 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoKus: Leveraging Cross-Modal Knowledge Transfer for Knowledge-Aware Concept Customization
Mar 13, 2026Concept customization typically binds rare tokens to a target concept. Unfortunately, these approaches often suffer from unstable performance as the pretraining data seldom contains these rare tokens. Meanwhile, these rare tokens fail to convey the inherent knowledge of the target concept. Consequently, we introduce Knowledge-aware Concept Customization, a novel task aiming at binding diverse textual knowledge to target visual concepts. This task requires the model to identify the knowledge within the text prompt to perform high-fidelity customized generation. Meanwhile, the model should efficiently bind all the textual knowledge to the target concept. Therefore, we propose MoKus, a novel framework for knowledge-aware concept customization. Our framework relies on a key observation: cross-modal knowledge transfer, where modifying knowledge within the text modality naturally transfers to the visual modality during generation. Inspired by this observation, MoKus contains two stages: (1) In visual concept learning, we first learn the anchor representation to store the visual information of the target concept. (2) In textual knowledge updating, we update the answer for the knowledge queries to the anchor representation, enabling high-fidelity customized generation. To further comprehensively evaluate our proposed MoKus on the new task, we introduce the first benchmark for knowledge-aware concept customization: KnowCusBench. Extensive evaluations have demonstrated that MoKus outperforms state-of-the-art methods. Moreover, the cross-model knowledge transfer allows MoKus to be easily extended to other knowledge-aware applications like virtual concept creation and concept erasure. We also demonstrate the capability of our method to achieve improvements on world knowledge benchmarks.
Bi-Anchor Interpolation Solver for Accelerating Generative Modeling
Jan 29, 2026Flow Matching (FM) models have emerged as a leading paradigm for high-fidelity synthesis. However, their reliance on iterative Ordinary Differential Equation (ODE) solving creates a significant latency bottleneck. Existing solutions face a dichotomy: training-free solvers suffer from significant performance degradation at low Neural Function Evaluations (NFEs), while training-based one- or few-steps generation methods incur prohibitive training costs and lack plug-and-play versatility. To bridge this gap, we propose the Bi-Anchor Interpolation Solver (BA-solver). BA-solver retains the versatility of standard training-free solvers while achieving significant acceleration by introducing a lightweight SideNet (1-2% backbone size) alongside the frozen backbone. Specifically, our method is founded on two synergistic components: \textbf{1) Bidirectional Temporal Perception}, where the SideNet learns to approximate both future and historical velocities without retraining the heavy backbone; and 2) Bi-Anchor Velocity Integration, which utilizes the SideNet with two anchor velocities to efficiently approximate intermediate velocities for batched high-order integration. By utilizing the backbone to establish high-precision ``anchors'' and the SideNet to densify the trajectory, BA-solver enables large interval sizes with minimized error. Empirical results on ImageNet-256^2 demonstrate that BA-solver achieves generation quality comparable to 100+ NFEs Euler solver in just 10 NFEs and maintains high fidelity in as few as 5 NFEs, incurring negligible training costs. Furthermore, BA-solver ensures seamless integration with existing generative pipelines, facilitating downstream tasks such as image editing.
