 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNext-Scale Generative Reranking: A Tree-based Generative Rerank Method at Meituan
Apr 07, 2026In modern multi-stage recommendation systems, reranking plays a critical role by modeling contextual information. Due to inherent challenges such as the combinatorial space complexity, an increasing number of methods adopt the generative paradigm: the generator produces the optimal list during inference, while an evaluator guides the generator's optimization during the training phase. However, these methods still face two problems. Firstly, these generators fail to produce optimal generation results due to the lack of both local and global perspectives, regardless of whether the generation strategy is autoregressive or non-autoregressive. Secondly, the goal inconsistency problem between the generator and the evaluator during training complicates the guidance signal and leading to suboptimal performance. To address these issues, we propose the \textbf{N}ext-\textbf{S}cale \textbf{G}eneration \textbf{R}eranking (NSGR), a tree-based generative framework. Specifically, we introduce a next-scale generator (NSG) that progressively expands a recommendation list from user interests in a coarse-to-fine manner, balancing global and local perspectives. Furthermore, we design a multi-scale neighbor loss, which leverages a tree-based multi-scale evaluator (MSE) to provide scale-specific guidance to the NSG at each scale. Extensive experiments on public and industrial datasets validate the effectiveness of NSGR. And NSGR has been successfully deployed on the Meituan food delivery platform.
Controllable Text-to-Motion Generation via Modular Body-Part Phase Control
Mar 20, 2026Text-to-motion (T2M) generation is becoming a practical tool for animation and interactive avatars. However, modifying specific body parts while maintaining overall motion coherence remains challenging. Existing methods typically rely on cumbersome, high-dimensional joint constraints (e.g., trajectories), which hinder user-friendly, iterative refinement. To address this, we propose Modular Body-Part Phase Control, a plug-and-play framework enabling structured, localized editing via a compact, scalar-based phase interface. By modeling body-part latent motion channels as sinusoidal phase signals characterized by amplitude, frequency, phase shift, and offset, we extract interpretable codes that capture part-specific dynamics. A modular Phase ControlNet branch then injects this signal via residual feature modulation, seamlessly decoupling control from the generative backbone. Experiments on both diffusion- and flow-based models demonstrate that our approach provides predictable and fine-grained control over motion magnitude, speed, and timing. It preserves global motion coherence and offers a practical paradigm for controllable T2M generation. Project page: https://jixiii.github.io/bp-phase-project-page/
OCRA: Object-Centric Learning with 3D and Tactile Priors for Human-to-Robot Action Transfer
Mar 15, 2026We present OCRA, an Object-Centric framework for video-based human-to-Robot Action transfer that learns directly from human demonstration videos to enable robust manipulation. Object-centric learning emphasizes task-relevant objects and their interactions while filtering out irrelevant background, providing a natural and scalable way to teach robots. OCRA leverages multi-view RGB videos, the state-of-the-art 3D foundation model VGGT, and advanced detection and segmentation models to reconstruct object-centric 3D point clouds, capturing rich interactions between objects. To handle properties not easily perceived by vision alone, we incorporate tactile priors via a large-scale dataset of over one million tactile images. These 3D and tactile priors are fused through a multimodal module (ResFiLM) and fed into a Diffusion Policy to generate robust manipulation actions. Extensive experiments on both vision-only and visuo-tactile tasks show that OCRA significantly outperforms existing baselines and ablations, demonstrating its effectiveness for learning from human demonstration videos.
Learning Generalizable Hand-Object Tracking from Synthetic Demonstrations
Dec 22, 2025We present a system for learning generalizable hand-object tracking controllers purely from synthetic data, without requiring any human demonstrations. Our approach makes two key contributions: (1) HOP, a Hand-Object Planner, which can synthesize diverse hand-object trajectories; and (2) HOT, a Hand-Object Tracker that bridges synthetic-to-physical transfer through reinforcement learning and interaction imitation learning, delivering a generalizable controller conditioned on target hand-object states. Our method extends to diverse object shapes and hand morphologies. Through extensive evaluations, we show that our approach enables dexterous hands to track challenging, long-horizon sequences including object re-arrangement and agile in-hand reorientation. These results represent a significant step toward scalable foundation controllers for manipulation that can learn entirely from synthetic data, breaking the data bottleneck that has long constrained progress in dexterous manipulation.
