 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSummarize Before You Speak with ARACH: A Training-Free Inference-Time Plug-In for Enhancing LLMs via Global Attention Reallocation
Mar 10, 2026Large language models (LLMs) achieve remarkable performance, yet further gains often require costly training. This has motivated growing interest in post-training techniques-especially training-free approaches that improve models at inference time without updating weights. Most training-free methods treat the model as a black box and improve outputs via input/output-level interventions, such as prompt design and test-time scaling through repeated sampling, reranking/verification, or search. In contrast, they rarely offer a plug-and-play mechanism to intervene in a model's internal computation. We propose ARACH(Attention Reallocation via an Adaptive Context Hub), a training-free inference-time plug-in that augments LLMs with an adaptive context hub to aggregate context and reallocate attention. Extensive experiments across multiple language modeling tasks show consistent improvements with modest inference overhead and no parameter updates. Attention analyses further suggest that ARACH mitigates the attention sink phenomenon. These results indicate that engineering a model's internal computation offers a distinct inference-time strategy, fundamentally different from both prompt-based test-time methods and training-based post-training approaches.
CarbonChat: Large Language Model-Based Corporate Carbon Emission Analysis and Climate Knowledge Q&A System
Jan 03, 2025


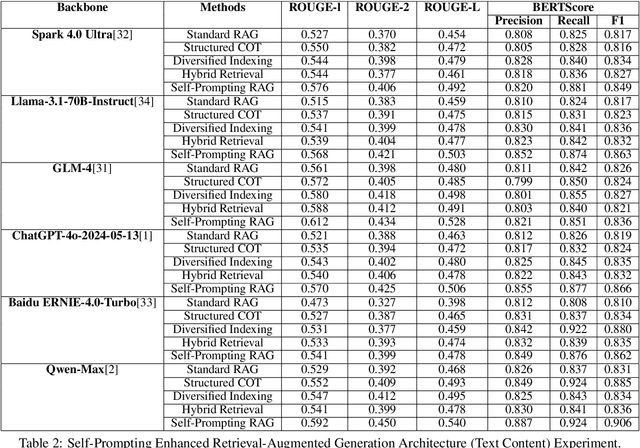
As the impact of global climate change intensifies, corporate carbon emissions have become a focal point of global attention. In response to issues such as the lag in climate change knowledge updates within large language models, the lack of specialization and accuracy in traditional augmented generation architectures for complex problems, and the high cost and time consumption of sustainability report analysis, this paper proposes CarbonChat: Large Language Model-based corporate carbon emission analysis and climate knowledge Q&A system, aimed at achieving precise carbon emission analysis and policy understanding.First, a diversified index module construction method is proposed to handle the segmentation of rule-based and long-text documents, as well as the extraction of structured data, thereby optimizing the parsing of key information.Second, an enhanced self-prompt retrieval-augmented generation architecture is designed, integrating intent recognition, structured reasoning chains, hybrid retrieval, and Text2SQL, improving the efficiency of semantic understanding and query conversion.Next, based on the greenhouse gas accounting framework, 14 dimensions are established for carbon emission analysis, enabling report summarization, relevance evaluation, and customized responses.Finally, through a multi-layer chunking mechanism, timestamps, and hallucination detection features, the accuracy and verifiability of the analysis results are ensured, reducing hallucination rates and enhancing the precision of the responses.