ASK: Adaptive Self-improving Knowledge Framework for Audio Text Retrieval
Dec 11, 2025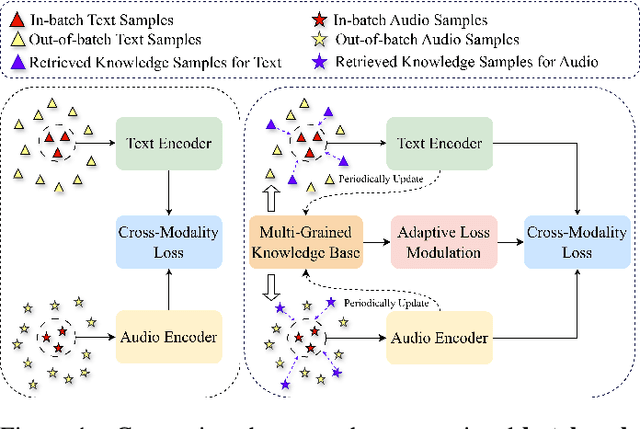
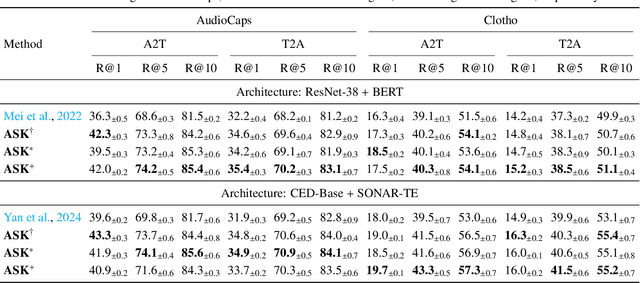
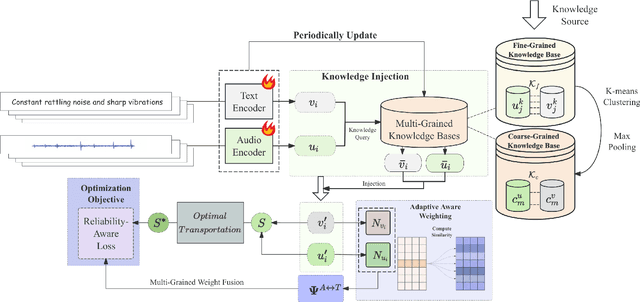
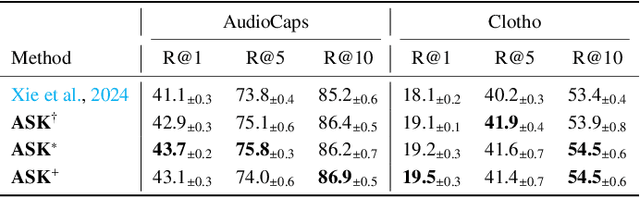
The dominant paradigm for Audio-Text Retrieval (ATR) relies on mini-batch-based contrastive learning. This process, however, is inherently limited by what we formalize as the Gradient Locality Bottleneck (GLB), which structurally prevents models from leveraging out-of-batch knowledge and thus impairs fine-grained and long-tail learning. While external knowledge-enhanced methods can alleviate the GLB, we identify a critical, unaddressed side effect: the Representation-Drift Mismatch (RDM), where a static knowledge base becomes progressively misaligned with the evolving model, turning guidance into noise. To address this dual challenge, we propose the Adaptive Self-improving Knowledge (ASK) framework, a model-agnostic, plug-and-play solution. ASK breaks the GLB via multi-grained knowledge injection, systematically mitigates RDM through dynamic knowledge refinement, and introduces a novel adaptive reliability weighting scheme to ensure consistent knowledge contributes to optimization. Experimental results on two benchmark datasets with superior, state-of-the-art performance justify the efficacy of our proposed ASK framework.
Comprehend and Talk: Text to Speech Synthesis via Dual Language Modeling
Sep 26, 2025Existing Large Language Model (LLM) based autoregressive (AR) text-to-speech (TTS) systems, while achieving state-of-the-art quality, still face critical challenges. The foundation of this LLM-based paradigm is the discretization of the continuous speech waveform into a sequence of discrete tokens by neural audio codec. However, single codebook modeling is well suited to text LLMs, but suffers from significant information loss; hierarchical acoustic tokens, typically generated via Residual Vector Quantization (RVQ), often lack explicit semantic structure, placing a heavy learning burden on the model. Furthermore, the autoregressive process is inherently susceptible to error accumulation, which can degrade generation stability. To address these limitations, we propose CaT-TTS, a novel framework for robust and semantically-grounded zero-shot synthesis. First, we introduce S3Codec, a split RVQ codec that injects explicit linguistic features into its primary codebook via semantic distillation from a state-of-the-art ASR model, providing a structured representation that simplifies the learning task. Second, we propose an ``Understand-then-Generate'' dual-Transformer architecture that decouples comprehension from rendering. An initial ``Understanding'' Transformer models the cross-modal relationship between text and the audio's semantic tokens to form a high-level utterance plan. A subsequent ``Generation'' Transformer then executes this plan, autoregressively synthesizing hierarchical acoustic tokens. Finally, to enhance generation stability, we introduce Masked Audio Parallel Inference (MAPI), a nearly parameter-free inference strategy that dynamically guides the decoding process to mitigate local errors.
