 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemLT3D: Semantic-Guided Expert Distillation for Camera-only Long-Tailed 3D Object Detection
Apr 20, 2026Camera-only 3D object detection has emerged as a cost-effective and scalable alternative to LiDAR for autonomous driving, yet existing methods primarily prioritize overall performance while overlooking the severe long-tail imbalance inherent in real-world datasets. In practice, many rare but safety-critical categories such as children, strollers, or emergency vehicles are heavily underrepresented, leading to biased learning and degraded performance. This challenge is further exacerbated by pronounced inter-class ambiguity (e.g., visually similar subclasses) and substantial intra-class diversity (e.g., objects varying widely in appearance, scale, pose, or context), which together hinder reliable long-tail recognition. In this work, we introduce SemLT3D, a Semantic-Guided Expert Distillation framework designed to enrich the representation space for underrepresented classes through semantic priors. SemLT3D consists of: (1) a language-guided mixture-of-experts module that routes 3D queries to specialized experts according to their semantic affinity, enabling the model to better disentangle confusing classes and specialize on tail distributions; and (2) a semantic projection distillation pipeline that aligns 3D queries with CLIP-informed 2D semantics, producing more coherent and discriminative features across diverse visual manifestations. Although motivated by long-tail imbalance, the semantically structured learning in SemLT3D also improves robustness under broader appearance variations and challenging corner cases, offering a principled step toward more reliable camera-only 3D perception.
Rethinking Self-Supervised Learning Within the Framework of Partial Information Decomposition
Dec 03, 2024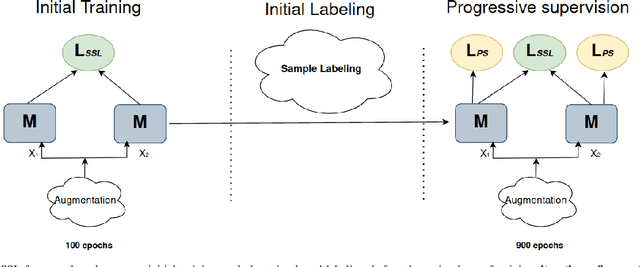