Business Metric-Aware Forecasting for Inventory Management
Aug 24, 2023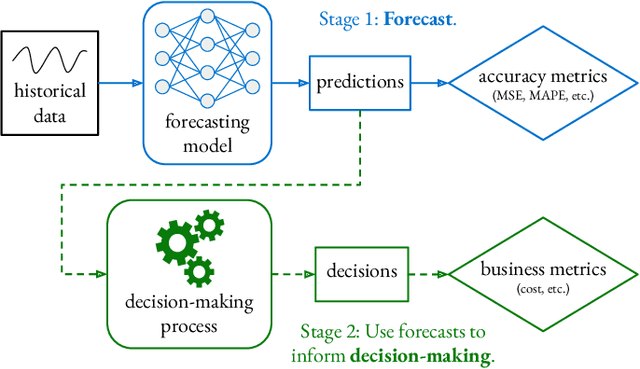
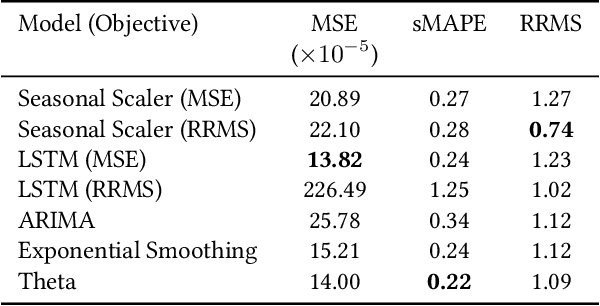
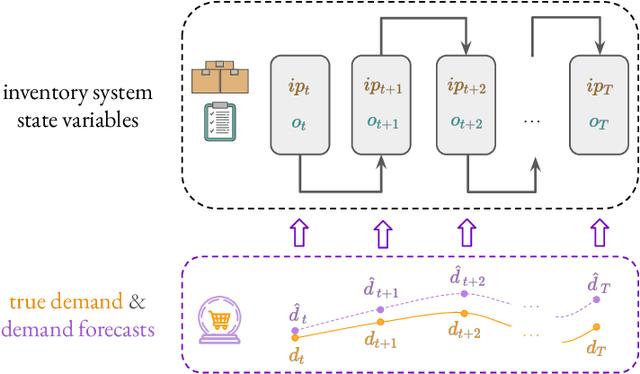
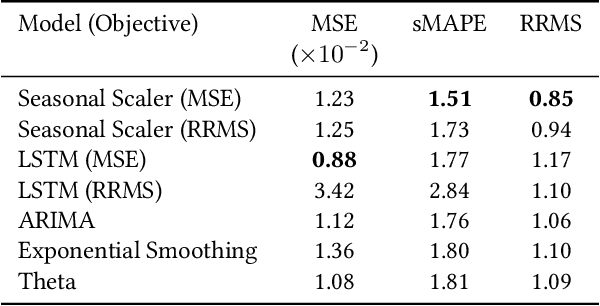
Time-series forecasts play a critical role in business planning. However, forecasters typically optimize objectives that are agnostic to downstream business goals and thus can produce forecasts misaligned with business preferences. In this work, we demonstrate that optimization of conventional forecasting metrics can often lead to sub-optimal downstream business performance. Focusing on the inventory management setting, we derive an efficient procedure for computing and optimizing proxies of common downstream business metrics in an end-to-end differentiable manner. We explore a wide range of plausible cost trade-off scenarios, and empirically demonstrate that end-to-end optimization often outperforms optimization of standard business-agnostic forecasting metrics (by up to 45.7% for a simple scaling model, and up to 54.0% for an LSTM encoder-decoder model). Finally, we discuss how our findings could benefit other business contexts.
Reinforcement Learning Driven Heuristic Optimization
Jun 16, 2019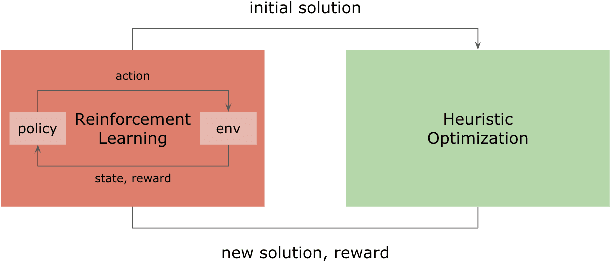


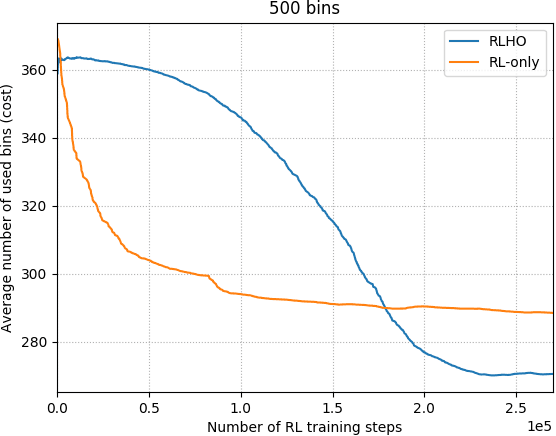
Heuristic algorithms such as simulated annealing, Concorde, and METIS are effective and widely used approaches to find solutions to combinatorial optimization problems. However, they are limited by the high sample complexity required to reach a reasonable solution from a cold-start. In this paper, we introduce a novel framework to generate better initial solutions for heuristic algorithms using reinforcement learning (RL), named RLHO. We augment the ability of heuristic algorithms to greedily improve upon an existing initial solution generated by RL, and demonstrate novel results where RL is able to leverage the performance of heuristics as a learning signal to generate better initialization. We apply this framework to Proximal Policy Optimization (PPO) and Simulated Annealing (SA). We conduct a series of experiments on the well-known NP-complete bin packing problem, and show that the RLHO method outperforms our baselines. We show that on the bin packing problem, RL can learn to help heuristics perform even better, allowing us to combine the best parts of both approaches.