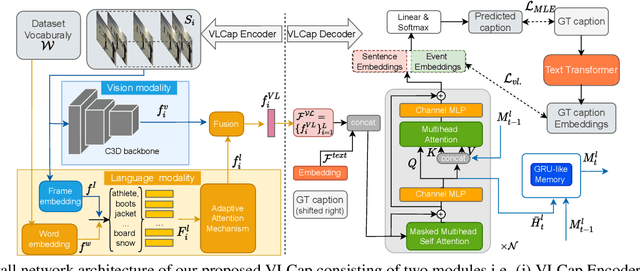

In this paper, we leverage the human perceiving process, that involves vision and language interaction, to generate a coherent paragraph description of untrimmed videos. We propose vision-language (VL) features consisting of two modalities, i.e., (i) vision modality to capture global visual content of the entire scene and (ii) language modality to extract scene elements description of both human and non-human objects (e.g. animals, vehicles, etc), visual and non-visual elements (e.g. relations, activities, etc). Furthermore, we propose to train our proposed VLCap under a contrastive learning VL loss. The experiments and ablation studies on ActivityNet Captions and YouCookII datasets show that our VLCap outperforms existing SOTA methods on both accuracy and diversity metrics.
ABN: Agent-Aware Boundary Networks for Temporal Action Proposal Generation
Mar 16, 2022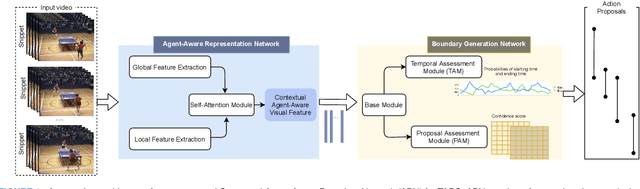
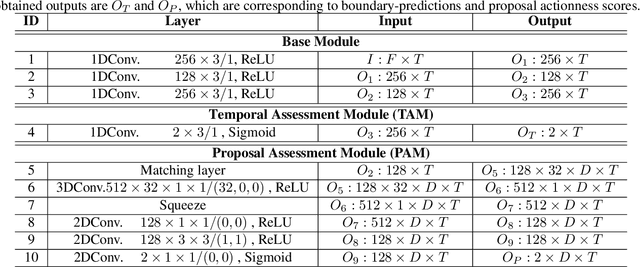
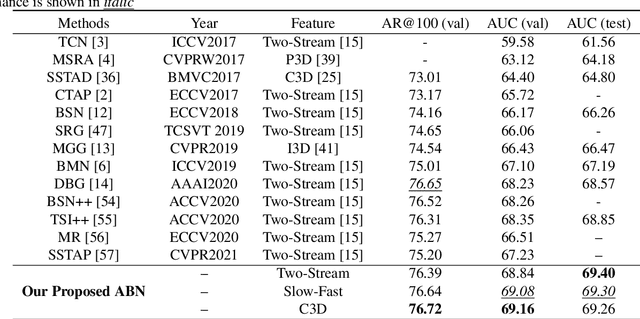
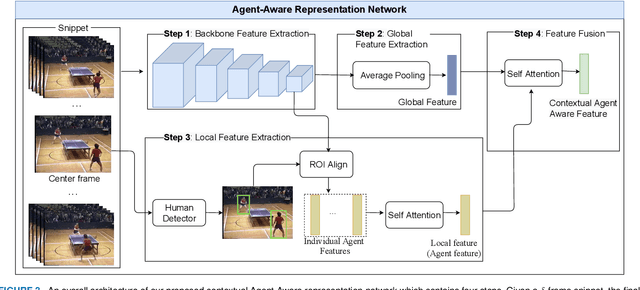
Temporal action proposal generation (TAPG) aims to estimate temporal intervals of actions in untrimmed videos, which is a challenging yet plays an important role in many tasks of video analysis and understanding. Despite the great achievement in TAPG, most existing works ignore the human perception of interaction between agents and the surrounding environment by applying a deep learning model as a black-box to the untrimmed videos to extract video visual representation. Therefore, it is beneficial and potentially improve the performance of TAPG if we can capture these interactions between agents and the environment. In this paper, we propose a novel framework named Agent-Aware Boundary Network (ABN), which consists of two sub-networks (i) an Agent-Aware Representation Network to obtain both agent-agent and agents-environment relationships in the video representation, and (ii) a Boundary Generation Network to estimate the confidence score of temporal intervals. In the Agent-Aware Representation Network, the interactions between agents are expressed through local pathway, which operates at a local level to focus on the motions of agents whereas the overall perception of the surroundings are expressed through global pathway, which operates at a global level to perceive the effects of agents-environment. Comprehensive evaluations on 20-action THUMOS-14 and 200-action ActivityNet-1.3 datasets with different backbone networks (i.e C3D, SlowFast and Two-Stream) show that our proposed ABN robustly outperforms state-of-the-art methods regardless of the employed backbone network on TAPG. We further examine the proposal quality by leveraging proposals generated by our method onto temporal action detection (TAD) frameworks and evaluate their detection performances. The source code can be found in this URL https://github.com/vhvkhoa/TAPG-AgentEnvNetwork.git.