 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe LLM Data Auditor: A Metric-oriented Survey on Quality and Trustworthiness in Evaluating Synthetic Data
Jan 27, 2026Large Language Models (LLMs) have emerged as powerful tools for generating data across various modalities. By transforming data from a scarce resource into a controllable asset, LLMs mitigate the bottlenecks imposed by the acquisition costs of real-world data for model training, evaluation, and system iteration. However, ensuring the high quality of LLM-generated synthetic data remains a critical challenge. Existing research primarily focuses on generation methodologies, with limited direct attention to the quality of the resulting data. Furthermore, most studies are restricted to single modalities, lacking a unified perspective across different data types. To bridge this gap, we propose the \textbf{LLM Data Auditor framework}. In this framework, we first describe how LLMs are utilized to generate data across six distinct modalities. More importantly, we systematically categorize intrinsic metrics for evaluating synthetic data from two dimensions: quality and trustworthiness. This approach shifts the focus from extrinsic evaluation, which relies on downstream task performance, to the inherent properties of the data itself. Using this evaluation system, we analyze the experimental evaluations of representative generation methods for each modality and identify substantial deficiencies in current evaluation practices. Based on these findings, we offer concrete recommendations for the community to improve the evaluation of data generation. Finally, the framework outlines methodologies for the practical application of synthetic data across different modalities.
AutoL2S: Auto Long-Short Reasoning for Efficient Large Language Models
May 28, 2025The reasoning-capable large language models (LLMs) demonstrate strong performance on complex reasoning tasks but often suffer from overthinking, generating unnecessarily long chain-of-thought (CoT) reasoning paths for easy reasoning questions, thereby increasing inference cost and latency. Recent approaches attempt to address this challenge by manually deciding when to apply long or short reasoning. However, they lack the flexibility to adapt CoT length dynamically based on question complexity. In this paper, we propose Auto Long-Short Reasoning (AutoL2S), a dynamic and model-agnostic framework that enables LLMs to dynamically compress their generated reasoning path based on the complexity of the reasoning question. AutoL2S enables a learned paradigm, in which LLMs themselves can decide when longer reasoning is necessary and when shorter reasoning suffices, by training on data annotated with our proposed method, which includes both long and short CoT paths and a special <EASY> token. We then use <EASY> token to indicate when the model can skip generating lengthy CoT reasoning. This proposed annotation strategy can enhance the LLMs' ability to generate shorter CoT reasoning paths with improved quality after training. Extensive evaluation results show that AutoL2S reduces the length of reasoning generation by up to 57% without compromising performance, demonstrating the effectiveness of AutoL2S for scalable and efficient LLM reasoning.
Stop Overthinking: A Survey on Efficient Reasoning for Large Language Models
Mar 20, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities in complex tasks. Recent advancements in Large Reasoning Models (LRMs), such as OpenAI o1 and DeepSeek-R1, have further improved performance in System-2 reasoning domains like mathematics and programming by harnessing supervised fine-tuning (SFT) and reinforcement learning (RL) techniques to enhance the Chain-of-Thought (CoT) reasoning. However, while longer CoT reasoning sequences improve performance, they also introduce significant computational overhead due to verbose and redundant outputs, known as the "overthinking phenomenon". In this paper, we provide the first structured survey to systematically investigate and explore the current progress toward achieving efficient reasoning in LLMs. Overall, relying on the inherent mechanism of LLMs, we categorize existing works into several key directions: (1) model-based efficient reasoning, which considers optimizing full-length reasoning models into more concise reasoning models or directly training efficient reasoning models; (2) reasoning output-based efficient reasoning, which aims to dynamically reduce reasoning steps and length during inference; (3) input prompts-based efficient reasoning, which seeks to enhance reasoning efficiency based on input prompt properties such as difficulty or length control. Additionally, we introduce the use of efficient data for training reasoning models, explore the reasoning capabilities of small language models, and discuss evaluation methods and benchmarking.
