 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Local Independence Testing with Application to Dynamic Causal Discovery
Jun 09, 2025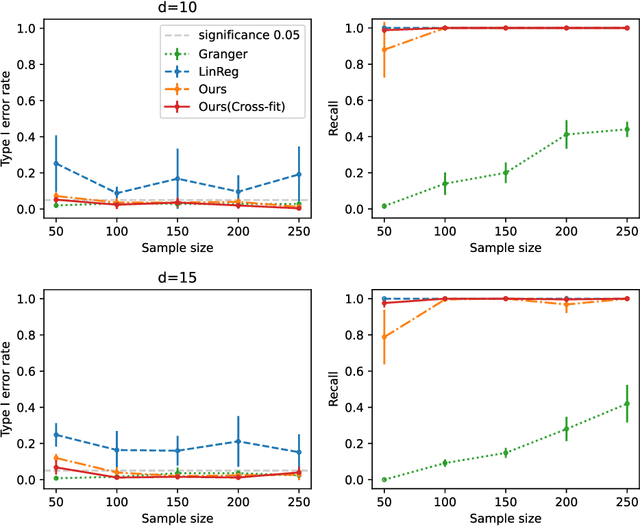
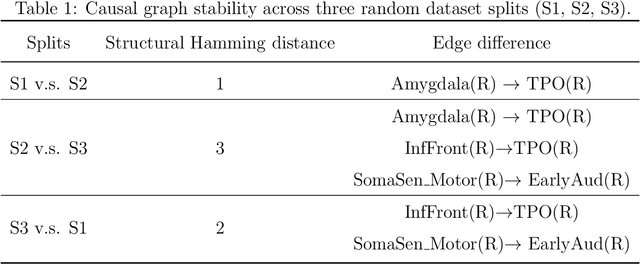
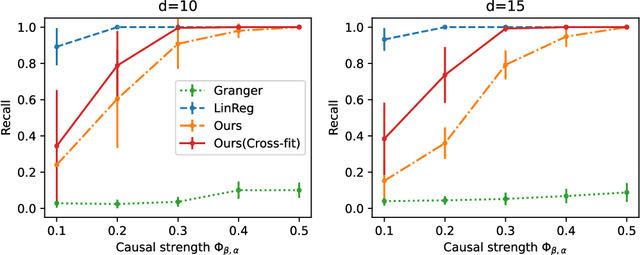
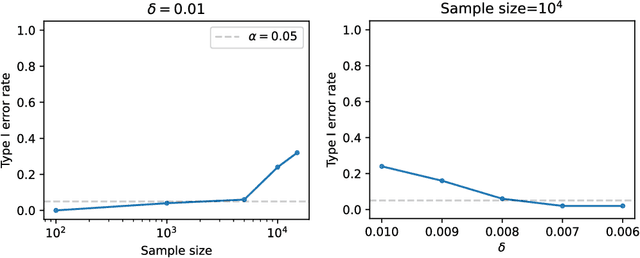
In this note, we extend the conditional local independence testing theory developed in Christgau et al. (2024) to Ito processes. The result can be applied to causal discovery in dynamic systems.
Revisiting Large Language Model Pruning using Neuron Semantic Attribution
Mar 03, 2025
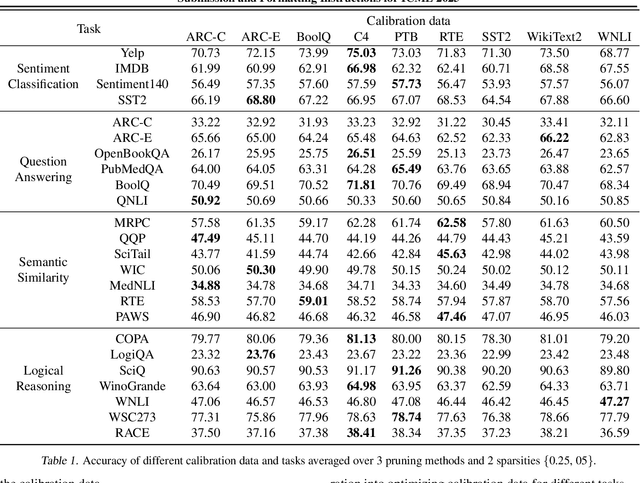

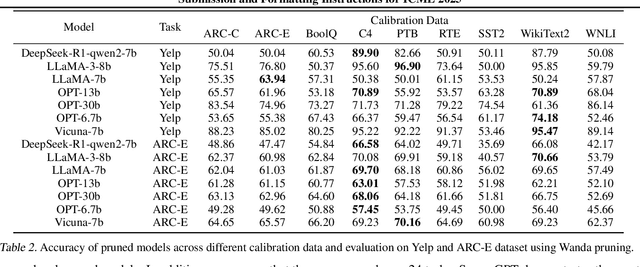
Model pruning technique is vital for accelerating large language models by reducing their size and computational requirements. However, the generalizability of existing pruning methods across diverse datasets and tasks remains unclear. Thus, we conduct extensive evaluations on 24 datasets and 4 tasks using popular pruning methods. Based on these evaluations, we find and then investigate that calibration set greatly affect the performance of pruning methods. In addition, we surprisingly find a significant performance drop of existing pruning methods in sentiment classification tasks. To understand the link between performance drop and pruned neurons, we propose Neuron Semantic Attribution, which learns to associate each neuron with specific semantics. This method first makes the unpruned neurons of LLMs explainable.
