 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Computer-Use Grounding via User Interface Decomposition and Synthesis
May 19, 2025Graphical user interface (GUI) grounding, the ability to map natural language instructions to specific actions on graphical user interfaces, remains a critical bottleneck in computer use agent development. Current benchmarks oversimplify grounding tasks as short referring expressions, failing to capture the complexity of real-world interactions that require software commonsense, layout understanding, and fine-grained manipulation capabilities. To address these limitations, we introduce OSWorld-G, a comprehensive benchmark comprising 564 finely annotated samples across diverse task types including text matching, element recognition, layout understanding, and precise manipulation. Additionally, we synthesize and release the largest computer use grounding dataset Jedi, which contains 4 million examples through multi-perspective decoupling of tasks. Our multi-scale models trained on Jedi demonstrate its effectiveness by outperforming existing approaches on ScreenSpot-v2, ScreenSpot-Pro, and our OSWorld-G. Furthermore, we demonstrate that improved grounding with Jedi directly enhances agentic capabilities of general foundation models on complex computer tasks, improving from 5% to 27% on OSWorld. Through detailed ablation studies, we identify key factors contributing to grounding performance and verify that combining specialized data for different interface elements enables compositional generalization to novel interfaces. All benchmark, data, checkpoints, and code are open-sourced and available at https://osworld-grounding.github.io.
Spider 2.0: Evaluating Language Models on Real-World Enterprise Text-to-SQL Workflows
Nov 12, 2024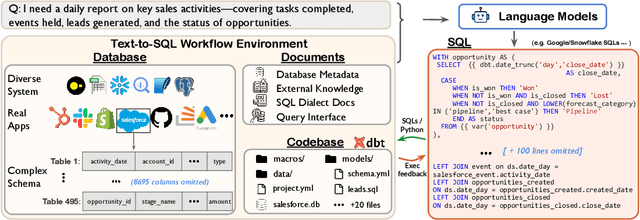


Real-world enterprise text-to-SQL workflows often involve complex cloud or local data across various database systems, multiple SQL queries in various dialects, and diverse operations from data transformation to analytics. We introduce Spider 2.0, an evaluation framework comprising 632 real-world text-to-SQL workflow problems derived from enterprise-level database use cases. The databases in Spider 2.0 are sourced from real data applications, often containing over 1,000 columns and stored in local or cloud database systems such as BigQuery and Snowflake. We show that solving problems in Spider 2.0 frequently requires understanding and searching through database metadata, dialect documentation, and even project-level codebases. This challenge calls for models to interact with complex SQL workflow environments, process extremely long contexts, perform intricate reasoning, and generate multiple SQL queries with diverse operations, often exceeding 100 lines, which goes far beyond traditional text-to-SQL challenges. Our evaluations indicate that based on o1-preview, our code agent framework successfully solves only 17.0% of the tasks, compared with 91.2% on Spider 1.0 and 73.0% on BIRD. Our results on Spider 2.0 show that while language models have demonstrated remarkable performance in code generation -- especially in prior text-to-SQL benchmarks -- they require significant improvement in order to achieve adequate performance for real-world enterprise usage. Progress on Spider 2.0 represents crucial steps towards developing intelligent, autonomous, code agents for real-world enterprise settings. Our code, baseline models, and data are available at https://spider2-sql.github.io.
Spider2-V: How Far Are Multimodal Agents From Automating Data Science and Engineering Workflows?
Jul 15, 2024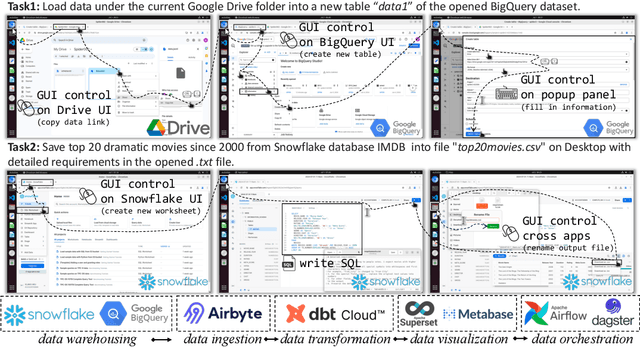
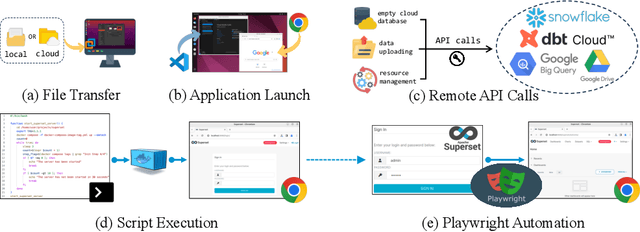
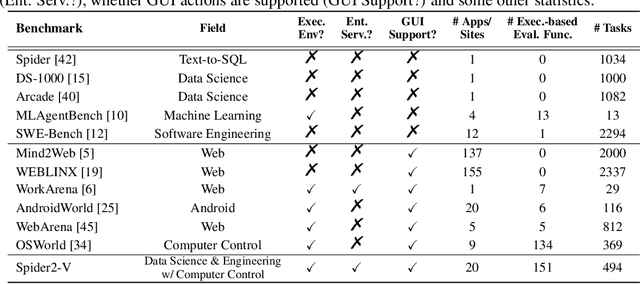
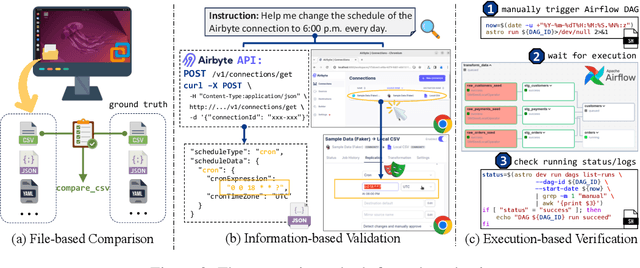
Data science and engineering workflows often span multiple stages, from warehousing to orchestration, using tools like BigQuery, dbt, and Airbyte. As vision language models (VLMs) advance in multimodal understanding and code generation, VLM-based agents could potentially automate these workflows by generating SQL queries, Python code, and GUI operations. This automation can improve the productivity of experts while democratizing access to large-scale data analysis. In this paper, we introduce Spider2-V, the first multimodal agent benchmark focusing on professional data science and engineering workflows, featuring 494 real-world tasks in authentic computer environments and incorporating 20 enterprise-level professional applications. These tasks, derived from real-world use cases, evaluate the ability of a multimodal agent to perform data-related tasks by writing code and managing the GUI in enterprise data software systems. To balance realistic simulation with evaluation simplicity, we devote significant effort to developing automatic configurations for task setup and carefully crafting evaluation metrics for each task. Furthermore, we supplement multimodal agents with comprehensive documents of these enterprise data software systems. Our empirical evaluation reveals that existing state-of-the-art LLM/VLM-based agents do not reliably automate full data workflows (14.0% success). Even with step-by-step guidance, these agents still underperform in tasks that require fine-grained, knowledge-intensive GUI actions (16.2%) and involve remote cloud-hosted workspaces (10.6%). We hope that Spider2-V paves the way for autonomous multimodal agents to transform the automation of data science and engineering workflow. Our code and data are available at https://spider2-v.github.io.