 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
Towards a Holistic and Automated Evaluation Framework for Multi-Level Comprehension of LLMs in Book-Length Contexts
Aug 27, 2025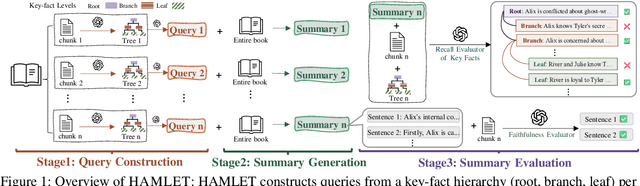


We introduce HAMLET, a holistic and automated framework for evaluating the long-context comprehension of large language models (LLMs). HAMLET structures source texts into a three-level key-fact hierarchy at root-, branch-, and leaf-levels, and employs query-focused summarization to evaluate how well models recall and faithfully represent information at each level. To validate the reliability of our fully automated pipeline, we conduct a systematic human study, showing that our automatic evaluation achieves over 90% agreement with expert human judgments, while reducing the cost by up to 25 times. HAMLET reveals that LLMs struggle with fine-grained comprehension, especially at the leaf level, and are sensitive to positional effects like the lost-in-the-middle. Analytical queries pose greater challenges than narrative ones, and consistent performance gaps emerge between open-source and proprietary models, as well as across model scales. Our code and dataset are publicly available at https://github.com/DISL-Lab/HAMLET.
OpenCUA: Open Foundations for Computer-Use Agents
Aug 12, 2025Vision-language models have demonstrated impressive capabilities as computer-use agents (CUAs) capable of automating diverse computer tasks. As their commercial potential grows, critical details of the most capable CUA systems remain closed. As these agents will increasingly mediate digital interactions and execute consequential decisions on our behalf, the research community needs access to open CUA frameworks to study their capabilities, limitations, and risks. To bridge this gap, we propose OpenCUA, a comprehensive open-source framework for scaling CUA data and foundation models. Our framework consists of: (1) an annotation infrastructure that seamlessly captures human computer-use demonstrations; (2) AgentNet, the first large-scale computer-use task dataset spanning 3 operating systems and 200+ applications and websites; (3) a scalable pipeline that transforms demonstrations into state-action pairs with reflective long Chain-of-Thought reasoning that sustain robust performance gains as data scales. Our end-to-end agent models demonstrate strong performance across CUA benchmarks. In particular, OpenCUA-32B achieves an average success rate of 34.8% on OSWorld-Verified, establishing a new state-of-the-art (SOTA) among open-source models and surpassing OpenAI CUA (GPT-4o). Further analysis confirms that our approach generalizes well across domains and benefits significantly from increased test-time computation. We release our annotation tool, datasets, code, and models to build open foundations for further CUA research.
Scaling Computer-Use Grounding via User Interface Decomposition and Synthesis
May 19, 2025Graphical user interface (GUI) grounding, the ability to map natural language instructions to specific actions on graphical user interfaces, remains a critical bottleneck in computer use agent development. Current benchmarks oversimplify grounding tasks as short referring expressions, failing to capture the complexity of real-world interactions that require software commonsense, layout understanding, and fine-grained manipulation capabilities. To address these limitations, we introduce OSWorld-G, a comprehensive benchmark comprising 564 finely annotated samples across diverse task types including text matching, element recognition, layout understanding, and precise manipulation. Additionally, we synthesize and release the largest computer use grounding dataset Jedi, which contains 4 million examples through multi-perspective decoupling of tasks. Our multi-scale models trained on Jedi demonstrate its effectiveness by outperforming existing approaches on ScreenSpot-v2, ScreenSpot-Pro, and our OSWorld-G. Furthermore, we demonstrate that improved grounding with Jedi directly enhances agentic capabilities of general foundation models on complex computer tasks, improving from 5% to 27% on OSWorld. Through detailed ablation studies, we identify key factors contributing to grounding performance and verify that combining specialized data for different interface elements enables compositional generalization to novel interfaces. All benchmark, data, checkpoints, and code are open-sourced and available at https://osworld-grounding.github.io.
