 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Methodologies for Agentic Evaluations Across Domains: Leakage of Sensitive Information, Fraud and Cybersecurity Threats
Jan 22, 2026The rapid rise of autonomous AI systems and advancements in agent capabilities are introducing new risks due to reduced oversight of real-world interactions. Yet agent testing remains nascent and is still a developing science. As AI agents begin to be deployed globally, it is important that they handle different languages and cultures accurately and securely. To address this, participants from The International Network for Advanced AI Measurement, Evaluation and Science, including representatives from Singapore, Japan, Australia, Canada, the European Commission, France, Kenya, South Korea, and the United Kingdom have come together to align approaches to agentic evaluations. This is the third exercise, building on insights from two earlier joint testing exercises conducted by the Network in November 2024 and February 2025. The objective is to further refine best practices for testing advanced AI systems. The exercise was split into two strands: (1) common risks, including leakage of sensitive information and fraud, led by Singapore AISI; and (2) cybersecurity, led by UK AISI. A mix of open and closed-weight models were evaluated against tasks from various public agentic benchmarks. Given the nascency of agentic testing, our primary focus was on understanding methodological issues in conducting such tests, rather than examining test results or model capabilities. This collaboration marks an important step forward as participants work together to advance the science of agentic evaluations.
Machine Learning for Health symposium 2024 -- Findings track
Mar 02, 2025A collection of the accepted Findings papers that were presented at the 4th Machine Learning for Health symposium (ML4H 2024), which was held on December 15-16, 2024, in Vancouver, BC, Canada. ML4H 2024 invited high-quality submissions describing innovative research in a variety of health-related disciplines including healthcare, biomedicine, and public health. Works could be submitted to either the archival Proceedings track, or the non-archival Findings track. The Proceedings track targeted mature, cohesive works with technical sophistication and high-impact relevance to health. The Findings track promoted works that would spark new insights, collaborations, and discussions at ML4H. Both tracks were given the opportunity to share their work through the in-person poster session. All the manuscripts submitted to ML4H Symposium underwent a double-blind peer-review process.
Learning to Route with Confidence Tokens
Oct 17, 2024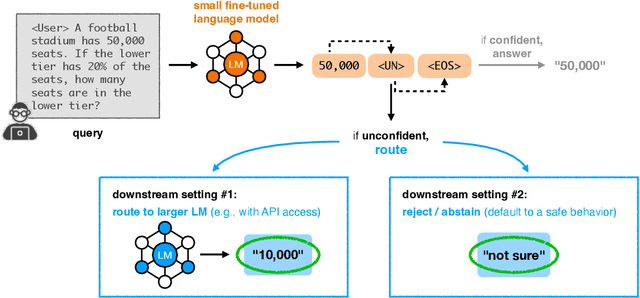

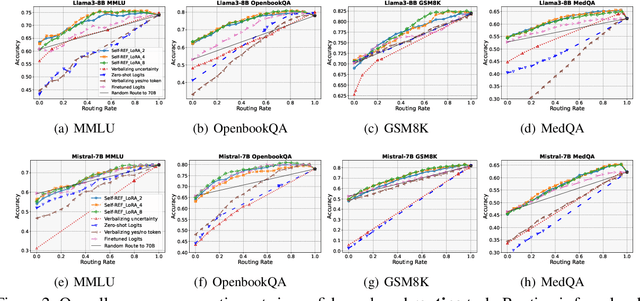
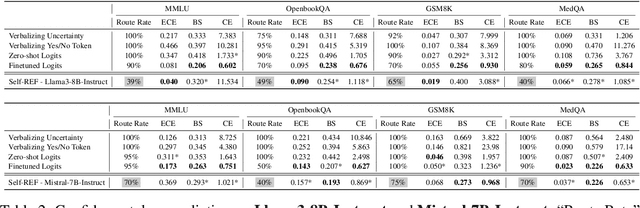
Large language models (LLMs) have demonstrated impressive performance on several tasks and are increasingly deployed in real-world applications. However, especially in high-stakes settings, it becomes vital to know when the output of an LLM may be unreliable. Depending on whether an answer is trustworthy, a system can then choose to route the question to another expert, or otherwise fall back on a safe default behavior. In this work, we study the extent to which LLMs can reliably indicate confidence in their answers, and how this notion of confidence can translate into downstream accuracy gains. We propose Self-REF, a lightweight training strategy to teach LLMs to express confidence in whether their answers are correct in a reliable manner. Self-REF introduces confidence tokens into the LLM, from which a confidence score can be extracted. Compared to conventional approaches such as verbalizing confidence and examining token probabilities, we demonstrate empirically that confidence tokens show significant improvements in downstream routing and rejection learning tasks.