A New Formulation of Lipschitz Constrained With Functional Gradient Learning for GANs
Jan 20, 2025This paper introduces a promising alternative method for training Generative Adversarial Networks (GANs) on large-scale datasets with clear theoretical guarantees. GANs are typically learned through a minimax game between a generator and a discriminator, which is known to be empirically unstable. Previous learning paradigms have encountered mode collapse issues without a theoretical solution. To address these challenges, we propose a novel Lipschitz-constrained Functional Gradient GANs learning (Li-CFG) method to stabilize the training of GAN and provide a theoretical foundation for effectively increasing the diversity of synthetic samples by reducing the neighborhood size of the latent vector. Specifically, we demonstrate that the neighborhood size of the latent vector can be reduced by increasing the norm of the discriminator gradient, resulting in enhanced diversity of synthetic samples. To efficiently enlarge the norm of the discriminator gradient, we introduce a novel {\epsilon}-centered gradient penalty that amplifies the norm of the discriminator gradient using the hyper-parameter {\epsilon}. In comparison to other constraints, our method enlarging the discriminator norm, thus obtaining the smallest neighborhood size of the latent vector. Extensive experiments on benchmark datasets for image generation demonstrate the efficacy of the Li-CFG method and the {\epsilon}-centered gradient penalty. The results showcase improved stability and increased diversity of synthetic samples.
Adaptive Pruning of Pretrained Transformer via Differential Inclusions
Jan 06, 2025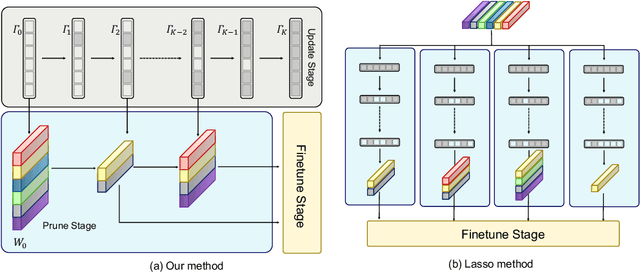
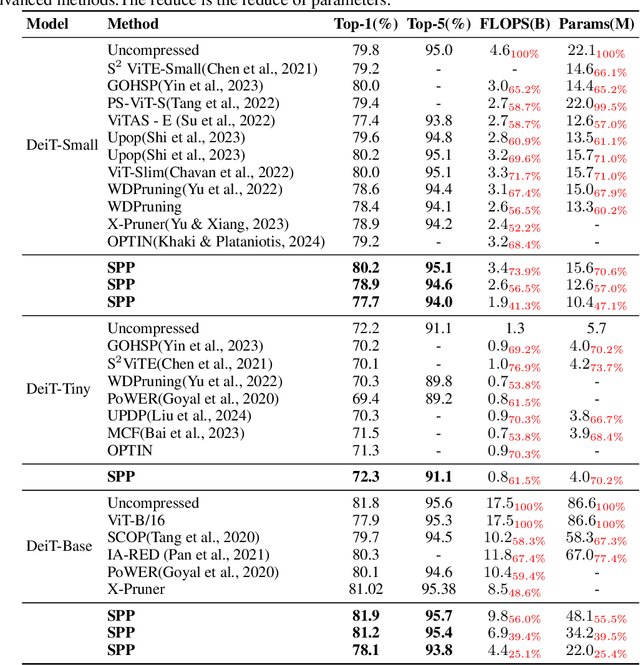
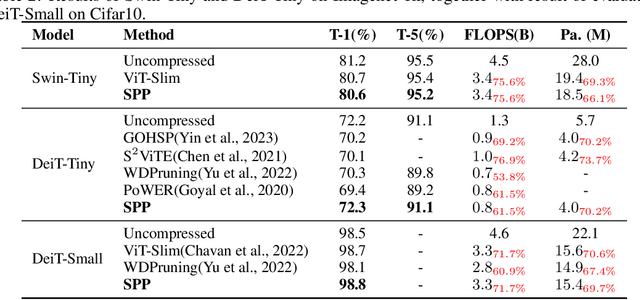
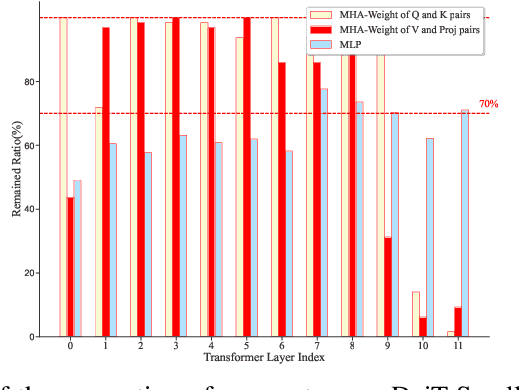
Large transformers have demonstrated remarkable success, making it necessary to compress these models to reduce inference costs while preserving their perfor-mance. Current compression algorithms prune transformers at fixed compression ratios, requiring a unique pruning process for each ratio, which results in high computational costs. In contrast, we propose pruning of pretrained transformers at any desired ratio within a single pruning stage, based on a differential inclusion for a mask parameter. This dynamic can generate the whole regularization solution path of the mask parameter, whose support set identifies the network structure. Therefore, the solution path identifies a Transformer weight family with various sparsity levels, offering greater flexibility and customization. In this paper, we introduce such an effective pruning method, termed SPP (Solution Path Pruning). To achieve effective pruning, we segment the transformers into paired modules, including query-key pairs, value-projection pairs, and sequential linear layers, and apply low-rank compression to these pairs, maintaining the output structure while enabling structural compression within the inner states. Extensive experiments conducted on various well-known transformer backbones have demonstrated the efficacy of SPP.
