 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenpi Comet: Competition Solution For 2025 BEHAVIOR Challenge
Dec 12, 2025The 2025 BEHAVIOR Challenge is designed to rigorously track progress toward solving long-horizon tasks by physical agents in simulated environments. BEHAVIOR-1K focuses on everyday household tasks that people most want robots to assist with and these tasks introduce long-horizon mobile manipulation challenges in realistic settings, bridging the gap between current research and real-world, human-centric applications. This report presents our solution to the 2025 BEHAVIOR Challenge in a very close 2nd place and substantially outperforms the rest of the submissions. Building on $π_{0.5}$, we focus on systematically building our solution by studying the effects of training techniques and data. Through careful ablations, we show the scaling power in pre-training and post-training phases for competitive performance. We summarize our practical lessons and design recommendations that we hope will provide actionable insights for the broader embodied AI community when adapting powerful foundation models to complex embodied scenarios.
VideoGen-Eval: Agent-based System for Video Generation Evaluation
Mar 30, 2025



The rapid advancement of video generation has rendered existing evaluation systems inadequate for assessing state-of-the-art models, primarily due to simple prompts that cannot showcase the model's capabilities, fixed evaluation operators struggling with Out-of-Distribution (OOD) cases, and misalignment between computed metrics and human preferences. To bridge the gap, we propose VideoGen-Eval, an agent evaluation system that integrates LLM-based content structuring, MLLM-based content judgment, and patch tools designed for temporal-dense dimensions, to achieve a dynamic, flexible, and expandable video generation evaluation. Additionally, we introduce a video generation benchmark to evaluate existing cutting-edge models and verify the effectiveness of our evaluation system. It comprises 700 structured, content-rich prompts (both T2V and I2V) and over 12,000 videos generated by 20+ models, among them, 8 cutting-edge models are selected as quantitative evaluation for the agent and human. Extensive experiments validate that our proposed agent-based evaluation system demonstrates strong alignment with human preferences and reliably completes the evaluation, as well as the diversity and richness of the benchmark.
Content-Rich AIGC Video Quality Assessment via Intricate Text Alignment and Motion-Aware Consistency
Feb 06, 2025
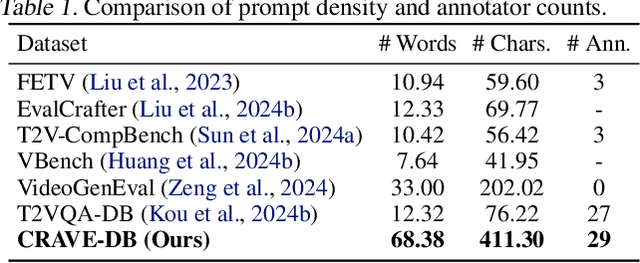

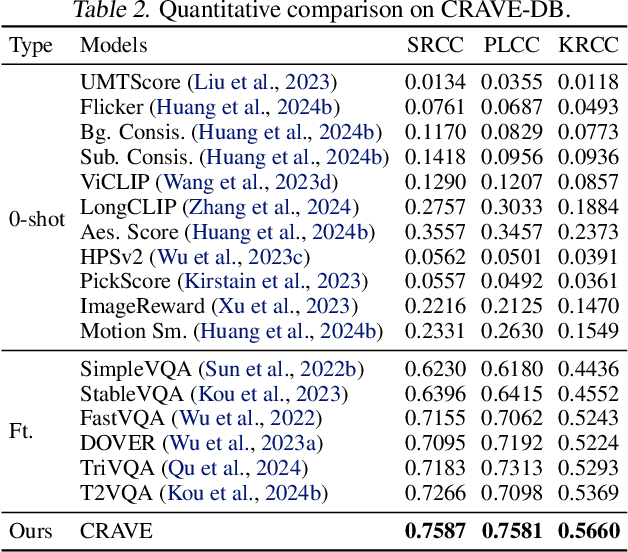
The advent of next-generation video generation models like \textit{Sora} poses challenges for AI-generated content (AIGC) video quality assessment (VQA). These models substantially mitigate flickering artifacts prevalent in prior models, enable longer and complex text prompts and generate longer videos with intricate, diverse motion patterns. Conventional VQA methods designed for simple text and basic motion patterns struggle to evaluate these content-rich videos. To this end, we propose \textbf{CRAVE} (\underline{C}ontent-\underline{R}ich \underline{A}IGC \underline{V}ideo \underline{E}valuator), specifically for the evaluation of Sora-era AIGC videos. CRAVE proposes the multi-granularity text-temporal fusion that aligns long-form complex textual semantics with video dynamics. Additionally, CRAVE leverages the hybrid motion-fidelity modeling to assess temporal artifacts. Furthermore, given the straightforward prompts and content in current AIGC VQA datasets, we introduce \textbf{CRAVE-DB}, a benchmark featuring content-rich videos from next-generation models paired with elaborate prompts. Extensive experiments have shown that the proposed CRAVE achieves excellent results on multiple AIGC VQA benchmarks, demonstrating a high degree of alignment with human perception. All data and code will be publicly available at https://github.com/littlespray/CRAVE.
