 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFiltering for Creativity: Adaptive Prompting for Multilingual Riddle Generation in LLMs
Aug 26, 2025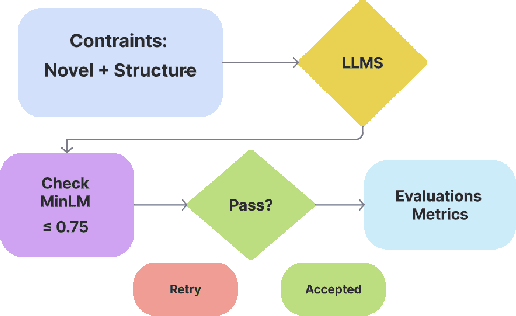
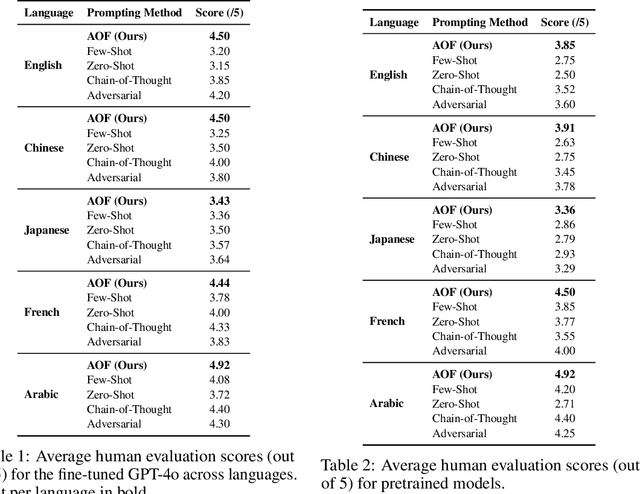
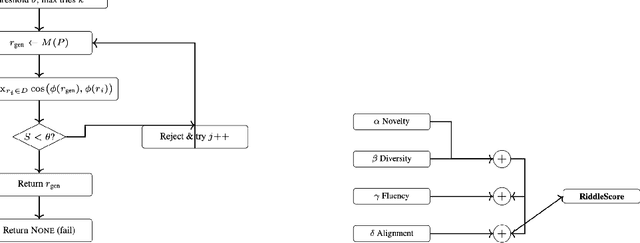
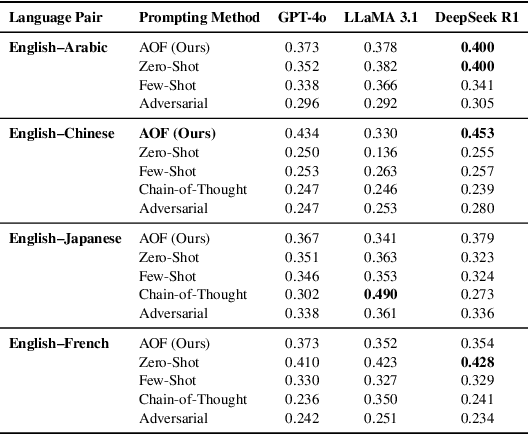
Multilingual riddle generation challenges large language models (LLMs) to balance cultural fluency with creative abstraction. Standard prompting strategies -- zero-shot, few-shot, chain-of-thought -- tend to reuse memorized riddles or perform shallow paraphrasing. We introduce Adaptive Originality Filtering (AOF), a prompting framework that filters redundant generations using cosine-based similarity rejection, while enforcing lexical novelty and cross-lingual fidelity. Evaluated across three LLMs and four language pairs, AOF-enhanced GPT-4o achieves \texttt{0.177} Self-BLEU and \texttt{0.915} Distinct-2 in Japanese, signaling improved lexical diversity and reduced redundancy compared to other prompting methods and language pairs. Our findings show that semantic rejection can guide culturally grounded, creative generation without task-specific fine-tuning.