Not All Tokens and Heads Are Equally Important: Dual-Level Attention Intervention for Hallucination Mitigation
Jun 14, 2025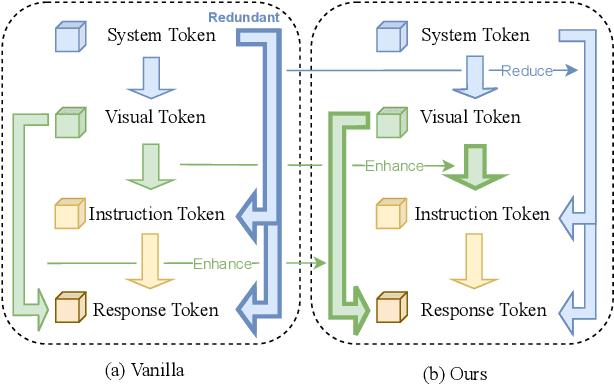
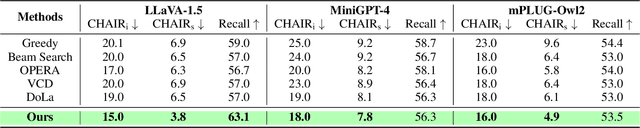
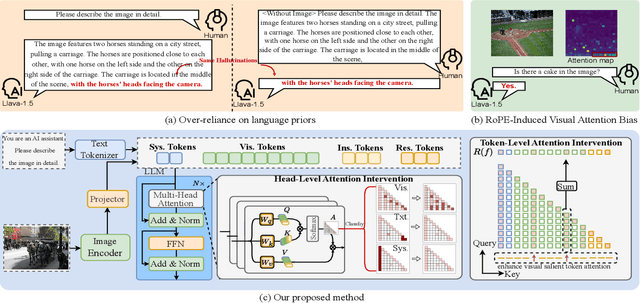

Large vision-language models (LVLMs) have shown remarkable capabilities across a wide range of multimodal tasks. However, they remain prone to visual hallucination (VH), often producing confident but incorrect descriptions of visual content. We present VisFlow, an efficient and training-free framework designed to mitigate VH by directly manipulating attention patterns during inference. Through systematic analysis, we identify three key pathological attention behaviors in LVLMs: (1) weak visual grounding, where attention to visual tokens is insufficient or misallocated, over-focusing on uninformative regions; (2) language prior dominance, where excessive attention to prior response tokens reinforces autoregressive patterns and impairs multimodal alignment; (3) prompt redundancy, where many attention heads fixate on system prompt tokens, disrupting the integration of image, instruction, and response content. To address these issues, we introduce two inference-time interventions: token-level attention intervention (TAI), which enhances focus on salient visual content, and head-level attention intervention (HAI), which suppresses over-attention to prompt and nearby text tokens. VisFlow operates without additional training or model modifications. Extensive experiments across models and benchmarks show that VisFlow effectively reduces hallucinations and improves visual factuality, with negligible computational cost.