Recent Advances, Applications, and Open Challenges in Machine Learning for Health: Reflections from Research Roundtables at ML4H 2023 Symposium
Mar 03, 2024The third ML4H symposium was held in person on December 10, 2023, in New Orleans, Louisiana, USA. The symposium included research roundtable sessions to foster discussions between participants and senior researchers on timely and relevant topics for the \ac{ML4H} community. Encouraged by the successful virtual roundtables in the previous year, we organized eleven in-person roundtables and four virtual roundtables at ML4H 2022. The organization of the research roundtables at the conference involved 17 Senior Chairs and 19 Junior Chairs across 11 tables. Each roundtable session included invited senior chairs (with substantial experience in the field), junior chairs (responsible for facilitating the discussion), and attendees from diverse backgrounds with interest in the session's topic. Herein we detail the organization process and compile takeaways from these roundtable discussions, including recent advances, applications, and open challenges for each topic. We conclude with a summary and lessons learned across all roundtables. This document serves as a comprehensive review paper, summarizing the recent advancements in machine learning for healthcare as contributed by foremost researchers in the field.
REACT: Two Datasets for Analyzing Both Human Reactions and Evaluative Feedback to Robots Over Time
Jan 31, 2024


Recent work in Human-Robot Interaction (HRI) has shown that robots can leverage implicit communicative signals from users to understand how they are being perceived during interactions. For example, these signals can be gaze patterns, facial expressions, or body motions that reflect internal human states. To facilitate future research in this direction, we contribute the REACT database, a collection of two datasets of human-robot interactions that display users' natural reactions to robots during a collaborative game and a photography scenario. Further, we analyze the datasets to show that interaction history is an important factor that can influence human reactions to robots. As a result, we believe that future models for interpreting implicit feedback in HRI should explicitly account for this history. REACT opens up doors to this possibility in the future.
MoCo-Transfer: Investigating out-of-distribution contrastive learning for limited-data domains
Nov 15, 2023Medical imaging data is often siloed within hospitals, limiting the amount of data available for specialized model development. With limited in-domain data, one might hope to leverage larger datasets from related domains. In this paper, we analyze the benefit of transferring self-supervised contrastive representations from moment contrast (MoCo) pretraining on out-of-distribution data to settings with limited data. We consider two X-ray datasets which image different parts of the body, and compare transferring from each other to transferring from ImageNet. We find that depending on quantity of labeled and unlabeled data, contrastive pretraining on larger out-of-distribution datasets can perform nearly as well or better than MoCo pretraining in-domain, and pretraining on related domains leads to higher performance than if one were to use the ImageNet pretrained weights. Finally, we provide a preliminary way of quantifying similarity between datasets.
Business Metric-Aware Forecasting for Inventory Management
Aug 24, 2023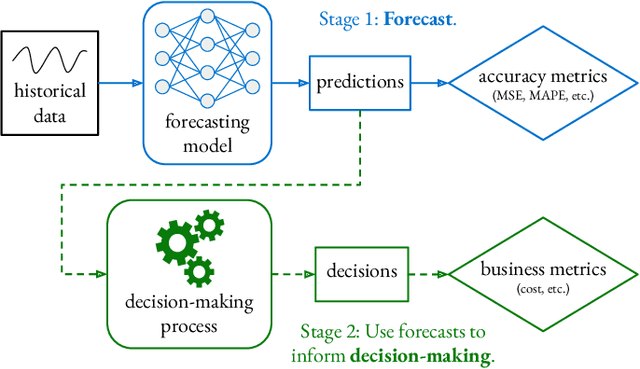
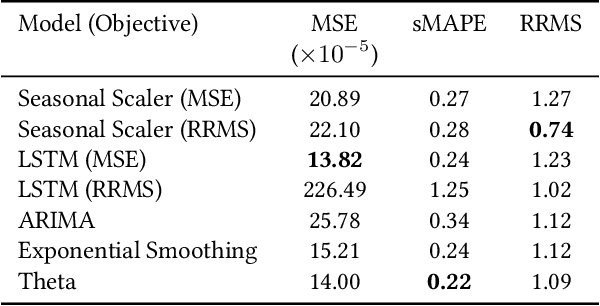
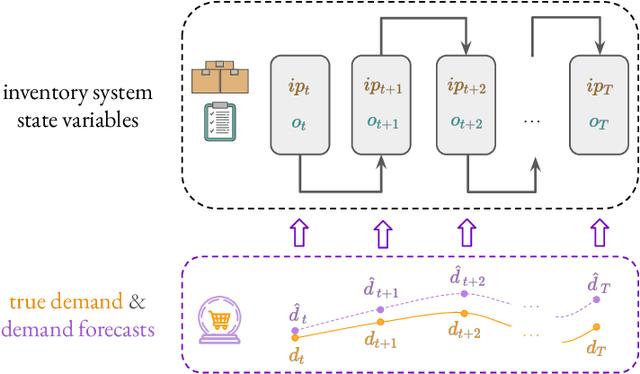
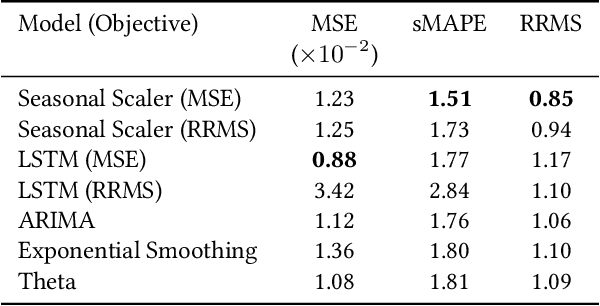