Robust Network Learning via Inverse Scale Variational Sparsification
Sep 27, 2024



While neural networks have made significant strides in many AI tasks, they remain vulnerable to a range of noise types, including natural corruptions, adversarial noise, and low-resolution artifacts. Many existing approaches focus on enhancing robustness against specific noise types, limiting their adaptability to others. Previous studies have addressed general robustness by adopting a spectral perspective, which tends to blur crucial features like texture and object contours. Our proposed solution, however, introduces an inverse scale variational sparsification framework within a time-continuous inverse scale space formulation. This framework progressively learns finer-scale features by discerning variational differences between pixels, ultimately preserving only large-scale features in the smoothed image. Unlike frequency-based methods, our approach not only removes noise by smoothing small-scale features where corruptions often occur but also retains high-contrast details such as textures and object contours. Moreover, our framework offers simplicity and efficiency in implementation. By integrating this algorithm into neural network training, we guide the model to prioritize learning large-scale features. We show the efficacy of our approach through enhanced robustness against various noise types.
LAC-Net: Linear-Fusion Attention-Guided Convolutional Network for Accurate Robotic Grasping Under the Occlusion
Aug 06, 2024



This paper addresses the challenge of perceiving complete object shapes through visual perception. While prior studies have demonstrated encouraging outcomes in segmenting the visible parts of objects within a scene, amodal segmentation, in particular, has the potential to allow robots to infer the occluded parts of objects. To this end, this paper introduces a new framework that explores amodal segmentation for robotic grasping in cluttered scenes, thus greatly enhancing robotic grasping abilities. Initially, we use a conventional segmentation algorithm to detect the visible segments of the target object, which provides shape priors for completing the full object mask. Particularly, to explore how to utilize semantic features from RGB images and geometric information from depth images, we propose a Linear-fusion Attention-guided Convolutional Network (LAC-Net). LAC-Net utilizes the linear-fusion strategy to effectively fuse this cross-modal data, and then uses the prior visible mask as attention map to guide the network to focus on target feature locations for further complete mask recovery. Using the amodal mask of the target object provides advantages in selecting more accurate and robust grasp points compared to relying solely on the visible segments. The results on different datasets show that our method achieves state-of-the-art performance. Furthermore, the robot experiments validate the feasibility and robustness of this method in the real world. Our code and demonstrations are available on the project page: https://jrryzh.github.io/LAC-Net.