DanceTogether! Identity-Preserving Multi-Person Interactive Video Generation
May 23, 2025Controllable video generation (CVG) has advanced rapidly, yet current systems falter when more than one actor must move, interact, and exchange positions under noisy control signals. We address this gap with DanceTogether, the first end-to-end diffusion framework that turns a single reference image plus independent pose-mask streams into long, photorealistic videos while strictly preserving every identity. A novel MaskPoseAdapter binds "who" and "how" at every denoising step by fusing robust tracking masks with semantically rich-but noisy-pose heat-maps, eliminating the identity drift and appearance bleeding that plague frame-wise pipelines. To train and evaluate at scale, we introduce (i) PairFS-4K, 26 hours of dual-skater footage with 7,000+ distinct IDs, (ii) HumanRob-300, a one-hour humanoid-robot interaction set for rapid cross-domain transfer, and (iii) TogetherVideoBench, a three-track benchmark centered on the DanceTogEval-100 test suite covering dance, boxing, wrestling, yoga, and figure skating. On TogetherVideoBench, DanceTogether outperforms the prior arts by a significant margin. Moreover, we show that a one-hour fine-tune yields convincing human-robot videos, underscoring broad generalization to embodied-AI and HRI tasks. Extensive ablations confirm that persistent identity-action binding is critical to these gains. Together, our model, datasets, and benchmark lift CVG from single-subject choreography to compositionally controllable, multi-actor interaction, opening new avenues for digital production, simulation, and embodied intelligence. Our video demos and code are available at https://DanceTog.github.io/.
VideoGen-Eval: Agent-based System for Video Generation Evaluation
Mar 30, 2025



The rapid advancement of video generation has rendered existing evaluation systems inadequate for assessing state-of-the-art models, primarily due to simple prompts that cannot showcase the model's capabilities, fixed evaluation operators struggling with Out-of-Distribution (OOD) cases, and misalignment between computed metrics and human preferences. To bridge the gap, we propose VideoGen-Eval, an agent evaluation system that integrates LLM-based content structuring, MLLM-based content judgment, and patch tools designed for temporal-dense dimensions, to achieve a dynamic, flexible, and expandable video generation evaluation. Additionally, we introduce a video generation benchmark to evaluate existing cutting-edge models and verify the effectiveness of our evaluation system. It comprises 700 structured, content-rich prompts (both T2V and I2V) and over 12,000 videos generated by 20+ models, among them, 8 cutting-edge models are selected as quantitative evaluation for the agent and human. Extensive experiments validate that our proposed agent-based evaluation system demonstrates strong alignment with human preferences and reliably completes the evaluation, as well as the diversity and richness of the benchmark.
BlobCtrl: A Unified and Flexible Framework for Element-level Image Generation and Editing
Mar 17, 2025Element-level visual manipulation is essential in digital content creation, but current diffusion-based methods lack the precision and flexibility of traditional tools. In this work, we introduce BlobCtrl, a framework that unifies element-level generation and editing using a probabilistic blob-based representation. By employing blobs as visual primitives, our approach effectively decouples and represents spatial location, semantic content, and identity information, enabling precise element-level manipulation. Our key contributions include: 1) a dual-branch diffusion architecture with hierarchical feature fusion for seamless foreground-background integration; 2) a self-supervised training paradigm with tailored data augmentation and score functions; and 3) controllable dropout strategies to balance fidelity and diversity. To support further research, we introduce BlobData for large-scale training and BlobBench for systematic evaluation. Experiments show that BlobCtrl excels in various element-level manipulation tasks while maintaining computational efficiency, offering a practical solution for precise and flexible visual content creation. Project page: https://liyaowei-stu.github.io/project/BlobCtrl/
