 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
Optimizing Domain-Adaptive Self-Supervised Learning for Clinical Voice-Based Disease Classification
Jan 29, 2026The human voice is a promising non-invasive digital biomarker, yet deep learning for voice-based health analysis is hindered by data scarcity and domain mismatch, where models pre-trained on general audio fail to capture the subtle pathological features characteristic of clinical voice data. To address these challenges, we investigate domain-adaptive self-supervised learning (SSL) with Masked Autoencoders (MAE) and demonstrate that standard configurations are suboptimal for health-related audio. Using the Bridge2AI-Voice dataset, a multi-institutional collection of pathological voices, we systematically examine three performance-critical factors: reconstruction loss (Mean Absolute Error vs. Mean Squared Error), normalization (patch-wise vs. global), and masking (random vs. content-aware). Our optimized design, which combines Mean Absolute Error (MA-Error) loss, patch-wise normalization, and content-aware masking, achieves a Macro F1 of $0.688 \pm 0.009$ (over 10 fine-tuning runs), outperforming a strong out-of-domain SSL baseline pre-trained on large-scale general audio, which has a Macro F1 of $0.663 \pm 0.011$. The results show that MA-Error loss improves robustness and content-aware masking boosts performance by emphasizing information-rich regions. These findings highlight the importance of component-level optimization in data-constrained medical applications that rely on audio data.
Kimi K2: Open Agentic Intelligence
Jul 28, 2025



We introduce Kimi K2, a Mixture-of-Experts (MoE) large language model with 32 billion activated parameters and 1 trillion total parameters. We propose the MuonClip optimizer, which improves upon Muon with a novel QK-clip technique to address training instability while enjoying the advanced token efficiency of Muon. Based on MuonClip, K2 was pre-trained on 15.5 trillion tokens with zero loss spike. During post-training, K2 undergoes a multi-stage post-training process, highlighted by a large-scale agentic data synthesis pipeline and a joint reinforcement learning (RL) stage, where the model improves its capabilities through interactions with real and synthetic environments. Kimi K2 achieves state-of-the-art performance among open-source non-thinking models, with strengths in agentic capabilities. Notably, K2 obtains 66.1 on Tau2-Bench, 76.5 on ACEBench (En), 65.8 on SWE-Bench Verified, and 47.3 on SWE-Bench Multilingual -- surpassing most open and closed-sourced baselines in non-thinking settings. It also exhibits strong capabilities in coding, mathematics, and reasoning tasks, with a score of 53.7 on LiveCodeBench v6, 49.5 on AIME 2025, 75.1 on GPQA-Diamond, and 27.1 on OJBench, all without extended thinking. These results position Kimi K2 as one of the most capable open-source large language models to date, particularly in software engineering and agentic tasks. We release our base and post-trained model checkpoints to facilitate future research and applications of agentic intelligence.
Kimi-VL Technical Report
Apr 10, 2025



We present Kimi-VL, an efficient open-source Mixture-of-Experts (MoE) vision-language model (VLM) that offers advanced multimodal reasoning, long-context understanding, and strong agent capabilities - all while activating only 2.8B parameters in its language decoder (Kimi-VL-A3B). Kimi-VL demonstrates strong performance across challenging domains: as a general-purpose VLM, Kimi-VL excels in multi-turn agent tasks (e.g., OSWorld), matching flagship models. Furthermore, it exhibits remarkable capabilities across diverse challenging vision language tasks, including college-level image and video comprehension, OCR, mathematical reasoning, and multi-image understanding. In comparative evaluations, it effectively competes with cutting-edge efficient VLMs such as GPT-4o-mini, Qwen2.5-VL-7B, and Gemma-3-12B-IT, while surpassing GPT-4o in several key domains. Kimi-VL also advances in processing long contexts and perceiving clearly. With a 128K extended context window, Kimi-VL can process diverse long inputs, achieving impressive scores of 64.5 on LongVideoBench and 35.1 on MMLongBench-Doc. Its native-resolution vision encoder, MoonViT, further allows it to see and understand ultra-high-resolution visual inputs, achieving 83.2 on InfoVQA and 34.5 on ScreenSpot-Pro, while maintaining lower computational cost for common tasks. Building upon Kimi-VL, we introduce an advanced long-thinking variant: Kimi-VL-Thinking. Developed through long chain-of-thought (CoT) supervised fine-tuning (SFT) and reinforcement learning (RL), this model exhibits strong long-horizon reasoning capabilities. It achieves scores of 61.7 on MMMU, 36.8 on MathVision, and 71.3 on MathVista while maintaining the compact 2.8B activated LLM parameters, setting a new standard for efficient multimodal thinking models. Code and models are publicly accessible at https://github.com/MoonshotAI/Kimi-VL.
Content-Rich AIGC Video Quality Assessment via Intricate Text Alignment and Motion-Aware Consistency
Feb 06, 2025
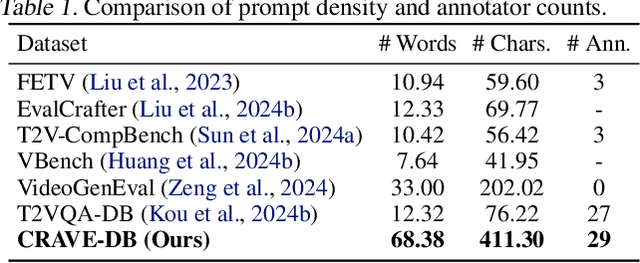