Confident or Seek Stronger: Exploring Uncertainty-Based On-device LLM Routing From Benchmarking to Generalization
Feb 06, 2025Large language models (LLMs) are increasingly deployed and democratized on edge devices. To improve the efficiency of on-device deployment, small language models (SLMs) are often adopted due to their efficient decoding latency and reduced energy consumption. However, these SLMs often generate inaccurate responses when handling complex queries. One promising solution is uncertainty-based SLM routing, offloading high-stakes queries to stronger LLMs when resulting in low-confidence responses on SLM. This follows the principle of "If you lack confidence, seek stronger support" to enhance reliability. Relying on more powerful LLMs is yet effective but increases invocation costs. Therefore, striking a routing balance between efficiency and efficacy remains a critical challenge. Additionally, efficiently generalizing the routing strategy to new datasets remains under-explored. In this paper, we conduct a comprehensive investigation into benchmarking and generalization of uncertainty-driven routing strategies from SLMs to LLMs over 1500+ settings. Our findings highlight: First, uncertainty-correctness alignment in different uncertainty quantification (UQ) methods significantly impacts routing performance. Second, uncertainty distributions depend more on both the specific SLM and the chosen UQ method, rather than downstream data. Building on the insight, we propose a calibration data construction instruction pipeline and open-source a constructed hold-out set to enhance routing generalization on new downstream scenarios. The experimental results indicate calibration data effectively bootstraps routing performance without any new data.
Learning to Route with Confidence Tokens
Oct 17, 2024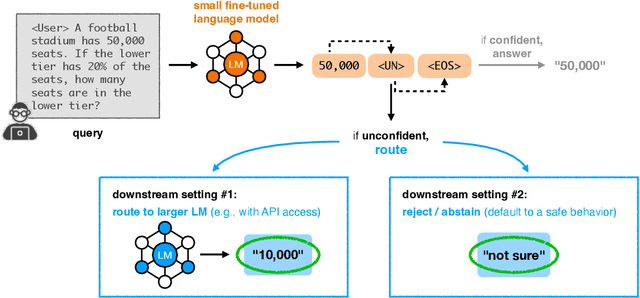

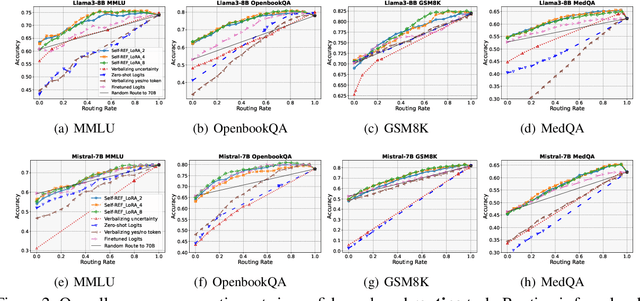
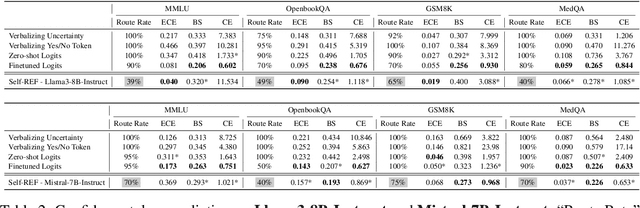
Large language models (LLMs) have demonstrated impressive performance on several tasks and are increasingly deployed in real-world applications. However, especially in high-stakes settings, it becomes vital to know when the output of an LLM may be unreliable. Depending on whether an answer is trustworthy, a system can then choose to route the question to another expert, or otherwise fall back on a safe default behavior. In this work, we study the extent to which LLMs can reliably indicate confidence in their answers, and how this notion of confidence can translate into downstream accuracy gains. We propose Self-REF, a lightweight training strategy to teach LLMs to express confidence in whether their answers are correct in a reliable manner. Self-REF introduces confidence tokens into the LLM, from which a confidence score can be extracted. Compared to conventional approaches such as verbalizing confidence and examining token probabilities, we demonstrate empirically that confidence tokens show significant improvements in downstream routing and rejection learning tasks.