Implementation and Assessment of an Augmented Training Curriculum for Surgical Robotics
Jul 10, 2025The integration of high-level assistance algorithms in surgical robotics training curricula may be beneficial in establishing a more comprehensive and robust skillset for aspiring surgeons, improving their clinical performance as a consequence. This work presents the development and validation of a haptic-enhanced Virtual Reality simulator for surgical robotics training, featuring 8 surgical tasks that the trainee can interact with thanks to the embedded physics engine. This virtual simulated environment is augmented by the introduction of high-level haptic interfaces for robotic assistance that aim at re-directing the motion of the trainee's hands and wrists toward targets or away from obstacles, and providing a quantitative performance score after the execution of each training exercise.An experimental study shows that the introduction of enhanced robotic assistance into a surgical robotics training curriculum improves performance during the training process and, crucially, promotes the transfer of the acquired skills to an unassisted surgical scenario, like the clinical one.
UniTracker: Learning Universal Whole-Body Motion Tracker for Humanoid Robots
Jul 10, 2025Humanoid robots must achieve diverse, robust, and generalizable whole-body control to operate effectively in complex, human-centric environments. However, existing methods, particularly those based on teacher-student frameworks often suffer from a loss of motion diversity during policy distillation and exhibit limited generalization to unseen behaviors. In this work, we present UniTracker, a simplified yet powerful framework that integrates a Conditional Variational Autoencoder (CVAE) into the student policy to explicitly model the latent diversity of human motion. By leveraging a learned CVAE prior, our method enables the student to retain expressive motion characteristics while improving robustness and adaptability under partial observations. The result is a single policy capable of tracking a wide spectrum of whole-body motions with high fidelity and stability. Comprehensive experiments in both simulation and real-world deployments demonstrate that UniTracker significantly outperforms MLP-based DAgger baselines in motion quality, generalization to unseen references, and deployment robustness, offering a practical and scalable solution for expressive humanoid control.
Go to Zero: Towards Zero-shot Motion Generation with Million-scale Data
Jul 09, 2025Generating diverse and natural human motion sequences based on textual descriptions constitutes a fundamental and challenging research area within the domains of computer vision, graphics, and robotics. Despite significant advancements in this field, current methodologies often face challenges regarding zero-shot generalization capabilities, largely attributable to the limited size of training datasets. Moreover, the lack of a comprehensive evaluation framework impedes the advancement of this task by failing to identify directions for improvement. In this work, we aim to push text-to-motion into a new era, that is, to achieve the generalization ability of zero-shot. To this end, firstly, we develop an efficient annotation pipeline and introduce MotionMillion-the largest human motion dataset to date, featuring over 2,000 hours and 2 million high-quality motion sequences. Additionally, we propose MotionMillion-Eval, the most comprehensive benchmark for evaluating zero-shot motion generation. Leveraging a scalable architecture, we scale our model to 7B parameters and validate its performance on MotionMillion-Eval. Our results demonstrate strong generalization to out-of-domain and complex compositional motions, marking a significant step toward zero-shot human motion generation. The code is available at https://github.com/VankouF/MotionMillion-Codes.
AnchorDP3: 3D Affordance Guided Sparse Diffusion Policy for Robotic Manipulation
Jun 24, 2025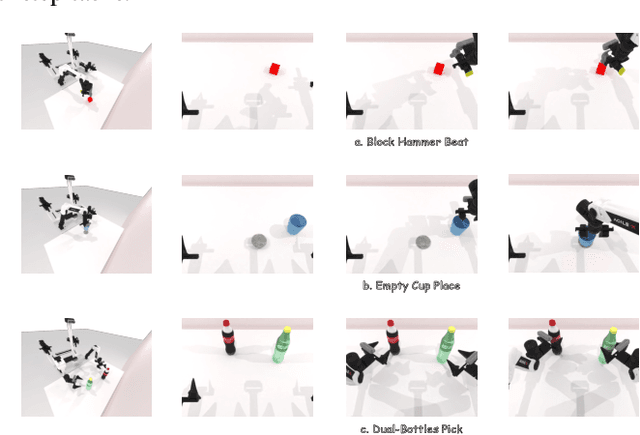

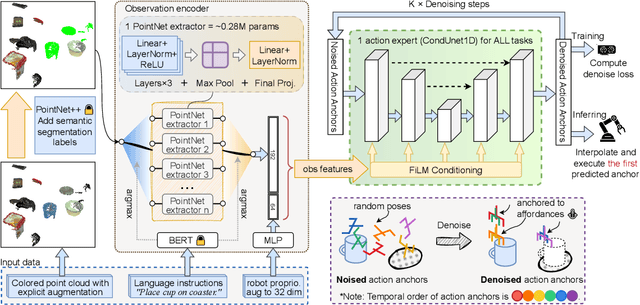
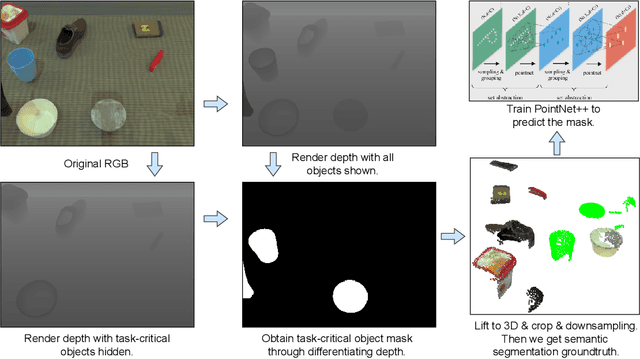