E-Bench: Subjective-Aligned Benchmark Suite for Text-Driven Video Editing Quality Assessment
Aug 21, 2024



Text-driven video editing has recently experienced rapid development. Despite this, evaluating edited videos remains a considerable challenge. Current metrics tend to fail to align with human perceptions, and effective quantitative metrics for video editing are still notably absent. To address this, we introduce E-Bench, a benchmark suite tailored to the assessment of text-driven video editing. This suite includes E-Bench DB, a video quality assessment (VQA) database for video editing. E-Bench DB encompasses a diverse set of source videos featuring various motions and subjects, along with multiple distinct editing prompts, editing results from 8 different models, and the corresponding Mean Opinion Scores (MOS) from 24 human annotators. Based on E-Bench DB, we further propose E-Bench QA, a quantitative human-aligned measurement for the text-driven video editing task. In addition to the aesthetic, distortion, and other visual quality indicators that traditional VQA methods emphasize, E-Bench QA focuses on the text-video alignment and the relevance modeling between source and edited videos. It proposes a new assessment network for video editing that attains superior performance in alignment with human preferences. To the best of our knowledge, E-Bench introduces the first quality assessment dataset for video editing and an effective subjective-aligned quantitative metric for this domain. All data and code will be publicly available at https://github.com/littlespray/E-Bench.
Exploring AIGC Video Quality: A Focus on Visual Harmony, Video-Text Consistency and Domain Distribution Gap
Apr 27, 2024The recent advancements in Text-to-Video Artificial Intelligence Generated Content (AIGC) have been remarkable. Compared with traditional videos, the assessment of AIGC videos encounters various challenges: visual inconsistency that defy common sense, discrepancies between content and the textual prompt, and distribution gap between various generative models, etc. Target at these challenges, in this work, we categorize the assessment of AIGC video quality into three dimensions: visual harmony, video-text consistency, and domain distribution gap. For each dimension, we design specific modules to provide a comprehensive quality assessment of AIGC videos. Furthermore, our research identifies significant variations in visual quality, fluidity, and style among videos generated by different text-to-video models. Predicting the source generative model can make the AIGC video features more discriminative, which enhances the quality assessment performance. The proposed method was used in the third-place winner of the NTIRE 2024 Quality Assessment for AI-Generated Content - Track 2 Video, demonstrating its effectiveness. Code will be available at https://github.com/Coobiw/TriVQA.