Bayesian Intervention Optimization for Causal Discovery
Jun 16, 2024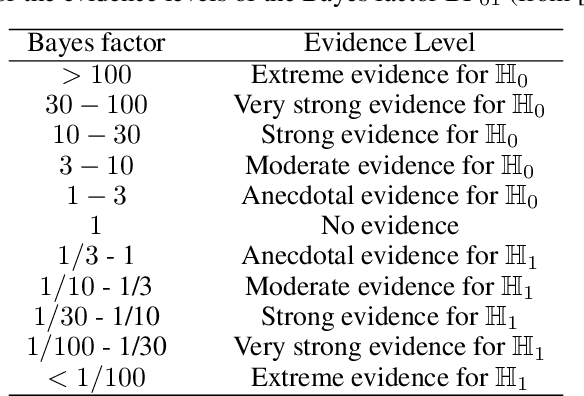
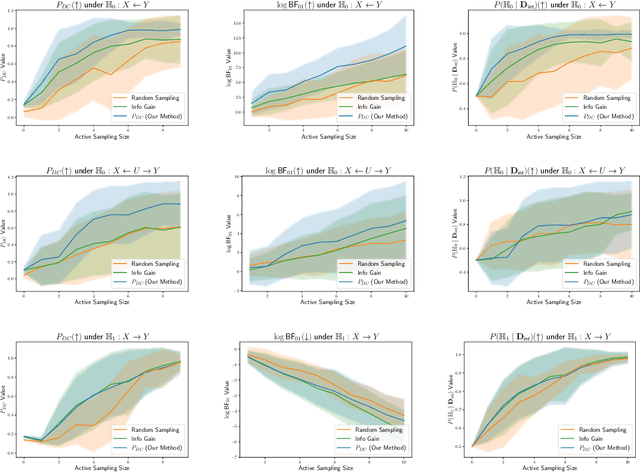
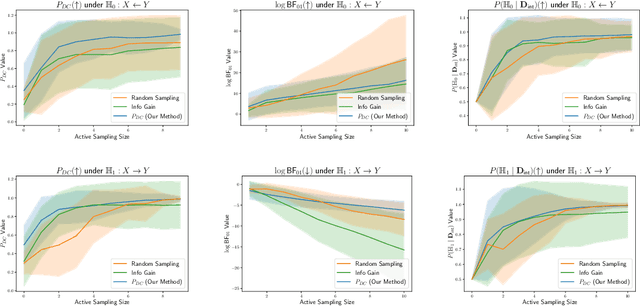
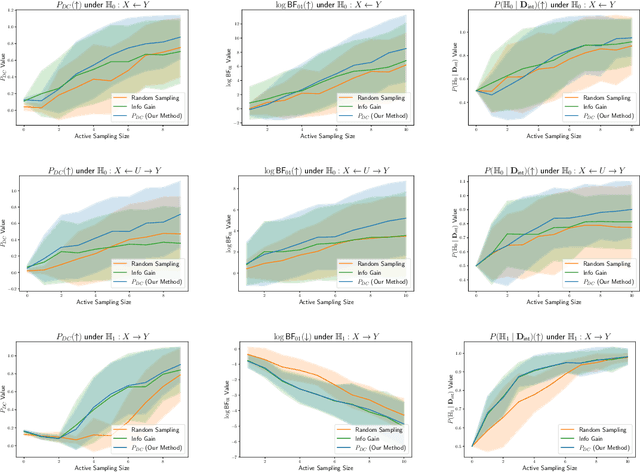
Causal discovery is crucial for understanding complex systems and informing decisions. While observational data can uncover causal relationships under certain assumptions, it often falls short, making active interventions necessary. Current methods, such as Bayesian and graph-theoretical approaches, do not prioritize decision-making and often rely on ideal conditions or information gain, which is not directly related to hypothesis testing. We propose a novel Bayesian optimization-based method inspired by Bayes factors that aims to maximize the probability of obtaining decisive and correct evidence. Our approach uses observational data to estimate causal models under different hypotheses, evaluates potential interventions pre-experimentally, and iteratively updates priors to refine interventions. We demonstrate the effectiveness of our method through various experiments. Our contributions provide a robust framework for efficient causal discovery through active interventions, enhancing the practical application of theoretical advancements.