Taylor Unswift: Secured Weight Release for Large Language Models via Taylor Expansion
Oct 06, 2024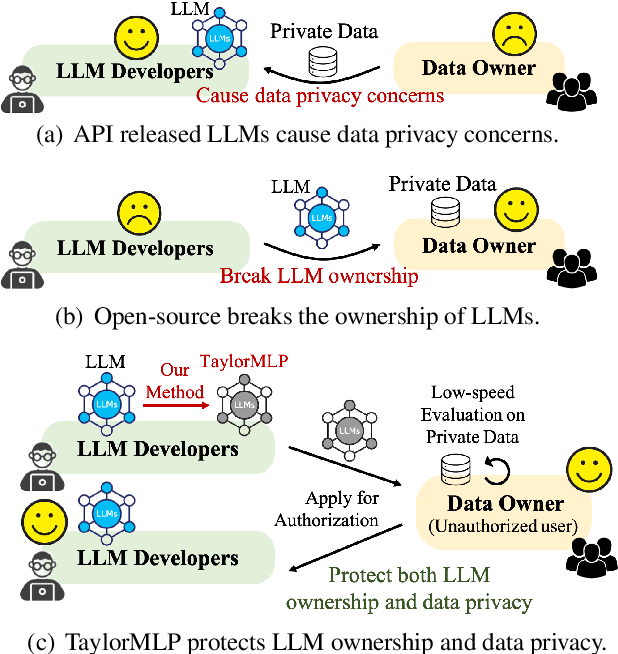
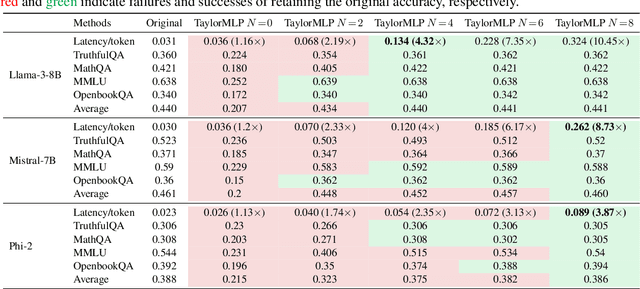
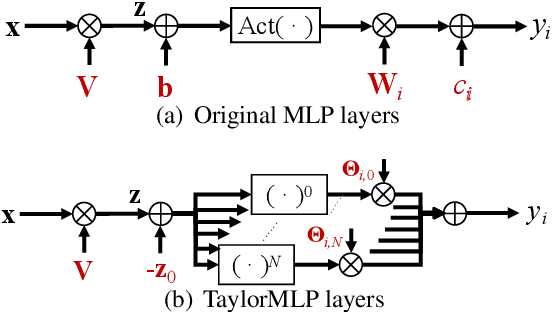

Ensuring the security of released large language models (LLMs) poses a significant dilemma, as existing mechanisms either compromise ownership rights or raise data privacy concerns. To address this dilemma, we introduce TaylorMLP to protect the ownership of released LLMs and prevent their abuse. Specifically, TaylorMLP preserves the ownership of LLMs by transforming the weights of LLMs into parameters of Taylor-series. Instead of releasing the original weights, developers can release the Taylor-series parameters with users, thereby ensuring the security of LLMs. Moreover, TaylorMLP can prevent abuse of LLMs by adjusting the generation speed. It can induce low-speed token generation for the protected LLMs by increasing the terms in the Taylor-series. This intentional delay helps LLM developers prevent potential large-scale unauthorized uses of their models. Empirical experiments across five datasets and three LLM architectures demonstrate that TaylorMLP induces over 4x increase in latency, producing the tokens precisely matched with original LLMs. Subsequent defensive experiments further confirm that TaylorMLP effectively prevents users from reconstructing the weight values based on downstream datasets.
DHP Benchmark: Are LLMs Good NLG Evaluators?
Aug 25, 2024Large Language Models (LLMs) are increasingly serving as evaluators in Natural Language Generation (NLG) tasks. However, the capabilities of LLMs in scoring NLG quality remain inadequately explored. Current studies depend on human assessments and simple metrics that fail to capture the discernment of LLMs across diverse NLG tasks. To address this gap, we propose the Discernment of Hierarchical Perturbation (DHP) benchmarking framework, which provides quantitative discernment scores for LLMs utilizing hierarchically perturbed text data and statistical tests to measure the NLG evaluation capabilities of LLMs systematically. We have re-established six evaluation datasets for this benchmark, covering four NLG tasks: Summarization, Story Completion, Question Answering, and Translation. Our comprehensive benchmarking of five major LLM series provides critical insight into their strengths and limitations as NLG evaluators.