We present AnchorDP3, a diffusion policy framework for dual-arm robotic manipulation that achieves state-of-the-art performance in highly randomized environments. AnchorDP3 integrates three key innovations: (1) Simulator-Supervised Semantic Segmentation, using rendered ground truth to explicitly segment task-critical objects within the point cloud, which provides strong affordance priors; (2) Task-Conditioned Feature Encoders, lightweight modules processing augmented point clouds per task, enabling efficient multi-task learning through a shared diffusion-based action expert; (3) Affordance-Anchored Keypose Diffusion with Full State Supervision, replacing dense trajectory prediction with sparse, geometrically meaningful action anchors, i.e., keyposes such as pre-grasp pose, grasp pose directly anchored to affordances, drastically simplifying the prediction space; the action expert is forced to predict both robot joint angles and end-effector poses simultaneously, which exploits geometric consistency to accelerate convergence and boost accuracy. Trained on large-scale, procedurally generated simulation data, AnchorDP3 achieves a 98.7% average success rate in the RoboTwin benchmark across diverse tasks under extreme randomization of objects, clutter, table height, lighting, and backgrounds. This framework, when integrated with the RoboTwin real-to-sim pipeline, has the potential to enable fully autonomous generation of deployable visuomotor policies from only scene and instruction, totally eliminating human demonstrations from learning manipulation skills.
VideoGen-Eval: Agent-based System for Video Generation Evaluation
Mar 30, 2025



The rapid advancement of video generation has rendered existing evaluation systems inadequate for assessing state-of-the-art models, primarily due to simple prompts that cannot showcase the model's capabilities, fixed evaluation operators struggling with Out-of-Distribution (OOD) cases, and misalignment between computed metrics and human preferences. To bridge the gap, we propose VideoGen-Eval, an agent evaluation system that integrates LLM-based content structuring, MLLM-based content judgment, and patch tools designed for temporal-dense dimensions, to achieve a dynamic, flexible, and expandable video generation evaluation. Additionally, we introduce a video generation benchmark to evaluate existing cutting-edge models and verify the effectiveness of our evaluation system. It comprises 700 structured, content-rich prompts (both T2V and I2V) and over 12,000 videos generated by 20+ models, among them, 8 cutting-edge models are selected as quantitative evaluation for the agent and human. Extensive experiments validate that our proposed agent-based evaluation system demonstrates strong alignment with human preferences and reliably completes the evaluation, as well as the diversity and richness of the benchmark.
MotionStreamer: Streaming Motion Generation via Diffusion-based Autoregressive Model in Causal Latent Space
Mar 19, 2025This paper addresses the challenge of text-conditioned streaming motion generation, which requires us to predict the next-step human pose based on variable-length historical motions and incoming texts. Existing methods struggle to achieve streaming motion generation, e.g., diffusion models are constrained by pre-defined motion lengths, while GPT-based methods suffer from delayed response and error accumulation problem due to discretized non-causal tokenization. To solve these problems, we propose MotionStreamer, a novel framework that incorporates a continuous causal latent space into a probabilistic autoregressive model. The continuous latents mitigate information loss caused by discretization and effectively reduce error accumulation during long-term autoregressive generation. In addition, by establishing temporal causal dependencies between current and historical motion latents, our model fully utilizes the available information to achieve accurate online motion decoding. Experiments show that our method outperforms existing approaches while offering more applications, including multi-round generation, long-term generation, and dynamic motion composition. Project Page: https://zju3dv.github.io/MotionStreamer/