 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Progression of Memory State in Robotic Manipulation: An Object-Centric Perspective
Nov 18, 2025As embodied agents operate in increasingly complex environments, the ability to perceive, track, and reason about individual object instances over time becomes essential, especially in tasks requiring sequenced interactions with visually similar objects. In these non-Markovian settings, key decision cues are often hidden in object-specific histories rather than the current scene. Without persistent memory of prior interactions (what has been interacted with, where it has been, or how it has changed) visuomotor policies may fail, repeat past actions, or overlook completed ones. To surface this challenge, we introduce LIBERO-Mem, a non-Markovian task suite for stress-testing robotic manipulation under object-level partial observability. It combines short- and long-horizon object tracking with temporally sequenced subgoals, requiring reasoning beyond the current frame. However, vision-language-action (VLA) models often struggle in such settings, with token scaling quickly becoming intractable even for tasks spanning just a few hundred frames. We propose Embodied-SlotSSM, a slot-centric VLA framework built for temporal scalability. It maintains spatio-temporally consistent slot identities and leverages them through two mechanisms: (1) slot-state-space modeling for reconstructing short-term history, and (2) a relational encoder to align the input tokens with action decoding. Together, these components enable temporally grounded, context-aware action prediction. Experiments show Embodied-SlotSSM's baseline performance on LIBERO-Mem and general tasks, offering a scalable solution for non-Markovian reasoning in object-centric robotic policies.
SlotVLA: Towards Modeling of Object-Relation Representations in Robotic Manipulation
Nov 10, 2025Inspired by how humans reason over discrete objects and their relationships, we explore whether compact object-centric and object-relation representations can form a foundation for multitask robotic manipulation. Most existing robotic multitask models rely on dense embeddings that entangle both object and background cues, raising concerns about both efficiency and interpretability. In contrast, we study object-relation-centric representations as a pathway to more structured, efficient, and explainable visuomotor control. Our contributions are two-fold. First, we introduce LIBERO+, a fine-grained benchmark dataset designed to enable and evaluate object-relation reasoning in robotic manipulation. Unlike prior datasets, LIBERO+ provides object-centric annotations that enrich demonstrations with box- and mask-level labels as well as instance-level temporal tracking, supporting compact and interpretable visuomotor representations. Second, we propose SlotVLA, a slot-attention-based framework that captures both objects and their relations for action decoding. It uses a slot-based visual tokenizer to maintain consistent temporal object representations, a relation-centric decoder to produce task-relevant embeddings, and an LLM-driven module that translates these embeddings into executable actions. Experiments on LIBERO+ demonstrate that object-centric slot and object-relation slot representations drastically reduce the number of required visual tokens, while providing competitive generalization. Together, LIBERO+ and SlotVLA provide a compact, interpretable, and effective foundation for advancing object-relation-centric robotic manipulation.
HENASY: Learning to Assemble Scene-Entities for Egocentric Video-Language Model
Jun 01, 2024Video-Language Models (VLMs), pre-trained on large-scale video-caption datasets, are now standard for robust visual-language representation and downstream tasks. However, their reliance on global contrastive alignment limits their ability to capture fine-grained interactions between visual and textual elements. To address these challenges, we introduce HENASY (Hierarchical ENtities ASsemblY), a novel framework designed for egocentric video analysis that enhances the granularity of video content representations. HENASY employs a compositional approach using an enhanced slot-attention and grouping mechanisms for videos, assembling dynamic entities from video patches. It integrates a local entity encoder for dynamic modeling, a global encoder for broader contextual understanding, and an entity-aware decoder for late-stage fusion, enabling effective video scene dynamics modeling and granular-level alignment between visual entities and text. By incorporating innovative contrastive losses, HENASY significantly improves entity and activity recognition, delivering superior performance on benchmarks such as Ego4D and EpicKitchen, and setting new standards in both zero-shot and extensive video understanding tasks. Our results confirm groundbreaking capabilities of HENASY and establish it as a significant advancement in video-language multimodal research.