Assessing and Enhancing Large Language Models in Rare Disease Question-answering
Aug 15, 2024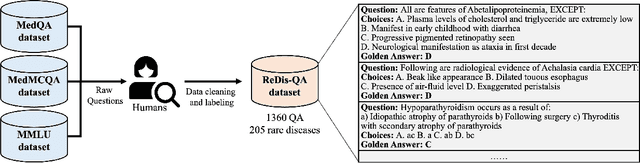

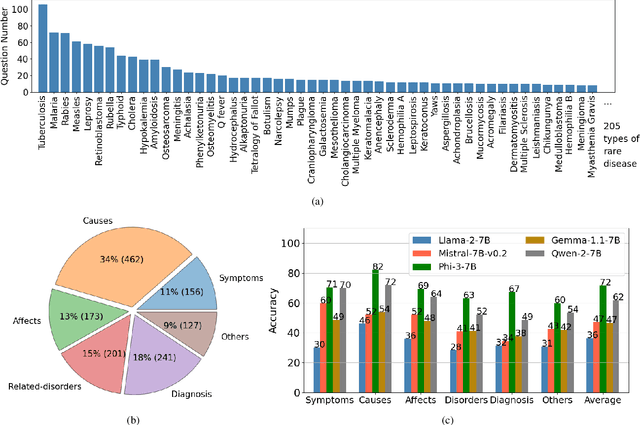
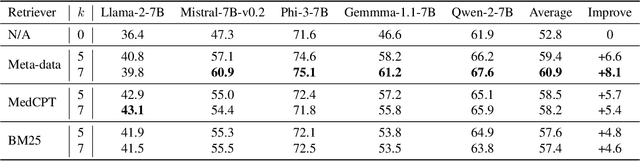
Despite the impressive capabilities of Large Language Models (LLMs) in general medical domains, questions remain about their performance in diagnosing rare diseases. To answer this question, we aim to assess the diagnostic performance of LLMs in rare diseases, and explore methods to enhance their effectiveness in this area. In this work, we introduce a rare disease question-answering (ReDis-QA) dataset to evaluate the performance of LLMs in diagnosing rare diseases. Specifically, we collected 1360 high-quality question-answer pairs within the ReDis-QA dataset, covering 205 rare diseases. Additionally, we annotated meta-data for each question, facilitating the extraction of subsets specific to any given disease and its property. Based on the ReDis-QA dataset, we benchmarked several open-source LLMs, revealing that diagnosing rare diseases remains a significant challenge for these models. To facilitate retrieval augmentation generation for rare disease diagnosis, we collect the first rare diseases corpus (ReCOP), sourced from the National Organization for Rare Disorders (NORD) database. Specifically, we split the report of each rare disease into multiple chunks, each representing a different property of the disease, including their overview, symptoms, causes, effects, related disorders, diagnosis, and standard therapies. This structure ensures that the information within each chunk aligns consistently with a question. Experiment results demonstrate that ReCOP can effectively improve the accuracy of LLMs on the ReDis-QA dataset by an average of 8%. Moreover, it significantly guides LLMs to generate trustworthy answers and explanations that can be traced back to existing literature.
KV Cache Compression, But What Must We Give in Return? A Comprehensive Benchmark of Long Context Capable Approaches
Jul 01, 2024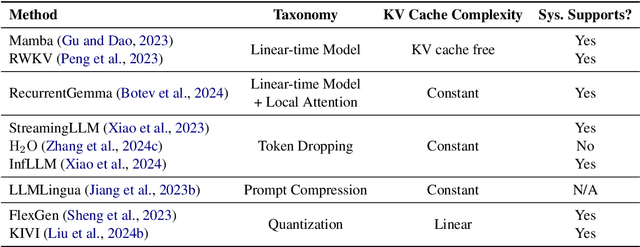
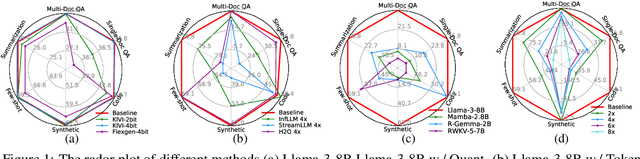
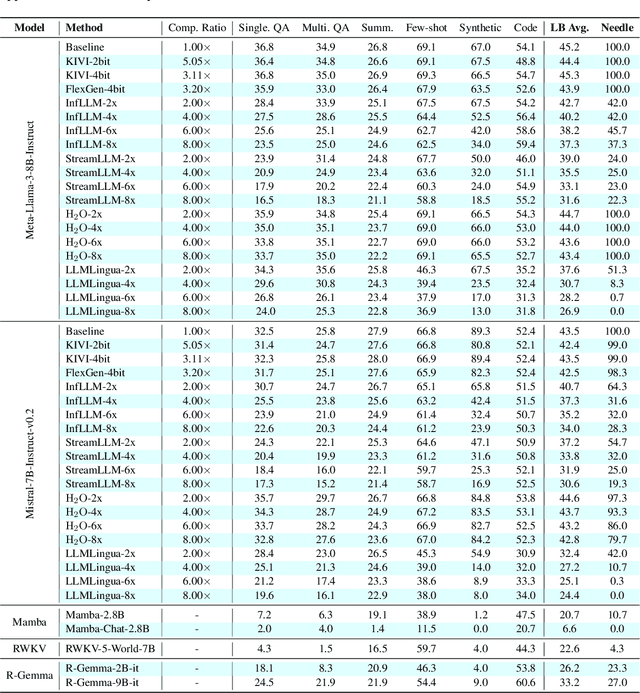
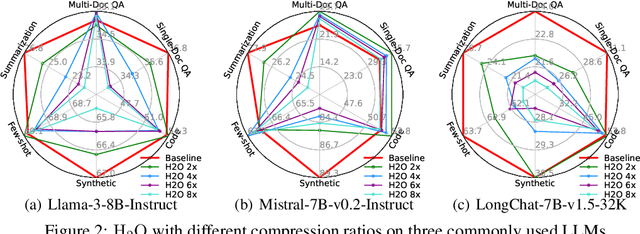
