 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoK: Unlearnability and Unlearning for Model Dememorization
May 12, 2026Advanced model dememorization methods, including availability poisoning (unlearnability) and machine unlearning, are emerging as key safeguards against data misuse in machine learning (ML). At the training stage, unlearnability embeds imperceptible perturbations into data before release to reduce learnability. At the post-training stage, unlearning removes previously acquired information from models to prevent unauthorized disclosure or use. While both defenses aim to preserve the right to withhold knowledge, their vulnerabilities and shared foundations remain unclear. Specifically, both unlearnability and unlearning suffer from issues such as shallow dememorization, leading to falsely claimed data learnability reduction or forgetting in the presence of weight perturbations. Moreover, input perturbations may affect the effectiveness of downstream unlearning, while unlearning may inadvertently recover domain knowledge hidden by unlearnability. This interplay calls for deeper investigation. Finally, there is a lack of formal guarantees to provide theoretical insights into current defenses against shallow dememorization. In this Systematization of Knowledge, we present the first integrated analysis of model dememorization approaches leveraging unlearnability and unlearning. Our contributions are threefold: (i) a unified taxonomy of unlearnability and scalable unlearning methods; (ii) an empirical evaluation revealing the robustness, interplay, and shallow dememorization of leading methods; and (iii) the first theoretical guarantee on dememorization depth for models processed through certified unlearning. These results lay the foundation for unifying dememorization mechanisms across the ML lifecycle to achieve a deeper immemor state for sensitive knowledge.
If you're waiting for a sign... that might not be it! Mitigating Trust Boundary Confusion from Visual Injections on Vision-Language Agentic Systems
Apr 21, 2026Recent advances in embodied Vision-Language Agentic Systems (VLAS), powered by large vision-language models (LVLMs), enable AI systems to perceive and reason over real-world scenes. Within this context, environmental signals such as traffic lights are essential in-band signals that can and should influence agent behavior. However, similar signals could also be crafted to operate as misleading visual injections, overriding user intent and posing security risks. This duality creates a fundamental challenge: agents must respond to legitimate environmental cues while remaining robust to misleading ones. We refer to this tension as trust boundary confusion. To study this behavior, we design a dual-intent dataset and evaluation framework, through which we show that current LVLM-based agents fail to reliably balance this trade-off, either ignoring useful signals or following harmful ones. We systematically evaluate 7 LVLM agents across multiple embodied settings under both structure-based and noise-based visual injections. To address these vulnerabilities, we propose a multi-agent defense framework that separates perception from decision-making to dynamically assess the reliability of visual inputs. Our approach significantly reduces misleading behaviors while preserving correct responses and provides robustness guarantees under adversarial perturbations. The code of the evaluation framework and artifacts are made available at https://anonymous.4open.science/r/Visual-Prompt-Inject.
MemoryRewardBench: Benchmarking Reward Models for Long-Term Memory Management in Large Language Models
Jan 24, 2026Existing works increasingly adopt memory-centric mechanisms to process long contexts in a segment manner, and effective memory management is one of the key capabilities that enables large language models to effectively propagate information across the entire sequence. Therefore, leveraging reward models (RMs) to automatically and reliably evaluate memory quality is critical. In this work, we introduce MemoryRewardBench, the first benchmark to systematically study the ability of RMs to evaluate long-term memory management processes. MemoryRewardBench covers both long-context comprehension and long-form generation tasks, featuring 10 distinct settings with different memory management patterns, with context length ranging from 8K to 128K tokens. Evaluations on 13 cutting-edge RMs indicate a diminishing performance gap between open-source and proprietary models, with newer-generation models consistently outperforming their predecessors regardless of parameter count. We further expose the capabilities and fundamental limitations of current RMs in evaluating LLM memory management across diverse settings.
$\texttt{MemoryRewardBench}$: Benchmarking Reward Models for Long-Term Memory Management in Large Language Models
Jan 17, 2026Existing works increasingly adopt memory-centric mechanisms to process long contexts in a segment manner, and effective memory management is one of the key capabilities that enables large language models to effectively propagate information across the entire sequence. Therefore, leveraging reward models (RMs) to automatically and reliably evaluate memory quality is critical. In this work, we introduce $\texttt{MemoryRewardBench}$, the first benchmark to systematically study the ability of RMs to evaluate long-term memory management processes. $\texttt{MemoryRewardBench}$ covers both long-context comprehension and long-form generation tasks, featuring 10 distinct settings with different memory management patterns, with context length ranging from 8K to 128K tokens. Evaluations on 13 cutting-edge RMs indicate a diminishing performance gap between open-source and proprietary models, with newer-generation models consistently outperforming their predecessors regardless of parameter count. We further expose the capabilities and fundamental limitations of current RMs in evaluating LLM memory management across diverse settings.