StreamFlow: Streamlined Multi-Frame Optical Flow Estimation for Video Sequences
Nov 28, 2023



Occlusions between consecutive frames have long posed a significant challenge in optical flow estimation. The inherent ambiguity introduced by occlusions directly violates the brightness constancy constraint and considerably hinders pixel-to-pixel matching. To address this issue, multi-frame optical flow methods leverage adjacent frames to mitigate the local ambiguity. Nevertheless, prior multi-frame methods predominantly adopt recursive flow estimation, resulting in a considerable computational overlap. In contrast, we propose a streamlined in-batch framework that eliminates the need for extensive redundant recursive computations while concurrently developing effective spatio-temporal modeling approaches under in-batch estimation constraints. Specifically, we present a Streamlined In-batch Multi-frame (SIM) pipeline tailored to video input, attaining a similar level of time efficiency to two-frame networks. Furthermore, we introduce an efficient Integrative Spatio-temporal Coherence (ISC) modeling method for effective spatio-temporal modeling during the encoding phase, which introduces no additional parameter overhead. Additionally, we devise a Global Temporal Regressor (GTR) that effectively explores temporal relations during decoding. Benefiting from the efficient SIM pipeline and effective modules, StreamFlow not only excels in terms of performance on the challenging KITTI and Sintel datasets, with particular improvement in occluded areas but also attains a remarkable $63.82\%$ enhancement in speed compared with previous multi-frame methods. The code will be available soon at https://github.com/littlespray/StreamFlow.
SKFlow: Learning Optical Flow with Super Kernels
May 29, 2022
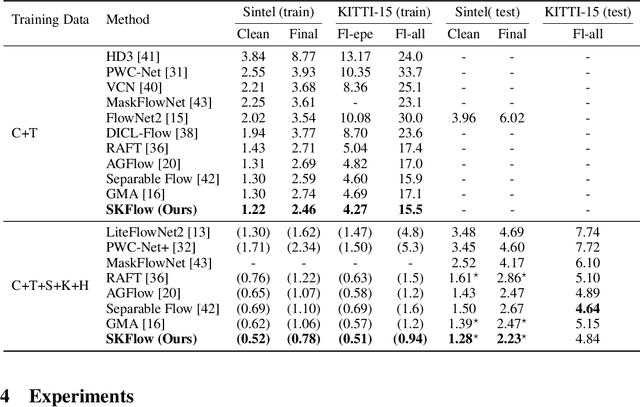
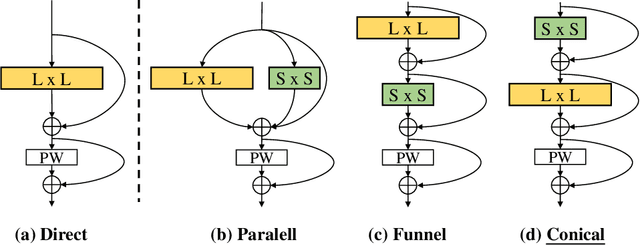
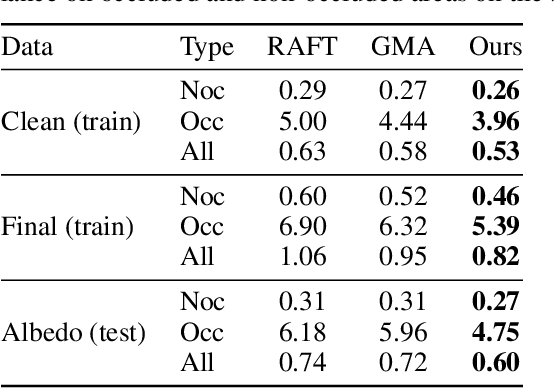
Optical flow estimation is a classical yet challenging task in computer vision. One of the essential factors in accurately predicting optical flow is to alleviate occlusions between frames. However, it is still a thorny problem for current top-performing optical flow estimation methods due to insufficient local evidence to model occluded areas. In this paper, we propose Super Kernel Flow Network (SKFlow), a CNN architecture to ameliorate the impacts of occlusions on optical flow estimation. SKFlow benefits from the super kernels which bring enlarged receptive fields to complement the absent matching information and recover the occluded motions. We present efficient super kernel designs by utilizing conical connections and hybrid depth-wise convolutions. Extensive experiments demonstrate the effectiveness of SKFlow on multiple benchmarks, especially in the occluded areas. Without pre-trained backbones on ImageNet and with modest increase in computation, SKFlow achieves compelling performance and ranks $\textbf{1st}$ among current published methods on Sintel benchmark. On the challenging Sintel final pass test set, SKFlow attains the average end-point error of $2.23$, which surpasses the best published result $2.47$ by $9.72\%$.