 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePD-SORT: Occlusion-Robust Multi-Object Tracking Using Pseudo-Depth Cues
Jan 20, 2025



Multi-object tracking (MOT) is a rising topic in video processing technologies and has important application value in consumer electronics. Currently, tracking-by-detection (TBD) is the dominant paradigm for MOT, which performs target detection and association frame by frame. However, the association performance of TBD methods degrades in complex scenes with heavy occlusions, which hinders the application of such methods in real-world scenarios.To this end, we incorporate pseudo-depth cues to enhance the association performance and propose Pseudo-Depth SORT (PD-SORT). First, we extend the Kalman filter state vector with pseudo-depth states. Second, we introduce a novel depth volume IoU (DVIoU) by combining the conventional 2D IoU with pseudo-depth. Furthermore, we develop a quantized pseudo-depth measurement (QPDM) strategy for more robust data association. Besides, we also integrate camera motion compensation (CMC) to handle dynamic camera situations. With the above designs, PD-SORT significantly alleviates the occlusion-induced ambiguous associations and achieves leading performances on DanceTrack, MOT17, and MOT20. Note that the improvement is especially obvious on DanceTrack, where objects show complex motions, similar appearances, and frequent occlusions. The code is available at https://github.com/Wangyc2000/PD_SORT.
A New Formulation of Lipschitz Constrained With Functional Gradient Learning for GANs
Jan 20, 2025This paper introduces a promising alternative method for training Generative Adversarial Networks (GANs) on large-scale datasets with clear theoretical guarantees. GANs are typically learned through a minimax game between a generator and a discriminator, which is known to be empirically unstable. Previous learning paradigms have encountered mode collapse issues without a theoretical solution. To address these challenges, we propose a novel Lipschitz-constrained Functional Gradient GANs learning (Li-CFG) method to stabilize the training of GAN and provide a theoretical foundation for effectively increasing the diversity of synthetic samples by reducing the neighborhood size of the latent vector. Specifically, we demonstrate that the neighborhood size of the latent vector can be reduced by increasing the norm of the discriminator gradient, resulting in enhanced diversity of synthetic samples. To efficiently enlarge the norm of the discriminator gradient, we introduce a novel {\epsilon}-centered gradient penalty that amplifies the norm of the discriminator gradient using the hyper-parameter {\epsilon}. In comparison to other constraints, our method enlarging the discriminator norm, thus obtaining the smallest neighborhood size of the latent vector. Extensive experiments on benchmark datasets for image generation demonstrate the efficacy of the Li-CFG method and the {\epsilon}-centered gradient penalty. The results showcase improved stability and increased diversity of synthetic samples.
Nested Annealed Training Scheme for Generative Adversarial Networks
Jan 20, 2025Recently, researchers have proposed many deep generative models, including generative adversarial networks(GANs) and denoising diffusion models. Although significant breakthroughs have been made and empirical success has been achieved with the GAN, its mathematical underpinnings remain relatively unknown. This paper focuses on a rigorous mathematical theoretical framework: the composite-functional-gradient GAN (CFG)[1]. Specifically, we reveal the theoretical connection between the CFG model and score-based models. We find that the training objective of the CFG discriminator is equivalent to finding an optimal D(x). The optimal gradient of D(x) differentiates the integral of the differences between the score functions of real and synthesized samples. Conversely, training the CFG generator involves finding an optimal G(x) that minimizes this difference. In this paper, we aim to derive an annealed weight preceding the weight of the CFG discriminator. This new explicit theoretical explanation model is called the annealed CFG method. To overcome the limitation of the annealed CFG method, as the method is not readily applicable to the SOTA GAN model, we propose a nested annealed training scheme (NATS). This scheme keeps the annealed weight from the CFG method and can be seamlessly adapted to various GAN models, no matter their structural, loss, or regularization differences. We conduct thorough experimental evaluations on various benchmark datasets for image generation. The results show that our annealed CFG and NATS methods significantly improve the quality and diversity of the synthesized samples. This improvement is clear when comparing the CFG method and the SOTA GAN models.