A Comprehensive Survey of Knowledge-Based Vision Question Answering Systems: The Lifecycle of Knowledge in Visual Reasoning Task
Apr 24, 2025Knowledge-based Vision Question Answering (KB-VQA) extends general Vision Question Answering (VQA) by not only requiring the understanding of visual and textual inputs but also extensive range of knowledge, enabling significant advancements across various real-world applications. KB-VQA introduces unique challenges, including the alignment of heterogeneous information from diverse modalities and sources, the retrieval of relevant knowledge from noisy or large-scale repositories, and the execution of complex reasoning to infer answers from the combined context. With the advancement of Large Language Models (LLMs), KB-VQA systems have also undergone a notable transformation, where LLMs serve as powerful knowledge repositories, retrieval-augmented generators and strong reasoners. Despite substantial progress, no comprehensive survey currently exists that systematically organizes and reviews the existing KB-VQA methods. This survey aims to fill this gap by establishing a structured taxonomy of KB-VQA approaches, and categorizing the systems into main stages: knowledge representation, knowledge retrieval, and knowledge reasoning. By exploring various knowledge integration techniques and identifying persistent challenges, this work also outlines promising future research directions, providing a foundation for advancing KB-VQA models and their applications.
Kimi-VL Technical Report
Apr 10, 2025



We present Kimi-VL, an efficient open-source Mixture-of-Experts (MoE) vision-language model (VLM) that offers advanced multimodal reasoning, long-context understanding, and strong agent capabilities - all while activating only 2.8B parameters in its language decoder (Kimi-VL-A3B). Kimi-VL demonstrates strong performance across challenging domains: as a general-purpose VLM, Kimi-VL excels in multi-turn agent tasks (e.g., OSWorld), matching flagship models. Furthermore, it exhibits remarkable capabilities across diverse challenging vision language tasks, including college-level image and video comprehension, OCR, mathematical reasoning, and multi-image understanding. In comparative evaluations, it effectively competes with cutting-edge efficient VLMs such as GPT-4o-mini, Qwen2.5-VL-7B, and Gemma-3-12B-IT, while surpassing GPT-4o in several key domains. Kimi-VL also advances in processing long contexts and perceiving clearly. With a 128K extended context window, Kimi-VL can process diverse long inputs, achieving impressive scores of 64.5 on LongVideoBench and 35.1 on MMLongBench-Doc. Its native-resolution vision encoder, MoonViT, further allows it to see and understand ultra-high-resolution visual inputs, achieving 83.2 on InfoVQA and 34.5 on ScreenSpot-Pro, while maintaining lower computational cost for common tasks. Building upon Kimi-VL, we introduce an advanced long-thinking variant: Kimi-VL-Thinking. Developed through long chain-of-thought (CoT) supervised fine-tuning (SFT) and reinforcement learning (RL), this model exhibits strong long-horizon reasoning capabilities. It achieves scores of 61.7 on MMMU, 36.8 on MathVision, and 71.3 on MathVista while maintaining the compact 2.8B activated LLM parameters, setting a new standard for efficient multimodal thinking models. Code and models are publicly accessible at https://github.com/MoonshotAI/Kimi-VL.
