 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSQLPrompt: In-Context Text-to-SQL with Minimal Labeled Data
Nov 06, 2023



Text-to-SQL aims to automate the process of generating SQL queries on a database from natural language text. In this work, we propose "SQLPrompt", tailored to improve the few-shot prompting capabilities of Text-to-SQL for Large Language Models (LLMs). Our methods include innovative prompt design, execution-based consistency decoding strategy which selects the SQL with the most consistent execution outcome among other SQL proposals, and a method that aims to improve performance by diversifying the SQL proposals during consistency selection with different prompt designs ("MixPrompt") and foundation models ("MixLLMs"). We show that \emph{SQLPrompt} outperforms previous approaches for in-context learning with few labeled data by a large margin, closing the gap with finetuning state-of-the-art with thousands of labeled data.
SQL-PaLM: Improved Large Language Model Adaptation for Text-to-SQL
Jun 07, 2023



One impressive emergent capability of large language models (LLMs) is generation of code, including Structured Query Language (SQL) for databases. For the task of converting natural language text to SQL queries, Text-to-SQL, adaptation of LLMs is of paramount importance, both in in-context learning and fine-tuning settings, depending on the amount of adaptation data used. In this paper, we propose an LLM-based Text-to-SQL model SQL-PaLM, leveraging on PaLM-2, that pushes the state-of-the-art in both settings. Few-shot SQL-PaLM is based on an execution-based self-consistency prompting approach designed for Text-to-SQL, and achieves 77.3% in test-suite accuracy on Spider, which to our best knowledge is the first to outperform previous state-of-the-art with fine-tuning by a significant margin, 4%. Furthermore, we demonstrate that the fine-tuned SQL-PALM outperforms it further by another 1%. Towards applying SQL-PaLM to real-world scenarios we further evaluate its robustness on other challenging variants of Spider and demonstrate the superior generalization capability of SQL-PaLM. In addition, via extensive case studies, we demonstrate the impressive intelligent capabilities and various success enablers of LLM-based Text-to-SQL.
Interpretable Sequence Learning for COVID-19 Forecasting
Aug 03, 2020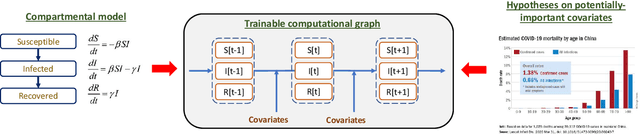
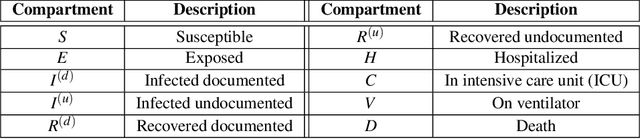
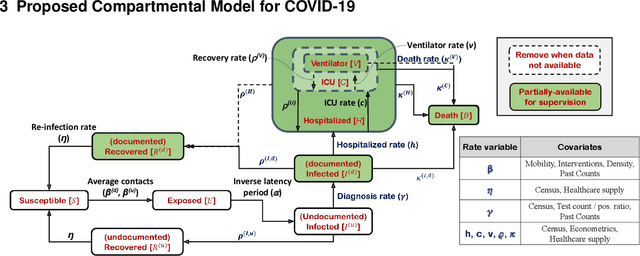
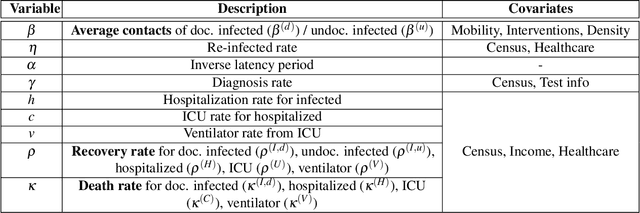
We propose a novel approach that integrates machine learning into compartmental disease modeling to predict the progression of COVID-19. Our model is explainable by design as it explicitly shows how different compartments evolve and it uses interpretable encoders to incorporate covariates and improve performance. Explainability is valuable to ensure that the model's forecasts are credible to epidemiologists and to instill confidence in end-users such as policy makers and healthcare institutions. Our model can be applied at different geographic resolutions, and here we demonstrate it for states and counties in the United States. We show that our model provides more accurate forecasts, in metrics averaged across the entire US, than state-of-the-art alternatives, and that it provides qualitatively meaningful explanatory insights. Lastly, we analyze the performance of our model for different subgroups based on the subgroup distributions within the counties.