The Blessings of Multiple Treatments and Outcomes in Treatment Effect Estimation
Oct 14, 2023



Assessing causal effects in the presence of unobserved confounding is a challenging problem. Existing studies leveraged proxy variables or multiple treatments to adjust for the confounding bias. In particular, the latter approach attributes the impact on a single outcome to multiple treatments, allowing estimating latent variables for confounding control. Nevertheless, these methods primarily focus on a single outcome, whereas in many real-world scenarios, there is greater interest in studying the effects on multiple outcomes. Besides, these outcomes are often coupled with multiple treatments. Examples include the intensive care unit (ICU), where health providers evaluate the effectiveness of therapies on multiple health indicators. To accommodate these scenarios, we consider a new setting dubbed as multiple treatments and multiple outcomes. We then show that parallel studies of multiple outcomes involved in this setting can assist each other in causal identification, in the sense that we can exploit other treatments and outcomes as proxies for each treatment effect under study. We proceed with a causal discovery method that can effectively identify such proxies for causal estimation. The utility of our method is demonstrated in synthetic data and sepsis disease.
Exploring Counterfactual Alignment Loss towards Human-centered AI
Oct 03, 2023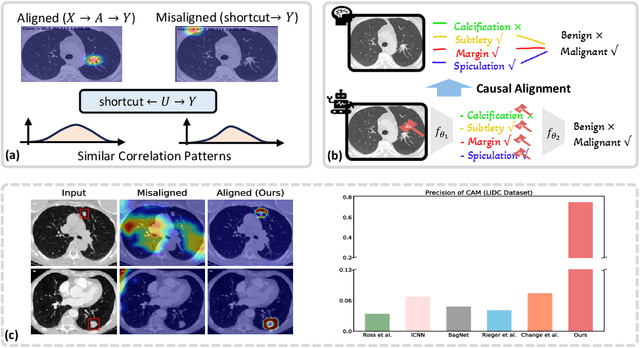
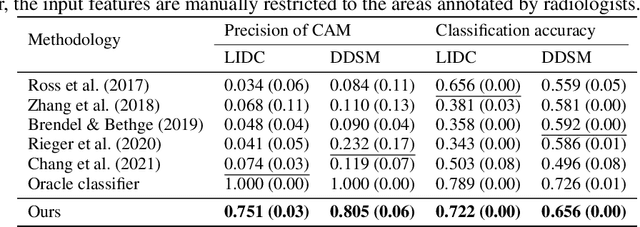
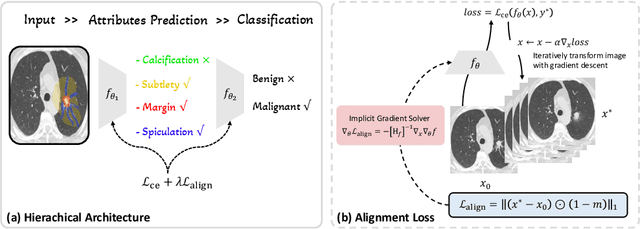

Deep neural networks have demonstrated impressive accuracy in supervised learning tasks. However, their lack of transparency makes it hard for humans to trust their results, especially in safe-critic domains such as healthcare. To address this issue, recent explanation-guided learning approaches proposed to align the gradient-based attention map to image regions annotated by human experts, thereby obtaining an intrinsically human-centered model. However, the attention map these methods are based on may fail to causally attribute the model predictions, thus compromising their validity for alignment. To address this issue, we propose a novel human-centered framework based on counterfactual generation. In particular, we utilize the counterfactual generation's ability for causal attribution to introduce a novel loss called the CounterFactual Alignment (CF-Align) loss. This loss guarantees that the features attributed by the counterfactual generation for the classifier align with the human annotations. To optimize the proposed loss that entails a counterfactual generation with an implicit function form, we leverage the implicit function theorem for backpropagation. Our method is architecture-agnostic and, therefore can be applied to any neural network. We demonstrate the effectiveness of our method on a lung cancer diagnosis dataset, showcasing faithful alignment to humans.
Doubly Robust Proximal Causal Learning for Continuous Treatments
Sep 22, 2023



Proximal causal learning is a promising framework for identifying the causal effect under the existence of unmeasured confounders. Within this framework, the doubly robust (DR) estimator was derived and has shown its effectiveness in estimation, especially when the model assumption is violated. However, the current form of the DR estimator is restricted to binary treatments, while the treatment can be continuous in many real-world applications. The primary obstacle to continuous treatments resides in the delta function present in the original DR estimator, making it infeasible in causal effect estimation and introducing a heavy computational burden in nuisance function estimation. To address these challenges, we propose a kernel-based DR estimator that can well handle continuous treatments. Equipped with its smoothness, we show that its oracle form is a consistent approximation of the influence function. Further, we propose a new approach to efficiently solve the nuisance functions. We then provide a comprehensive convergence analysis in terms of the mean square error. We demonstrate the utility of our estimator on synthetic datasets and real-world applications.