Keep the Lights On, Keep the Lengths in Check: Plug-In Adversarial Detection for Time-Series LLMs in Energy Forecasting
Dec 13, 2025Accurate time-series forecasting is increasingly critical for planning and operations in low-carbon power systems. Emerging time-series large language models (TS-LLMs) now deliver this capability at scale, requiring no task-specific retraining, and are quickly becoming essential components within the Internet-of-Energy (IoE) ecosystem. However, their real-world deployment is complicated by a critical vulnerability: adversarial examples (AEs). Detecting these AEs is challenging because (i) adversarial perturbations are optimized across the entire input sequence and exploit global temporal dependencies, which renders local detection methods ineffective, and (ii) unlike traditional forecasting models with fixed input dimensions, TS-LLMs accept sequences of variable length, increasing variability that complicates detection. To address these challenges, we propose a plug-in detection framework that capitalizes on the TS-LLM's own variable-length input capability. Our method uses sampling-induced divergence as a detection signal. Given an input sequence, we generate multiple shortened variants and detect AEs by measuring the consistency of their forecasts: Benign sequences tend to produce stable predictions under sampling, whereas adversarial sequences show low forecast similarity, because perturbations optimized for a full-length sequence do not transfer reliably to shorter, differently-structured subsamples. We evaluate our approach on three representative TS-LLMs (TimeGPT, TimesFM, and TimeLLM) across three energy datasets: ETTh2 (Electricity Transformer Temperature), NI (Hourly Energy Consumption), and Consumption (Hourly Electricity Consumption and Production). Empirical results confirm strong and robust detection performance across both black-box and white-box attack scenarios, highlighting its practicality as a reliable safeguard for TS-LLM forecasting in real-world energy systems.
VISTAR:A User-Centric and Role-Driven Benchmark for Text-to-Image Evaluation
Aug 08, 2025We present VISTAR, a user-centric, multi-dimensional benchmark for text-to-image (T2I) evaluation that addresses the limitations of existing metrics. VISTAR introduces a two-tier hybrid paradigm: it employs deterministic, scriptable metrics for physically quantifiable attributes (e.g., text rendering, lighting) and a novel Hierarchical Weighted P/N Questioning (HWPQ) scheme that uses constrained vision-language models to assess abstract semantics (e.g., style fusion, cultural fidelity). Grounded in a Delphi study with 120 experts, we defined seven user roles and nine evaluation angles to construct the benchmark, which comprises 2,845 prompts validated by over 15,000 human pairwise comparisons. Our metrics achieve high human alignment (>75%), with the HWPQ scheme reaching 85.9% accuracy on abstract semantics, significantly outperforming VQA baselines. Comprehensive evaluation of state-of-the-art models reveals no universal champion, as role-weighted scores reorder rankings and provide actionable guidance for domain-specific deployment. All resources are publicly released to foster reproducible T2I assessment.
What's Pulling the Strings? Evaluating Integrity and Attribution in AI Training and Inference through Concept Shift
Apr 28, 2025The growing adoption of artificial intelligence (AI) has amplified concerns about trustworthiness, including integrity, privacy, robustness, and bias. To assess and attribute these threats, we propose ConceptLens, a generic framework that leverages pre-trained multimodal models to identify the root causes of integrity threats by analyzing Concept Shift in probing samples. ConceptLens demonstrates strong detection performance for vanilla data poisoning attacks and uncovers vulnerabilities to bias injection, such as the generation of covert advertisements through malicious concept shifts. It identifies privacy risks in unaltered but high-risk samples, filters them before training, and provides insights into model weaknesses arising from incomplete or imbalanced training data. Additionally, at the model level, it attributes concepts that the target model is overly dependent on, identifies misleading concepts, and explains how disrupting key concepts negatively impacts the model. Furthermore, it uncovers sociological biases in generative content, revealing disparities across sociological contexts. Strikingly, ConceptLens reveals how safe training and inference data can be unintentionally and easily exploited, potentially undermining safety alignment. Our study informs actionable insights to breed trust in AI systems, thereby speeding adoption and driving greater innovation.
Review, Refine, Repeat: Understanding Iterative Decoding of AI Agents with Dynamic Evaluation and Selection
Apr 02, 2025While AI agents have shown remarkable performance at various tasks, they still struggle with complex multi-modal applications, structured generation and strategic planning. Improvements via standard fine-tuning is often impractical, as solving agentic tasks usually relies on black box API access without control over model parameters. Inference-time methods such as Best-of-N (BON) sampling offer a simple yet effective alternative to improve performance. However, BON lacks iterative feedback integration mechanism. Hence, we propose Iterative Agent Decoding (IAD) which combines iterative refinement with dynamic candidate evaluation and selection guided by a verifier. IAD differs in how feedback is designed and integrated, specifically optimized to extract maximal signal from reward scores. We conduct a detailed comparison of baselines across key metrics on Sketch2Code, Text2SQL, and Webshop where IAD consistently outperforms baselines, achieving 3--6% absolute gains on Sketch2Code and Text2SQL (with and without LLM judges) and 8--10% gains on Webshop across multiple metrics. To better understand the source of IAD's gains, we perform controlled experiments to disentangle the effect of adaptive feedback from stochastic sampling, and find that IAD's improvements are primarily driven by verifier-guided refinement, not merely sampling diversity. We also show that both IAD and BON exhibit inference-time scaling with increased compute when guided by an optimal verifier. Our analysis highlights the critical role of verifier quality in effective inference-time optimization and examines the impact of noisy and sparse rewards on scaling behavior. Together, these findings offer key insights into the trade-offs and principles of effective inference-time optimization.