Open-Fusion: Real-time Open-Vocabulary 3D Mapping and Queryable Scene Representation
Oct 05, 2023



Precise 3D environmental mapping is pivotal in robotics. Existing methods often rely on predefined concepts during training or are time-intensive when generating semantic maps. This paper presents Open-Fusion, a groundbreaking approach for real-time open-vocabulary 3D mapping and queryable scene representation using RGB-D data. Open-Fusion harnesses the power of a pre-trained vision-language foundation model (VLFM) for open-set semantic comprehension and employs the Truncated Signed Distance Function (TSDF) for swift 3D scene reconstruction. By leveraging the VLFM, we extract region-based embeddings and their associated confidence maps. These are then integrated with 3D knowledge from TSDF using an enhanced Hungarian-based feature-matching mechanism. Notably, Open-Fusion delivers outstanding annotation-free 3D segmentation for open-vocabulary without necessitating additional 3D training. Benchmark tests on the ScanNet dataset against leading zero-shot methods highlight Open-Fusion's superiority. Furthermore, it seamlessly combines the strengths of region-based VLFM and TSDF, facilitating real-time 3D scene comprehension that includes object concepts and open-world semantics. We encourage the readers to view the demos on our project page: https://uark-aicv.github.io/OpenFusion
AerialFormer: Multi-resolution Transformer for Aerial Image Segmentation
Jun 12, 2023Aerial Image Segmentation is a top-down perspective semantic segmentation and has several challenging characteristics such as strong imbalance in the foreground-background distribution, complex background, intra-class heterogeneity, inter-class homogeneity, and tiny objects. To handle these problems, we inherit the advantages of Transformers and propose AerialFormer, which unifies Transformers at the contracting path with lightweight Multi-Dilated Convolutional Neural Networks (MD-CNNs) at the expanding path. Our AerialFormer is designed as a hierarchical structure, in which Transformer encoder outputs multi-scale features and MD-CNNs decoder aggregates information from the multi-scales. Thus, it takes both local and global contexts into consideration to render powerful representations and high-resolution segmentation. We have benchmarked AerialFormer on three common datasets including iSAID, LoveDA, and Potsdam. Comprehensive experiments and extensive ablation studies show that our proposed AerialFormer outperforms previous state-of-the-art methods with remarkable performance. Our source code will be publicly available upon acceptance.
Contextual Explainable Video Representation: Human Perception-based Understanding
Dec 17, 2022


Video understanding is a growing field and a subject of intense research, which includes many interesting tasks to understanding both spatial and temporal information, e.g., action detection, action recognition, video captioning, video retrieval. One of the most challenging problems in video understanding is dealing with feature extraction, i.e. extract contextual visual representation from given untrimmed video due to the long and complicated temporal structure of unconstrained videos. Different from existing approaches, which apply a pre-trained backbone network as a black-box to extract visual representation, our approach aims to extract the most contextual information with an explainable mechanism. As we observed, humans typically perceive a video through the interactions between three main factors, i.e., the actors, the relevant objects, and the surrounding environment. Therefore, it is very crucial to design a contextual explainable video representation extraction that can capture each of such factors and model the relationships between them. In this paper, we discuss approaches, that incorporate the human perception process into modeling actors, objects, and the environment. We choose video paragraph captioning and temporal action detection to illustrate the effectiveness of human perception based-contextual representation in video understanding. Source code is publicly available at https://github.com/UARK-AICV/Video_Representation.
CLIP-TSA: CLIP-Assisted Temporal Self-Attention for Weakly-Supervised Video Anomaly Detection
Dec 09, 2022Video anomaly detection (VAD) -- commonly formulated as a multiple-instance learning problem in a weakly-supervised manner due to its labor-intensive nature -- is a challenging problem in video surveillance where the frames of anomaly need to be localized in an untrimmed video. In this paper, we first propose to utilize the ViT-encoded visual features from CLIP, in contrast with the conventional C3D or I3D features in the domain, to efficiently extract discriminative representations in the novel technique. We then model long- and short-range temporal dependencies and nominate the snippets of interest by leveraging our proposed Temporal Self-Attention (TSA). The ablation study conducted on each component confirms its effectiveness in the problem, and the extensive experiments show that our proposed CLIP-TSA outperforms the existing state-of-the-art (SOTA) methods by a large margin on two commonly-used benchmark datasets in the VAD problem (UCF-Crime and ShanghaiTech Campus). The source code will be made publicly available upon acceptance.
VLTinT: Visual-Linguistic Transformer-in-Transformer for Coherent Video Paragraph Captioning
Nov 28, 2022Video paragraph captioning aims to generate a multi-sentence description of an untrimmed video with several temporal event locations in coherent storytelling. Following the human perception process, where the scene is effectively understood by decomposing it into visual (e.g. human, animal) and non-visual components (e.g. action, relations) under the mutual influence of vision and language, we first propose a visual-linguistic (VL) feature. In the proposed VL feature, the scene is modeled by three modalities including (i) a global visual environment; (ii) local visual main agents; (iii) linguistic scene elements. We then introduce an autoregressive Transformer-in-Transformer (TinT) to simultaneously capture the semantic coherence of intra- and inter-event contents within a video. Finally, we present a new VL contrastive loss function to guarantee learnt embedding features are matched with the captions semantics. Comprehensive experiments and extensive ablation studies on ActivityNet Captions and YouCookII datasets show that the proposed Visual-Linguistic Transformer-in-Transform (VLTinT) outperforms prior state-of-the-art methods on accuracy and diversity.