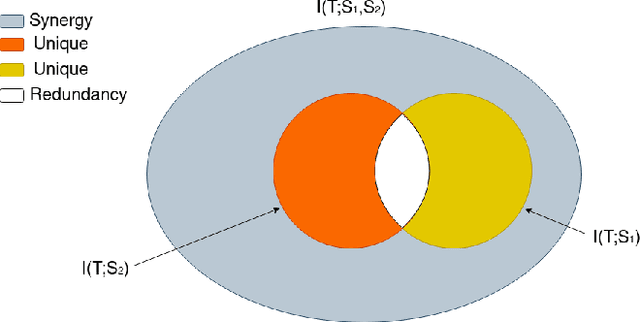
Self Supervised learning (SSL) has demonstrated its effectiveness in feature learning from unlabeled data. Regarding this success, there have been some arguments on the role that mutual information plays within the SSL framework. Some works argued for increasing mutual information between representation of augmented views. Others suggest decreasing mutual information between them, while increasing task-relevant information. We ponder upon this debate and propose to revisit the core idea of SSL within the framework of partial information decomposition (PID). Thus, with SSL under PID we propose to replace traditional mutual information with the more general concept of joint mutual information to resolve the argument. Our investigation on instantiation of SSL within the PID framework leads to upgrading the existing pipelines by considering the components of the PID in the SSL models for improved representation learning. Accordingly we propose a general pipeline that can be applied to improve existing baselines. Our pipeline focuses on extracting the unique information component under the PID to build upon lower level supervision for generic feature learning and on developing higher-level supervisory signals for task-related feature learning. In essence, this could be interpreted as a joint utilization of local and global clustering. Experiments on four baselines and four datasets show the effectiveness and generality of our approach in improving existing SSL frameworks.
GUESS: Generative Uncertainty Ensemble for Self Supervision
Dec 03, 2024Self-supervised learning (SSL) frameworks consist of pretext task, and loss function aiming to learn useful general features from unlabeled data. The basic idea of most SSL baselines revolves around enforcing the invariance to a variety of data augmentations via the loss function. However, one main issue is that, inattentive or deterministic enforcement of the invariance to any kind of data augmentation is generally not only inefficient, but also potentially detrimental to performance on the downstream tasks. In this work, we investigate the issue from the viewpoint of uncertainty in invariance representation. Uncertainty representation is fairly under-explored in the design of SSL architectures as well as loss functions. We incorporate uncertainty representation in both loss function as well as architecture design aiming for more data-dependent invariance enforcement. The former is represented in the form of data-derived uncertainty in SSL loss function resulting in a generative-discriminative loss function. The latter is achieved by feeding slightly different distorted versions of samples to the ensemble aiming for learning better and more robust representation. Specifically, building upon the recent methods that use hard and soft whitening (a.k.a redundancy reduction), we introduce a new approach GUESS, a pseudo-whitening framework, composed of controlled uncertainty injection, a new architecture, and a new loss function. We include detailed results and ablation analysis establishing GUESS as a new baseline.
Direct Coloring for Self-Supervised Enhanced Feature Decoupling
Dec 03, 2024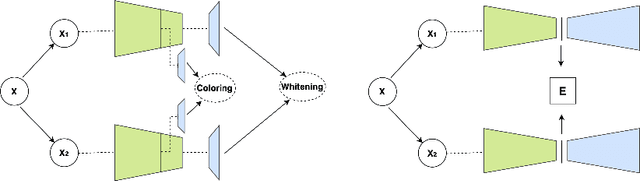
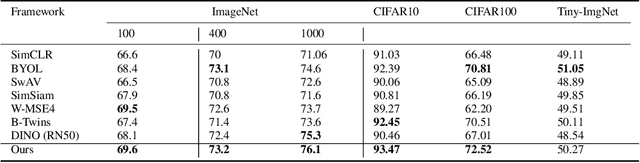
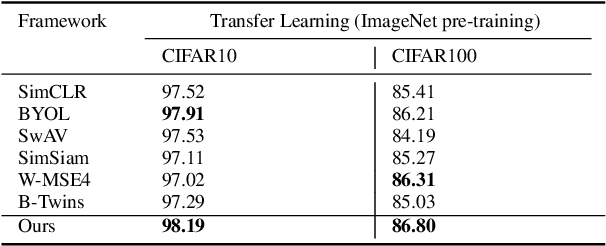
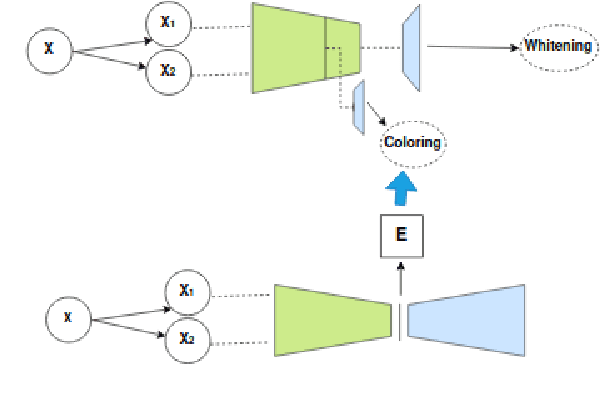
The success of self-supervised learning (SSL) has been the focus of multiple recent theoretical and empirical studies, including the role of data augmentation (in feature decoupling) as well as complete and dimensional representation collapse. While complete collapse is well-studied and addressed, dimensional collapse has only gain attention and addressed in recent years mostly using variants of redundancy reduction (aka whitening) techniques. In this paper, we further explore a complementary approach to whitening via feature decoupling for improved representation learning while avoiding representation collapse. In particular, we perform feature decoupling by early promotion of useful features via careful feature coloring. The coloring technique is developed based on a Bayesian prior of the augmented data, which is inherently encoded for feature decoupling. We show that our proposed framework is complementary to the state-of-the-art techniques, while outperforming both contrastive and recent non-contrastive methods. We also study the different effects of coloring approach to formulate it as a general complementary technique along with other baselines.
Improving Accuracy and Generalization for Efficient Visual Tracking
Nov 28, 2024



Efficient visual trackers overfit to their training distributions and lack generalization abilities, resulting in them performing well on their respective in-distribution (ID) test sets and not as well on out-of-distribution (OOD) sequences, imposing limitations to their deployment in-the-wild under constrained resources. We introduce SiamABC, a highly efficient Siamese tracker that significantly improves tracking performance, even on OOD sequences. SiamABC takes advantage of new architectural designs in the way it bridges the dynamic variability of the target, and of new losses for training. Also, it directly addresses OOD tracking generalization by including a fast backward-free dynamic test-time adaptation method that continuously adapts the model according to the dynamic visual changes of the target. Our extensive experiments suggest that SiamABC shows remarkable performance gains in OOD sets while maintaining accurate performance on the ID benchmarks. SiamABC outperforms MixFormerV2-S by 7.6\% on the OOD AVisT benchmark while being 3x faster (100 FPS) on a CPU.
FG-CXR: A Radiologist-Aligned Gaze Dataset for Enhancing Interpretability in Chest X-Ray Report Generation
Nov 23, 2024