Reasoning-SQL: Reinforcement Learning with SQL Tailored Partial Rewards for Reasoning-Enhanced Text-to-SQL
Apr 01, 2025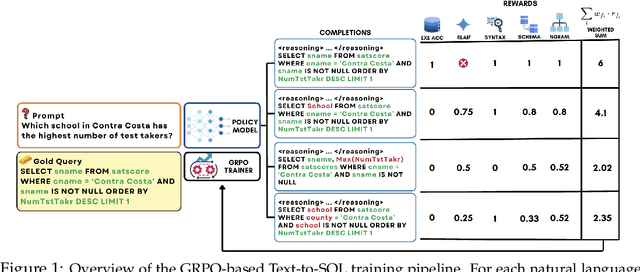
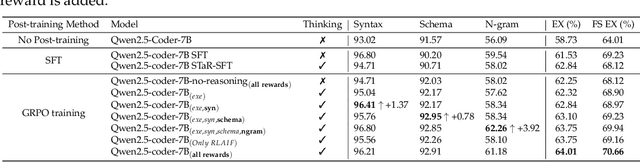
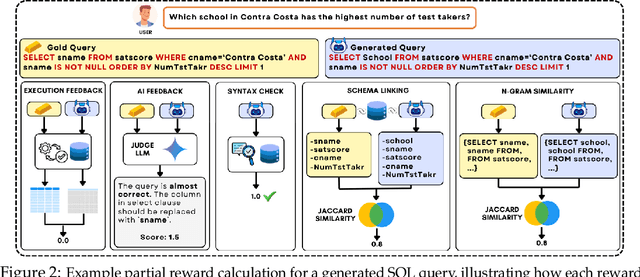
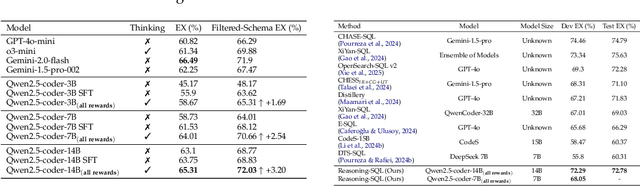
Text-to-SQL is a challenging task involving multiple reasoning-intensive subtasks, including natural language understanding, database schema comprehension, and precise SQL query formulation. Existing approaches often rely on handcrafted reasoning paths with inductive biases that can limit their overall effectiveness. Motivated by the recent success of reasoning-enhanced models such as DeepSeek R1 and OpenAI o1, which effectively leverage reward-driven self-exploration to enhance reasoning capabilities and generalization, we propose a novel set of partial rewards tailored specifically for the Text-to-SQL task. Our reward set includes schema-linking, AI feedback, n-gram similarity, and syntax check, explicitly designed to address the reward sparsity issue prevalent in reinforcement learning (RL). Leveraging group relative policy optimization (GRPO), our approach explicitly encourages large language models (LLMs) to develop intrinsic reasoning skills necessary for accurate SQL query generation. With models of different sizes, we demonstrate that RL-only training with our proposed rewards consistently achieves higher accuracy and superior generalization compared to supervised fine-tuning (SFT). Remarkably, our RL-trained 14B-parameter model significantly outperforms larger proprietary models, e.g. o3-mini by 4% and Gemini-1.5-Pro-002 by 3% on the BIRD benchmark. These highlight the efficacy of our proposed RL-training framework with partial rewards for enhancing both accuracy and reasoning capabilities in Text-to-SQL tasks.
Multi-Agent Design: Optimizing Agents with Better Prompts and Topologies
Feb 04, 2025Large language models, employed as multiple agents that interact and collaborate with each other, have excelled at solving complex tasks. The agents are programmed with prompts that declare their functionality, along with the topologies that orchestrate interactions across agents. Designing prompts and topologies for multi-agent systems (MAS) is inherently complex. To automate the entire design process, we first conduct an in-depth analysis of the design space aiming to understand the factors behind building effective MAS. We reveal that prompts together with topologies play critical roles in enabling more effective MAS design. Based on the insights, we propose Multi-Agent System Search (MASS), a MAS optimization framework that efficiently exploits the complex MAS design space by interleaving its optimization stages, from local to global, from prompts to topologies, over three stages: 1) block-level (local) prompt optimization; 2) workflow topology optimization; 3) workflow-level (global) prompt optimization, where each stage is conditioned on the iteratively optimized prompts/topologies from former stages. We show that MASS-optimized multi-agent systems outperform a spectrum of existing alternatives by a substantial margin. Based on the MASS-found systems, we finally propose design principles behind building effective multi-agent systems.