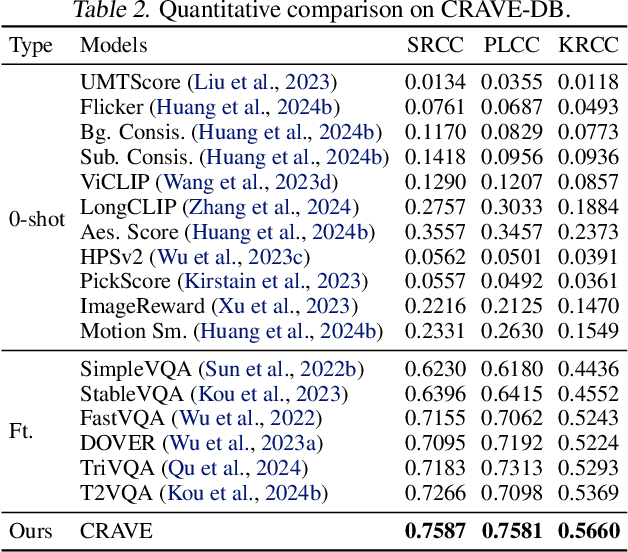
The advent of next-generation video generation models like \textit{Sora} poses challenges for AI-generated content (AIGC) video quality assessment (VQA). These models substantially mitigate flickering artifacts prevalent in prior models, enable longer and complex text prompts and generate longer videos with intricate, diverse motion patterns. Conventional VQA methods designed for simple text and basic motion patterns struggle to evaluate these content-rich videos. To this end, we propose \textbf{CRAVE} (\underline{C}ontent-\underline{R}ich \underline{A}IGC \underline{V}ideo \underline{E}valuator), specifically for the evaluation of Sora-era AIGC videos. CRAVE proposes the multi-granularity text-temporal fusion that aligns long-form complex textual semantics with video dynamics. Additionally, CRAVE leverages the hybrid motion-fidelity modeling to assess temporal artifacts. Furthermore, given the straightforward prompts and content in current AIGC VQA datasets, we introduce \textbf{CRAVE-DB}, a benchmark featuring content-rich videos from next-generation models paired with elaborate prompts. Extensive experiments have shown that the proposed CRAVE achieves excellent results on multiple AIGC VQA benchmarks, demonstrating a high degree of alignment with human perception. All data and code will be publicly available at https://github.com/littlespray/CRAVE.
Aria: An Open Multimodal Native Mixture-of-Experts Model
Oct 08, 2024


Information comes in diverse modalities. Multimodal native AI models are essential to integrate real-world information and deliver comprehensive understanding. While proprietary multimodal native models exist, their lack of openness imposes obstacles for adoptions, let alone adaptations. To fill this gap, we introduce Aria, an open multimodal native model with best-in-class performance across a wide range of multimodal, language, and coding tasks. Aria is a mixture-of-expert model with 3.9B and 3.5B activated parameters per visual token and text token, respectively. It outperforms Pixtral-12B and Llama3.2-11B, and is competitive against the best proprietary models on various multimodal tasks. We pre-train Aria from scratch following a 4-stage pipeline, which progressively equips the model with strong capabilities in language understanding, multimodal understanding, long context window, and instruction following. We open-source the model weights along with a codebase that facilitates easy adoptions and adaptations of Aria in real-world applications.
ChartMoE: Mixture of Expert Connector for Advanced Chart Understanding
Sep 05, 2024