Anchor Graph Structure Fusion Hashing for Cross-Modal Similarity Search
Feb 09, 2022
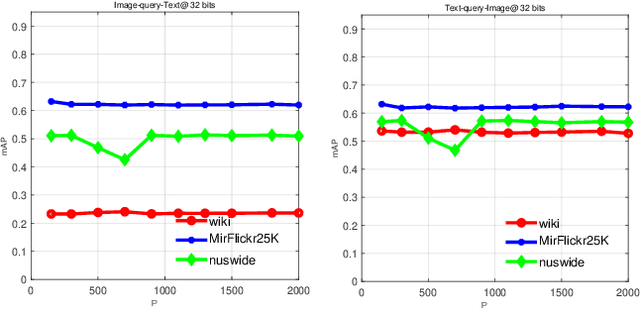
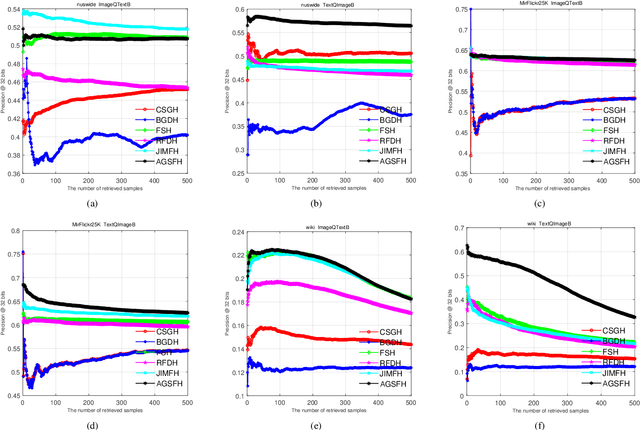
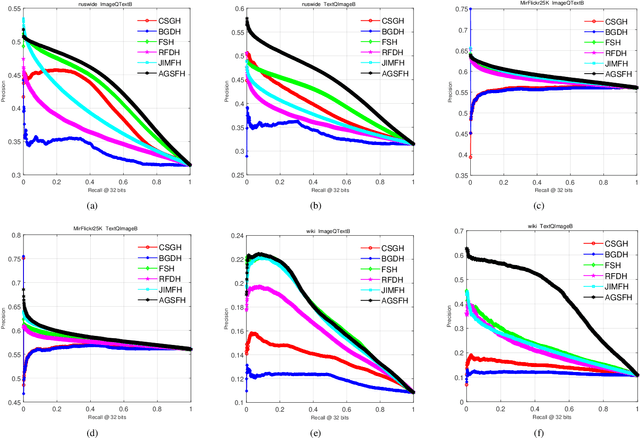
Cross-modal hashing still has some challenges needed to address: (1) most existing CMH methods take graphs as input to model data distribution. These methods omit to consider the correlation of graph structure among multiple modalities; (2) most existing CMH methods ignores considering the fusion affinity among multi-modalities data; (3) most existing CMH methods relax the discrete constraints to solve the optimization objective, significantly degrading the retrieval performance. To solve the above limitations, we propose a novel Anchor Graph Structure Fusion Hashing (AGSFH). AGSFH constructs the anchor graph structure fusion matrix from different anchor graphs of multiple modalities with the Hadamard product, which can fully exploit the geometric property of underlying data structure. Based on the anchor graph structure fusion matrix, AGSFH attempts to directly learn an intrinsic anchor graph, where the structure of the intrinsic anchor graph is adaptively tuned so that the number of components of the intrinsic graph is exactly equal to the number of clusters. Besides, AGSFH preserves the anchor fusion affinity into the common binary Hamming space. Furthermore, a discrete optimization framework is designed to learn the unified binary codes. Extensive experimental results on three public social datasets demonstrate the superiority of AGSFH.