UniRVQA: A Unified Framework for Retrieval-Augmented Vision Question Answering via Self-Reflective Joint Training
Apr 05, 2025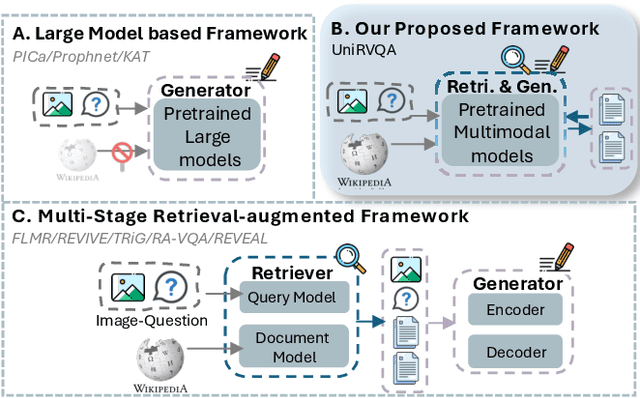
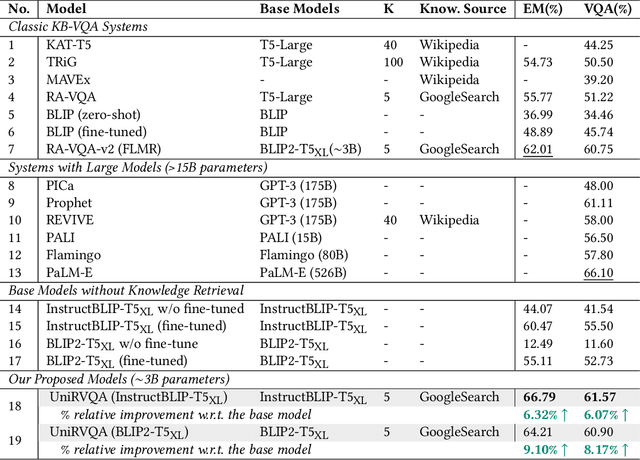
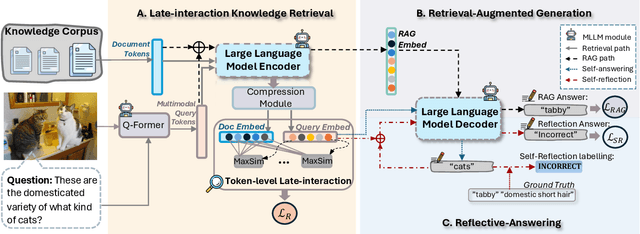
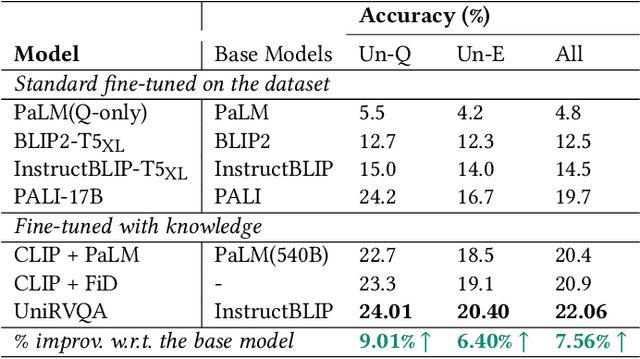
Knowledge-based Vision Question Answering (KB-VQA) systems address complex visual-grounded questions requiring external knowledge, such as web-sourced encyclopedia articles. Existing methods often use sequential and separate frameworks for the retriever and the generator with limited parametric knowledge sharing. However, since both retrieval and generation tasks require accurate understanding of contextual and external information, such separation can potentially lead to suboptimal system performance. Another key challenge is the integration of multimodal information. General-purpose multimodal pre-trained models, while adept at multimodal representation learning, struggle with fine-grained retrieval required for knowledge-intensive visual questions. Recent specialized pre-trained models mitigate the issue, but are computationally expensive. To bridge the gap, we propose a Unified Retrieval-Augmented VQA framework (UniRVQA). UniRVQA adapts general multimodal pre-trained models for fine-grained knowledge-intensive tasks within a unified framework, enabling cross-task parametric knowledge sharing and the extension of existing multimodal representation learning capability. We further introduce a reflective-answering mechanism that allows the model to explicitly evaluate and refine its knowledge boundary. Additionally, we integrate late interaction into the retrieval-augmented generation joint training process to enhance fine-grained understanding of queries and documents. Our approach achieves competitive performance against state-of-the-art models, delivering a significant 4.7% improvement in answering accuracy, and brings an average 7.5% boost in base MLLMs' VQA performance.