Automatic chart understanding is crucial for content comprehension and document parsing. Multimodal large language models (MLLMs) have demonstrated remarkable capabilities in chart understanding through domain-specific alignment and fine-tuning. However, the application of alignment training within the chart domain is still underexplored. To address this, we propose ChartMoE, which employs the mixture of expert (MoE) architecture to replace the traditional linear projector to bridge the modality gap. Specifically, we train multiple linear connectors through distinct alignment tasks, which are utilized as the foundational initialization parameters for different experts. Additionally, we introduce ChartMoE-Align, a dataset with over 900K chart-table-JSON-code quadruples to conduct three alignment tasks (chart-table/JSON/code). Combined with the vanilla connector, we initialize different experts in four distinct ways and adopt high-quality knowledge learning to further refine the MoE connector and LLM parameters. Extensive experiments demonstrate the effectiveness of the MoE connector and our initialization strategy, e.g., ChartMoE improves the accuracy of the previous state-of-the-art from 80.48% to 84.64% on the ChartQA benchmark.
Learning Robust 3D Representation from CLIP via Dual Denoising
Jul 01, 2024In this paper, we explore a critical yet under-investigated issue: how to learn robust and well-generalized 3D representation from pre-trained vision language models such as CLIP. Previous works have demonstrated that cross-modal distillation can provide rich and useful knowledge for 3D data. However, like most deep learning models, the resultant 3D learning network is still vulnerable to adversarial attacks especially the iterative attack. In this work, we propose Dual Denoising, a novel framework for learning robust and well-generalized 3D representations from CLIP. It combines a denoising-based proxy task with a novel feature denoising network for 3D pre-training. Additionally, we propose utilizing parallel noise inference to enhance the generalization of point cloud features under cross domain settings. Experiments show that our model can effectively improve the representation learning performance and adversarial robustness of the 3D learning network under zero-shot settings without adversarial training. Our code is available at https://github.com/luoshuqing2001/Dual_Denoising.
Exploring AIGC Video Quality: A Focus on Visual Harmony, Video-Text Consistency and Domain Distribution Gap
Apr 27, 2024The recent advancements in Text-to-Video Artificial Intelligence Generated Content (AIGC) have been remarkable. Compared with traditional videos, the assessment of AIGC videos encounters various challenges: visual inconsistency that defy common sense, discrepancies between content and the textual prompt, and distribution gap between various generative models, etc. Target at these challenges, in this work, we categorize the assessment of AIGC video quality into three dimensions: visual harmony, video-text consistency, and domain distribution gap. For each dimension, we design specific modules to provide a comprehensive quality assessment of AIGC videos. Furthermore, our research identifies significant variations in visual quality, fluidity, and style among videos generated by different text-to-video models. Predicting the source generative model can make the AIGC video features more discriminative, which enhances the quality assessment performance. The proposed method was used in the third-place winner of the NTIRE 2024 Quality Assessment for AI-Generated Content - Track 2 Video, demonstrating its effectiveness. Code will be available at https://github.com/Coobiw/TriVQA.
Bringing Textual Prompt to AI-Generated Image Quality Assessment
Mar 27, 2024
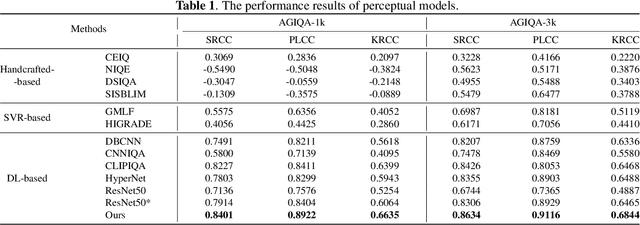
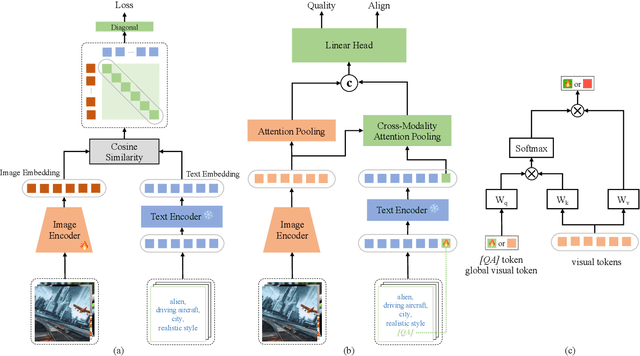
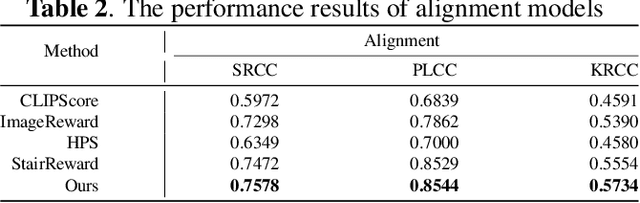
AI-Generated Images (AGIs) have inherent multimodal nature. Unlike traditional image quality assessment (IQA) on natural scenarios, AGIs quality assessment (AGIQA) takes the correspondence of image and its textual prompt into consideration. This is coupled in the ground truth score, which confuses the unimodal IQA methods. To solve this problem, we introduce IP-IQA (AGIs Quality Assessment via Image and Prompt), a multimodal framework for AGIQA via corresponding image and prompt incorporation. Specifically, we propose a novel incremental pretraining task named Image2Prompt for better understanding of AGIs and their corresponding textual prompts. An effective and efficient image-prompt fusion module, along with a novel special [QA] token, are also applied. Both are plug-and-play and beneficial for the cooperation of image and its corresponding prompt. Experiments demonstrate that our IP-IQA achieves the state-of-the-art on AGIQA-1k and AGIQA-3k datasets. Code will be available.