 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study on Reinforcement Learning for Reasoning-Search Interleaved LLM Agents
May 21, 2025



Reinforcement learning (RL) has demonstrated strong potential in training large language models (LLMs) capable of complex reasoning for real-world problem solving. More recently, RL has been leveraged to create sophisticated LLM-based search agents that adeptly combine reasoning with search engine use. While the use of RL for training search agents is promising, the optimal design of such agents remains not fully understood. In particular, key factors -- such as (1) reward formulation, (2) the choice and characteristics of the underlying LLM, and (3) the role of the search engine in the RL process -- require further investigation. In this work, we conduct comprehensive empirical studies to systematically investigate these and offer actionable insights. We highlight several key findings: format rewards are effective in improving final performance, whereas intermediate retrieval rewards have limited impact; the scale and initialization of the LLM (general-purpose vs. reasoning-specialized) significantly influence RL outcomes; and the choice of search engine plays a critical role in shaping RL training dynamics and the robustness of the trained agent during inference. These establish important guidelines for successfully building and deploying LLM-based search agents in real-world applications. Code is available at https://github.com/PeterGriffinJin/Search-R1.
LLM Alignment as Retriever Optimization: An Information Retrieval Perspective
Feb 06, 2025



Large Language Models (LLMs) have revolutionized artificial intelligence with capabilities in reasoning, coding, and communication, driving innovation across industries. Their true potential depends on effective alignment to ensure correct, trustworthy and ethical behavior, addressing challenges like misinformation, hallucinations, bias and misuse. While existing Reinforcement Learning (RL)-based alignment methods are notoriously complex, direct optimization approaches offer a simpler alternative. In this work, we introduce a novel direct optimization approach for LLM alignment by drawing on established Information Retrieval (IR) principles. We present a systematic framework that bridges LLM alignment and IR methodologies, mapping LLM generation and reward models to IR's retriever-reranker paradigm. Building on this foundation, we propose LLM Alignment as Retriever Preference Optimization (LarPO), a new alignment method that enhances overall alignment quality. Extensive experiments validate LarPO's effectiveness with 38.9 % and 13.7 % averaged improvement on AlpacaEval2 and MixEval-Hard respectively. Our work opens new avenues for advancing LLM alignment by integrating IR foundations, offering a promising direction for future research.
Long-Context LLMs Meet RAG: Overcoming Challenges for Long Inputs in RAG
Oct 08, 2024



Retrieval-augmented generation (RAG) empowers large language models (LLMs) to utilize external knowledge sources. The increasing capacity of LLMs to process longer input sequences opens up avenues for providing more retrieved information, to potentially enhance the quality of generated outputs. It is plausible to assume that a larger retrieval set would contain more relevant information (higher recall), that might result in improved performance. However, our empirical findings demonstrate that for many long-context LLMs, the quality of generated output initially improves first, but then subsequently declines as the number of retrieved passages increases. This paper investigates this phenomenon, identifying the detrimental impact of retrieved "hard negatives" as a key contributor. To mitigate this and enhance the robustness of long-context LLM-based RAG, we propose both training-free and training-based approaches. We first showcase the effectiveness of retrieval reordering as a simple yet powerful training-free optimization. Furthermore, we explore training-based methods, specifically RAG-specific implicit LLM fine-tuning and RAG-oriented fine-tuning with intermediate reasoning, demonstrating their capacity for substantial performance gains. Finally, we conduct a systematic analysis of design choices for these training-based methods, including data distribution, retriever selection, and training context length.
CHASE-SQL: Multi-Path Reasoning and Preference Optimized Candidate Selection in Text-to-SQL
Oct 02, 2024



In tackling the challenges of large language model (LLM) performance for Text-to-SQL tasks, we introduce CHASE-SQL, a new framework that employs innovative strategies, using test-time compute in multi-agent modeling to improve candidate generation and selection. CHASE-SQL leverages LLMs' intrinsic knowledge to generate diverse and high-quality SQL candidates using different LLM generators with: (1) a divide-and-conquer method that decomposes complex queries into manageable sub-queries in a single LLM call; (2) chain-of-thought reasoning based on query execution plans, reflecting the steps a database engine takes during execution; and (3) a unique instance-aware synthetic example generation technique, which offers specific few-shot demonstrations tailored to test questions.To identify the best candidate, a selection agent is employed to rank the candidates through pairwise comparisons with a fine-tuned binary-candidates selection LLM. This selection approach has been demonstrated to be more robust over alternatives. The proposed generators-selector framework not only enhances the quality and diversity of SQL queries but also outperforms previous methods. Overall, our proposed CHASE-SQL achieves the state-of-the-art execution accuracy of 73.0% and 73.01% on the test set and development set of the notable BIRD Text-to-SQL dataset benchmark, rendering CHASE-SQL the top submission of the leaderboard (at the time of paper submission).
SQL-GEN: Bridging the Dialect Gap for Text-to-SQL Via Synthetic Data And Model Merging
Aug 22, 2024