Developing an interpretable system for generating reports in chest X-ray (CXR) analysis is becoming increasingly crucial in Computer-aided Diagnosis (CAD) systems, enabling radiologists to comprehend the decisions made by these systems. Despite the growth of diverse datasets and methods focusing on report generation, there remains a notable gap in how closely these models' generated reports align with the interpretations of real radiologists. In this study, we tackle this challenge by initially introducing Fine-Grained CXR (FG-CXR) dataset, which provides fine-grained paired information between the captions generated by radiologists and the corresponding gaze attention heatmaps for each anatomy. Unlike existing datasets that include a raw sequence of gaze alongside a report, with significant misalignment between gaze location and report content, our FG-CXR dataset offers a more grained alignment between gaze attention and diagnosis transcript. Furthermore, our analysis reveals that simply applying black-box image captioning methods to generate reports cannot adequately explain which information in CXR is utilized and how long needs to attend to accurately generate reports. Consequently, we propose a novel explainable radiologist's attention generator network (Gen-XAI) that mimics the diagnosis process of radiologists, explicitly constraining its output to closely align with both radiologist's gaze attention and transcript. Finally, we perform extensive experiments to illustrate the effectiveness of our method. Our datasets and checkpoint is available at https://github.com/UARK-AICV/FG-CXR.
TabSeq: A Framework for Deep Learning on Tabular Data via Sequential Ordering
Oct 17, 2024



Effective analysis of tabular data still poses a significant problem in deep learning, mainly because features in tabular datasets are often heterogeneous and have different levels of relevance. This work introduces TabSeq, a novel framework for the sequential ordering of features, addressing the vital necessity to optimize the learning process. Features are not always equally informative, and for certain deep learning models, their random arrangement can hinder the model's learning capacity. Finding the optimum sequence order for such features could improve the deep learning models' learning process. The novel feature ordering technique we provide in this work is based on clustering and incorporates both local ordering and global ordering. It is designed to be used with a multi-head attention mechanism in a denoising autoencoder network. Our framework uses clustering to align comparable features and improve data organization. Multi-head attention focuses on essential characteristics, whereas the denoising autoencoder highlights important aspects by rebuilding from distorted inputs. This method improves the capability to learn from tabular data while lowering redundancy. Our research, demonstrating improved performance through appropriate feature sequence rearrangement using raw antibody microarray and two other real-world biomedical datasets, validates the impact of feature ordering. These results demonstrate that feature ordering can be a viable approach to improved deep learning of tabular data.
Few-shot adaptation for morphology-independent cell instance segmentation
Feb 27, 2024



Microscopy data collections are becoming larger and more frequent. Accurate and precise quantitative analysis tools like cell instance segmentation are necessary to benefit from them. This is challenging due to the variability in the data, which requires retraining the segmentation model to maintain high accuracy on new collections. This is needed especially for segmenting cells with elongated and non-convex morphology like bacteria. We propose to reduce the amount of annotation and computing power needed for retraining the model by introducing a few-shot domain adaptation approach that requires annotating only one to five cells of the new data to process and that quickly adapts the model to maintain high accuracy. Our results show a significant boost in accuracy after adaptation to very challenging bacteria datasets.
Current Topological and Machine Learning Applications for Bias Detection in Text
Nov 22, 2023



Institutional bias can impact patient outcomes, educational attainment, and legal system navigation. Written records often reflect bias, and once bias is identified; it is possible to refer individuals for training to reduce bias. Many machine learning tools exist to explore text data and create predictive models that can search written records to identify real-time bias. However, few previous studies investigate large language model embeddings and geometric models of biased text data to understand geometry's impact on bias modeling accuracy. To overcome this issue, this study utilizes the RedditBias database to analyze textual biases. Four transformer models, including BERT and RoBERTa variants, were explored. Post-embedding, t-SNE allowed two-dimensional visualization of data. KNN classifiers differentiated bias types, with lower k-values proving more effective. Findings suggest BERT, particularly mini BERT, excels in bias classification, while multilingual models lag. The recommendation emphasizes refining monolingual models and exploring domain-specific biases.
ZEETAD: Adapting Pretrained Vision-Language Model for Zero-Shot End-to-End Temporal Action Detection
Nov 04, 2023



Temporal action detection (TAD) involves the localization and classification of action instances within untrimmed videos. While standard TAD follows fully supervised learning with closed-set setting on large training data, recent zero-shot TAD methods showcase the promising open-set setting by leveraging large-scale contrastive visual-language (ViL) pretrained models. However, existing zero-shot TAD methods have limitations on how to properly construct the strong relationship between two interdependent tasks of localization and classification and adapt ViL model to video understanding. In this work, we present ZEETAD, featuring two modules: dual-localization and zero-shot proposal classification. The former is a Transformer-based module that detects action events while selectively collecting crucial semantic embeddings for later recognition. The latter one, CLIP-based module, generates semantic embeddings from text and frame inputs for each temporal unit. Additionally, we enhance discriminative capability on unseen classes by minimally updating the frozen CLIP encoder with lightweight adapters. Extensive experiments on THUMOS14 and ActivityNet-1.3 datasets demonstrate our approach's superior performance in zero-shot TAD and effective knowledge transfer from ViL models to unseen action categories.