AISFormer: Amodal Instance Segmentation with Transformer
Oct 13, 2022
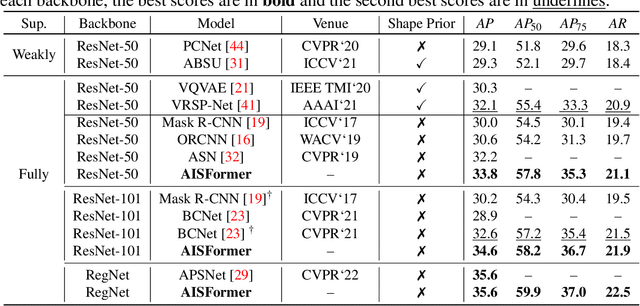


Amodal Instance Segmentation (AIS) aims to segment the region of both visible and possible occluded parts of an object instance. While Mask R-CNN-based AIS approaches have shown promising results, they are unable to model high-level features coherence due to the limited receptive field. The most recent transformer-based models show impressive performance on vision tasks, even better than Convolution Neural Networks (CNN). In this work, we present AISFormer, an AIS framework, with a Transformer-based mask head. AISFormer explicitly models the complex coherence between occluder, visible, amodal, and invisible masks within an object's regions of interest by treating them as learnable queries. Specifically, AISFormer contains four modules: (i) feature encoding: extract ROI and learn both short-range and long-range visual features. (ii) mask transformer decoding: generate the occluder, visible, and amodal mask query embeddings by a transformer decoder (iii) invisible mask embedding: model the coherence between the amodal and visible masks, and (iv) mask predicting: estimate output masks including occluder, visible, amodal and invisible. We conduct extensive experiments and ablation studies on three challenging benchmarks i.e. KINS, D2SA, and COCOA-cls to evaluate the effectiveness of AISFormer. The code is available at: https://github.com/UARK-AICV/AISFormer
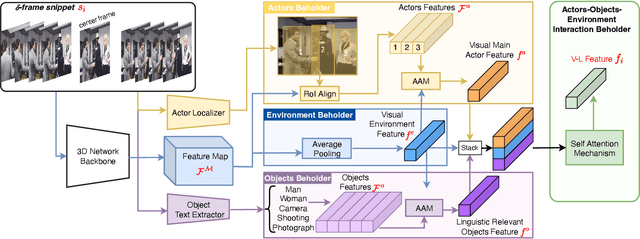
AOE-Net: Entities Interactions Modeling with Adaptive Attention Mechanism for Temporal Action Proposals Generation
Oct 05, 2022Temporal action proposal generation (TAPG) is a challenging task, which requires localizing action intervals in an untrimmed video. Intuitively, we as humans, perceive an action through the interactions between actors, relevant objects, and the surrounding environment. Despite the significant progress of TAPG, a vast majority of existing methods ignore the aforementioned principle of the human perceiving process by applying a backbone network into a given video as a black-box. In this paper, we propose to model these interactions with a multi-modal representation network, namely, Actors-Objects-Environment Interaction Network (AOE-Net). Our AOE-Net consists of two modules, i.e., perception-based multi-modal representation (PMR) and boundary-matching module (BMM). Additionally, we introduce adaptive attention mechanism (AAM) in PMR to focus only on main actors (or relevant objects) and model the relationships among them. PMR module represents each video snippet by a visual-linguistic feature, in which main actors and surrounding environment are represented by visual information, whereas relevant objects are depicted by linguistic features through an image-text model. BMM module processes the sequence of visual-linguistic features as its input and generates action proposals. Comprehensive experiments and extensive ablation studies on ActivityNet-1.3 and THUMOS-14 datasets show that our proposed AOE-Net outperforms previous state-of-the-art methods with remarkable performance and generalization for both TAPG and temporal action detection. To prove the robustness and effectiveness of AOE-Net, we further conduct an ablation study on egocentric videos, i.e. EPIC-KITCHENS 100 dataset. Source code is available upon acceptance.