Text-to-SQL systems, which convert natural language queries into SQL commands, have seen significant progress primarily for the SQLite dialect. However, adapting these systems to other SQL dialects like BigQuery and PostgreSQL remains a challenge due to the diversity in SQL syntax and functions. We introduce SQL-GEN, a framework for generating high-quality dialect-specific synthetic data guided by dialect-specific tutorials, and demonstrate its effectiveness in creating training datasets for multiple dialects. Our approach significantly improves performance, by up to 20\%, over previous methods and reduces the gap with large-scale human-annotated datasets. Moreover, combining our synthetic data with human-annotated data provides additional performance boosts of 3.3\% to 5.6\%. We also introduce a novel Mixture of Experts (MoE) initialization method that integrates dialect-specific models into a unified system by merging self-attention layers and initializing the gates with dialect-specific keywords, further enhancing performance across different SQL dialects.
CROME: Cross-Modal Adapters for Efficient Multimodal LLM
Aug 13, 2024Multimodal Large Language Models (MLLMs) demonstrate remarkable image-language capabilities, but their widespread use faces challenges in cost-effective training and adaptation. Existing approaches often necessitate expensive language model retraining and limited adaptability. Additionally, the current focus on zero-shot performance improvements offers insufficient guidance for task-specific tuning. We propose CROME, an efficient vision-language instruction tuning framework. It features a novel gated cross-modal adapter that effectively combines visual and textual representations prior to input into a frozen LLM. This lightweight adapter, trained with minimal parameters, enables efficient cross-modal understanding. Notably, CROME demonstrates superior zero-shot performance on standard visual question answering and instruction-following benchmarks. Moreover, it yields fine-tuning with exceptional parameter efficiency, competing with task-specific specialist state-of-the-art methods. CROME demonstrates the potential of pre-LM alignment for building scalable, adaptable, and parameter-efficient multimodal models.
BRIGHT: A Realistic and Challenging Benchmark for Reasoning-Intensive Retrieval
Jul 16, 2024



Existing retrieval benchmarks primarily consist of information-seeking queries (e.g., aggregated questions from search engines) where keyword or semantic-based retrieval is usually sufficient. However, many complex real-world queries require in-depth reasoning to identify relevant documents that go beyond surface form matching. For example, finding documentation for a coding question requires understanding the logic and syntax of the functions involved. To better benchmark retrieval on such challenging queries, we introduce BRIGHT, the first text retrieval benchmark that requires intensive reasoning to retrieve relevant documents. BRIGHT is constructed from the 1,398 real-world queries collected from diverse domains (such as economics, psychology, robotics, software engineering, earth sciences, etc.), sourced from naturally occurring or carefully curated human data. Extensive evaluation reveals that even state-of-the-art retrieval models perform poorly on BRIGHT. The leading model on the MTEB leaderboard [38 ], which achieves a score of 59.0 nDCG@10,2 produces a score of nDCG@10 of 18.0 on BRIGHT. We further demonstrate that augmenting queries with Chain-of-Thought reasoning generated by large language models (LLMs) improves performance by up to 12.2 points. Moreover, BRIGHT is robust against data leakage during pretraining of the benchmarked models as we validate by showing similar performance even when documents from the benchmark are included in the training data. We believe that BRIGHT paves the way for future research on retrieval systems in more realistic and challenging settings. Our code and data are available at https://brightbenchmark.github.io.
Teach Better or Show Smarter? On Instructions and Exemplars in Automatic Prompt Optimization
Jun 22, 2024



Large language models have demonstrated remarkable capabilities, but their performance is heavily reliant on effective prompt engineering. Automatic prompt optimization (APO) methods are designed to automate this and can be broadly categorized into those targeting instructions (instruction optimization, IO) vs. those targeting exemplars (exemplar selection, ES). Despite their shared objective, these have evolved rather independently, with IO recently receiving more research attention. This paper seeks to bridge this gap by comprehensively comparing the performance of representative IO and ES techniques, both isolation and combination, on a diverse set of challenging tasks. Our findings reveal that intelligently reusing model-generated input-output pairs obtained from evaluating prompts on the validation set as exemplars consistently improves performance over IO methods but is currently under-investigated. We also find that despite the recent focus on IO, how we select exemplars can outweigh how we optimize instructions, with ES strategies as simple as random search outperforming state-of-the-art IO methods with seed instructions without any optimization. Moreover, we observe synergy between ES and IO, with optimal combinations surpassing individual contributions. We conclude that studying exemplar selection as a standalone method and its optimal combination with instruction optimization remains a crucial aspect of APO and deserves greater consideration in future research, even in the era of highly capable instruction-following models.
PAITS: Pretraining and Augmentation for Irregularly-Sampled Time Series
Aug 25, 2023