Long context capability is a crucial competency for large language models (LLMs) as it mitigates the human struggle to digest long-form texts. This capability enables complex task-solving scenarios such as book summarization, code assistance, and many more tasks that are traditionally manpower-intensive. However, transformer-based LLMs face significant challenges with long context input due to the growing size of the KV cache and the intrinsic complexity of attending to extended inputs; where multiple schools of efficiency-driven approaches -- such as KV cache quantization, token dropping, prompt compression, linear-time sequence models, and hybrid architectures -- have been proposed to produce efficient yet long context-capable models. Despite these advancements, no existing work has comprehensively benchmarked these methods in a reasonably aligned environment. In this work, we fill this gap by providing a taxonomy of current methods and evaluating 10+ state-of-the-art approaches across seven categories of long context tasks. Our work reveals numerous previously unknown phenomena and offers insights -- as well as a friendly workbench -- for the future development of long context-capable LLMs. The source code will be available at https://github.com/henryzhongsc/longctx_bench
Understanding Different Design Choices in Training Large Time Series Models
Jun 20, 2024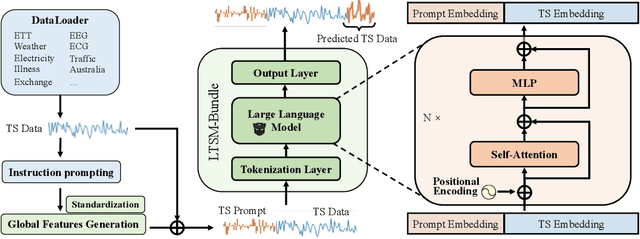
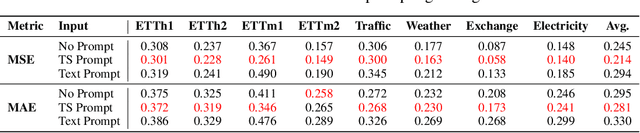

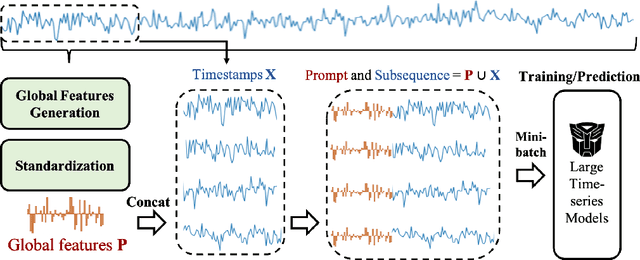
Inspired by Large Language Models (LLMs), Time Series Forecasting (TSF), a long-standing task in time series analysis, is undergoing a transition towards Large Time Series Models (LTSMs), aiming to train universal transformer-based models for TSF. However, training LTSMs on heterogeneous time series data poses unique challenges, including diverse frequencies, dimensions, and patterns across datasets. Recent endeavors have studied and evaluated various design choices aimed at enhancing LTSM training and generalization capabilities, spanning pre-processing techniques, model configurations, and dataset configurations. In this work, we comprehensively analyze these design choices and aim to identify the best practices for training LTSM. Moreover, we propose \emph{time series prompt}, a novel statistical prompting strategy tailored to time series data. Furthermore, based on the observations in our analysis, we introduce \texttt{LTSM-bundle}, which bundles the best design choices we have identified. Empirical results demonstrate that \texttt{LTSM-bundle} achieves superior zero-shot and few-shot performances compared to state-of-the-art LSTMs and traditional TSF methods on benchmark datasets.