Sentiment Reasoning for Healthcare
Jul 24, 2024


Transparency in AI decision-making is crucial in healthcare due to the severe consequences of errors, and this is important for building trust among AI and users in sentiment analysis task. Incorporating reasoning capabilities helps Large Language Models (LLMs) understand human emotions within broader contexts, handle nuanced and ambiguous language, and infer underlying sentiments that may not be explicitly stated. In this work, we introduce a new task - Sentiment Reasoning - for both speech and text modalities, along with our proposed multimodal multitask framework and dataset. Our study showed that rationale-augmented training enhances model performance in sentiment classification across both human transcript and ASR settings. Also, we found that the generated rationales typically exhibit different vocabularies compared to human-generated rationales, but maintain similar semantics. All code, data (English-translated and Vietnamese) and models are published online: https://github.com/leduckhai/MultiMed
KV Cache Compression, But What Must We Give in Return? A Comprehensive Benchmark of Long Context Capable Approaches
Jul 01, 2024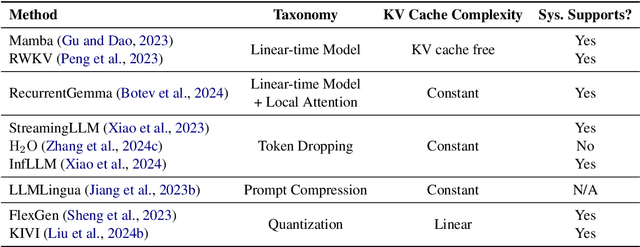
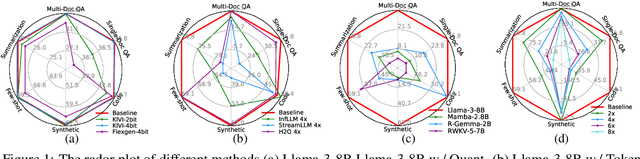
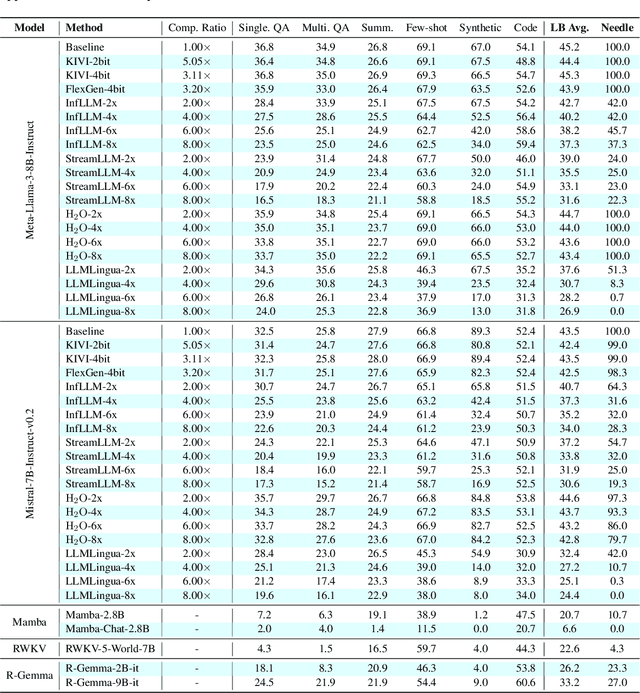
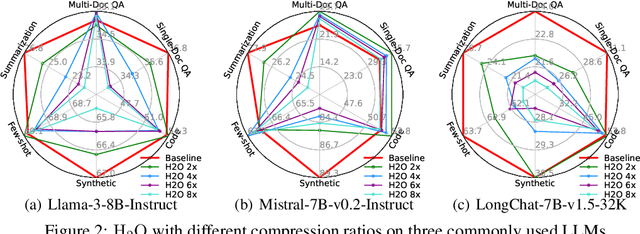
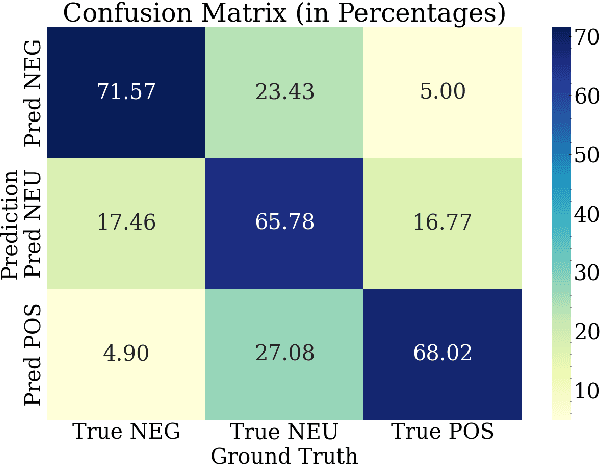
Long context capability is a crucial competency for large language models (LLMs) as it mitigates the human struggle to digest long-form texts. This capability enables complex task-solving scenarios such as book summarization, code assistance, and many more tasks that are traditionally manpower-intensive. However, transformer-based LLMs face significant challenges with long context input due to the growing size of the KV cache and the intrinsic complexity of attending to extended inputs; where multiple schools of efficiency-driven approaches -- such as KV cache quantization, token dropping, prompt compression, linear-time sequence models, and hybrid architectures -- have been proposed to produce efficient yet long context-capable models. Despite these advancements, no existing work has comprehensively benchmarked these methods in a reasonably aligned environment. In this work, we fill this gap by providing a taxonomy of current methods and evaluating 10+ state-of-the-art approaches across seven categories of long context tasks. Our work reveals numerous previously unknown phenomena and offers insights -- as well as a friendly workbench -- for the future development of long context-capable LLMs. The source code will be available at https://github.com/henryzhongsc/longctx_bench
ZEETAD: Adapting Pretrained Vision-Language Model for Zero-Shot End-to-End Temporal Action Detection
Nov 04, 2023



Temporal action detection (TAD) involves the localization and classification of action instances within untrimmed videos. While standard TAD follows fully supervised learning with closed-set setting on large training data, recent zero-shot TAD methods showcase the promising open-set setting by leveraging large-scale contrastive visual-language (ViL) pretrained models. However, existing zero-shot TAD methods have limitations on how to properly construct the strong relationship between two interdependent tasks of localization and classification and adapt ViL model to video understanding. In this work, we present ZEETAD, featuring two modules: dual-localization and zero-shot proposal classification. The former is a Transformer-based module that detects action events while selectively collecting crucial semantic embeddings for later recognition. The latter one, CLIP-based module, generates semantic embeddings from text and frame inputs for each temporal unit. Additionally, we enhance discriminative capability on unseen classes by minimally updating the frozen CLIP encoder with lightweight adapters. Extensive experiments on THUMOS14 and ActivityNet-1.3 datasets demonstrate our approach's superior performance in zero-shot TAD and effective knowledge transfer from ViL models to unseen action categories.