Real-world time series data that commonly reflect sequential human behavior are often uniquely irregularly sampled and sparse, with highly nonuniform sampling over time and entities. Yet, commonly-used pretraining and augmentation methods for time series are not specifically designed for such scenarios. In this paper, we present PAITS (Pretraining and Augmentation for Irregularly-sampled Time Series), a framework for identifying suitable pretraining strategies for sparse and irregularly sampled time series datasets. PAITS leverages a novel combination of NLP-inspired pretraining tasks and augmentations, and a random search to identify an effective strategy for a given dataset. We demonstrate that different datasets benefit from different pretraining choices. Compared with prior methods, our approach is better able to consistently improve pretraining across multiple datasets and domains. Our code is available at \url{https://github.com/google-research/google-research/tree/master/irregular_timeseries_pretraining}.
Business Metric-Aware Forecasting for Inventory Management
Aug 24, 2023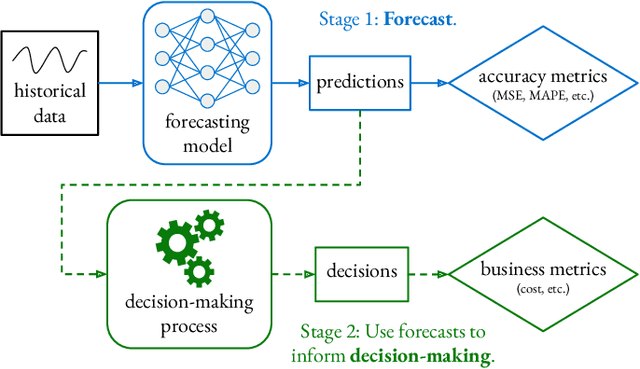
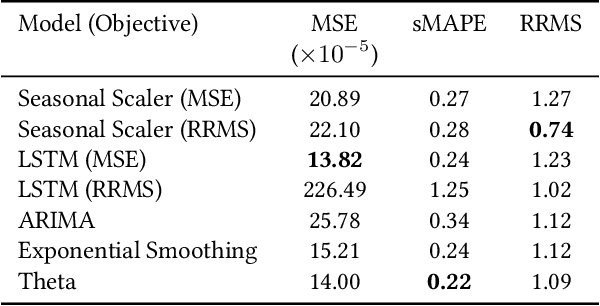
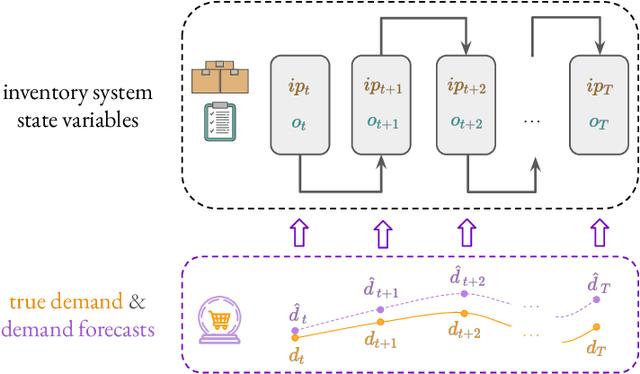
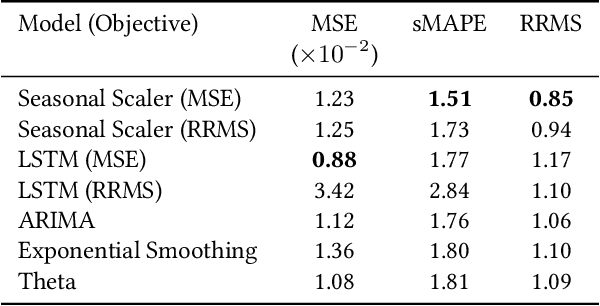
Time-series forecasts play a critical role in business planning. However, forecasters typically optimize objectives that are agnostic to downstream business goals and thus can produce forecasts misaligned with business preferences. In this work, we demonstrate that optimization of conventional forecasting metrics can often lead to sub-optimal downstream business performance. Focusing on the inventory management setting, we derive an efficient procedure for computing and optimizing proxies of common downstream business metrics in an end-to-end differentiable manner. We explore a wide range of plausible cost trade-off scenarios, and empirically demonstrate that end-to-end optimization often outperforms optimization of standard business-agnostic forecasting metrics (by up to 45.7% for a simple scaling model, and up to 54.0% for an LSTM encoder-decoder model). Finally, we discuss how our findings could benefit other business contexts.