Time-series forecasts play a critical role in business planning. However, forecasters typically optimize objectives that are agnostic to downstream business goals and thus can produce forecasts misaligned with business preferences. In this work, we demonstrate that optimization of conventional forecasting metrics can often lead to sub-optimal downstream business performance. Focusing on the inventory management setting, we derive an efficient procedure for computing and optimizing proxies of common downstream business metrics in an end-to-end differentiable manner. We explore a wide range of plausible cost trade-off scenarios, and empirically demonstrate that end-to-end optimization often outperforms optimization of standard business-agnostic forecasting metrics (by up to 45.7% for a simple scaling model, and up to 54.0% for an LSTM encoder-decoder model). Finally, we discuss how our findings could benefit other business contexts.
Evaluating Model Performance in Medical Datasets Over Time
May 22, 2023Machine learning (ML) models deployed in healthcare systems must face data drawn from continually evolving environments. However, researchers proposing such models typically evaluate them in a time-agnostic manner, splitting datasets according to patients sampled randomly throughout the entire study time period. This work proposes the Evaluation on Medical Datasets Over Time (EMDOT) framework, which evaluates the performance of a model class across time. Inspired by the concept of backtesting, EMDOT simulates possible training procedures that practitioners might have been able to execute at each point in time and evaluates the resulting models on all future time points. Evaluating both linear and more complex models on six distinct medical data sources (tabular and imaging), we show how depending on the dataset, using all historical data may be ideal in many cases, whereas using a window of the most recent data could be advantageous in others. In datasets where models suffer from sudden degradations in performance, we investigate plausible explanations for these shocks. We release the EMDOT package to help facilitate further works in deployment-oriented evaluation over time.
Model Evaluation in Medical Datasets Over Time
Nov 14, 2022Machine learning models deployed in healthcare systems face data drawn from continually evolving environments. However, researchers proposing such models typically evaluate them in a time-agnostic manner, with train and test splits sampling patients throughout the entire study period. We introduce the Evaluation on Medical Datasets Over Time (EMDOT) framework and Python package, which evaluates the performance of a model class over time. Across five medical datasets and a variety of models, we compare two training strategies: (1) using all historical data, and (2) using a window of the most recent data. We note changes in performance over time, and identify possible explanations for these shocks.
Domain Adaptation under Missingness Shift
Nov 03, 2022Rates of missing data often depend on record-keeping policies and thus may change across times and locations, even when the underlying features are comparatively stable. In this paper, we introduce the problem of Domain Adaptation under Missingness Shift (DAMS). Here, (labeled) source data and (unlabeled) target data would be exchangeable but for different missing data mechanisms. We show that when missing data indicators are available, DAMS can reduce to covariate shift. Focusing on the setting where missing data indicators are absent, we establish the following theoretical results for underreporting completely at random: (i) covariate shift is violated (adaptation is required); (ii) the optimal source predictor can perform worse on the target domain than a constant one; (iii) the optimal target predictor can be identified, even when the missingness rates themselves are not; and (iv) for linear models, a simple analytic adjustment yields consistent estimates of the optimal target parameters. In experiments on synthetic and semi-synthetic data, we demonstrate the promise of our methods when assumptions hold. Finally, we discuss a rich family of future extensions.