DisPose: Disentangling Pose Guidance for Controllable Human Image Animation
Dec 13, 2024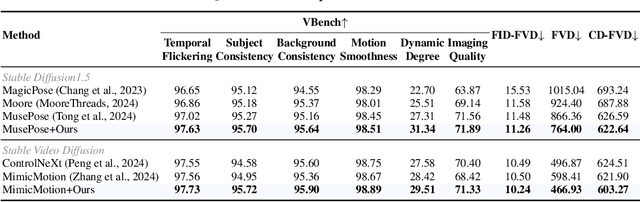
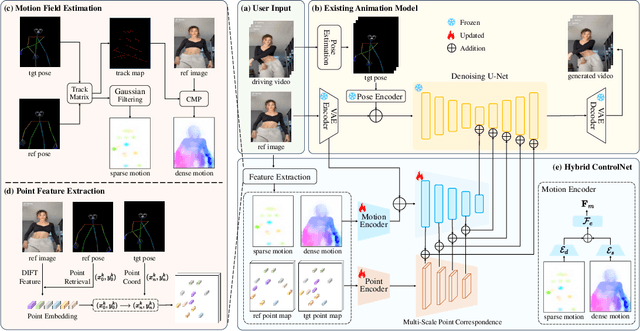
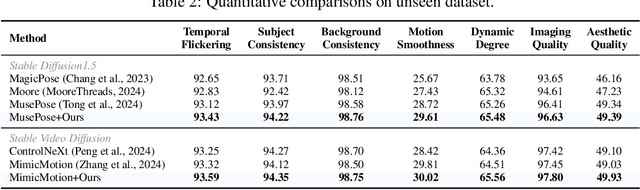

Controllable human image animation aims to generate videos from reference images using driving videos. Due to the limited control signals provided by sparse guidance (e.g., skeleton pose), recent works have attempted to introduce additional dense conditions (e.g., depth map) to ensure motion alignment. However, such strict dense guidance impairs the quality of the generated video when the body shape of the reference character differs significantly from that of the driving video. In this paper, we present DisPose to mine more generalizable and effective control signals without additional dense input, which disentangles the sparse skeleton pose in human image animation into motion field guidance and keypoint correspondence. Specifically, we generate a dense motion field from a sparse motion field and the reference image, which provides region-level dense guidance while maintaining the generalization of the sparse pose control. We also extract diffusion features corresponding to pose keypoints from the reference image, and then these point features are transferred to the target pose to provide distinct identity information. To seamlessly integrate into existing models, we propose a plug-and-play hybrid ControlNet that improves the quality and consistency of generated videos while freezing the existing model parameters. Extensive qualitative and quantitative experiments demonstrate the superiority of DisPose compared to current methods. Code: \href{https://github.com/lihxxx/DisPose}{https://github.com/lihxxx/DisPose}.
Towards a Multimodal Large Language Model with Pixel-Level Insight for Biomedicine
Dec 12, 2024In recent years, Multimodal Large Language Models (MLLM) have achieved notable advancements, demonstrating the feasibility of developing an intelligent biomedical assistant. However, current biomedical MLLMs predominantly focus on image-level understanding and restrict interactions to textual commands, thus limiting their capability boundaries and the flexibility of usage. In this paper, we introduce a novel end-to-end multimodal large language model for the biomedical domain, named MedPLIB, which possesses pixel-level understanding. Excitingly, it supports visual question answering (VQA), arbitrary pixel-level prompts (points, bounding boxes, and free-form shapes), and pixel-level grounding. We propose a novel Mixture-of-Experts (MoE) multi-stage training strategy, which divides MoE into separate training phases for a visual-language expert model and a pixel-grounding expert model, followed by fine-tuning using MoE. This strategy effectively coordinates multitask learning while maintaining the computational cost at inference equivalent to that of a single expert model. To advance the research of biomedical MLLMs, we introduce the Medical Complex Vision Question Answering Dataset (MeCoVQA), which comprises an array of 8 modalities for complex medical imaging question answering and image region understanding. Experimental results indicate that MedPLIB has achieved state-of-the-art outcomes across multiple medical visual language tasks. More importantly, in zero-shot evaluations for the pixel grounding task, MedPLIB leads the best small and large models by margins of 19.7 and 15.6 respectively on the mDice metric. The codes, data, and model checkpoints will be made publicly available at https://github.com/ShawnHuang497/MedPLIB.