 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActiveVLA: Injecting Active Perception into Vision-Language-Action Models for Precise 3D Robotic Manipulation
Jan 13, 2026Recent advances in robot manipulation have leveraged pre-trained vision-language models (VLMs) and explored integrating 3D spatial signals into these models for effective action prediction, giving rise to the promising vision-language-action (VLA) paradigm. However, most existing approaches overlook the importance of active perception: they typically rely on static, wrist-mounted cameras that provide an end-effector-centric viewpoint. As a result, these models are unable to adaptively select optimal viewpoints or resolutions during task execution, which significantly limits their performance in long-horizon tasks and fine-grained manipulation scenarios. To address these limitations, we propose ActiveVLA, a novel vision-language-action framework that empowers robots with active perception capabilities for high-precision, fine-grained manipulation. ActiveVLA adopts a coarse-to-fine paradigm, dividing the process into two stages: (1) Critical region localization. ActiveVLA projects 3D inputs onto multi-view 2D projections, identifies critical 3D regions, and supports dynamic spatial awareness. (2) Active perception optimization. Drawing on the localized critical regions, ActiveVLA uses an active view selection strategy to choose optimal viewpoints. These viewpoints aim to maximize amodal relevance and diversity while minimizing occlusions. Additionally, ActiveVLA applies a 3D zoom-in to improve resolution in key areas. Together, these steps enable finer-grained active perception for precise manipulation. Extensive experiments demonstrate that ActiveVLA achieves precise 3D manipulation and outperforms state-of-the-art baselines on three simulation benchmarks. Moreover, ActiveVLA transfers seamlessly to real-world scenarios, enabling robots to learn high-precision tasks in complex environments.
TriVLA: A Triple-System-Based Unified Vision-Language-Action Model for General Robot Control
Jul 03, 2025Recent advancements in vision-language models (VLMs) for common-sense reasoning have led to the development of vision-language-action (VLA) models, enabling robots to perform generalized manipulation. Although existing autoregressive VLA methods design a specific architecture like dual-system to leverage large-scale pretrained knowledge, they tend to capture static information, often neglecting the dynamic aspects vital for embodied tasks. To this end, we propose TriVLA, a unified Vision-Language-Action model with a triple-system architecture for general robot control. The vision-language module (System 2) interprets the environment through vision and language instructions. The dynamics perception module (System 3) inherently produces visual representations that encompass both current static information and predicted future dynamics, thereby providing valuable guidance for policy learning. TriVLA utilizes pre-trained VLM model and fine-tunes pre-trained video foundation model on robot datasets along with internet human manipulation data. The subsequent policy learning module (System 1) generates fluid motor actions in real time. Experimental evaluation demonstrates that TriVLA operates at approximately 36 Hz and surpasses state-of-the-art imitation learning baselines on standard simulation benchmarks as well as challenging real-world manipulation tasks.
TriVLA: A Unified Triple-System-Based Unified Vision-Language-Action Model for General Robot Control
Jul 02, 2025Recent advancements in vision-language models (VLMs) for common-sense reasoning have led to the development of vision-language-action (VLA) models, enabling robots to perform generalized manipulation. Although existing autoregressive VLA methods design a specific architecture like dual-system to leverage large-scale pretrained knowledge, they tend to capture static information, often neglecting the dynamic aspects vital for embodied tasks. To this end, we propose TriVLA, a unified Vision-Language-Action model with a triple-system architecture for general robot control. The vision-language module (System 2) interprets the environment through vision and language instructions. The dynamics perception module (System 3) inherently produces visual representations that encompass both current static information and predicted future dynamics, thereby providing valuable guidance for policy learning. TriVLA utilizes pre-trained VLM model and fine-tunes pre-trained video foundation model on robot datasets along with internet human manipulation data. The subsequent policy learning module (System 1) generates fluid motor actions in real time. Experimental evaluation demonstrates that TriVLA operates at approximately 36 Hz and surpasses state-of-the-art imitation learning baselines on standard simulation benchmarks as well as challenging real-world manipulation tasks.
Sequential Multi-Object Grasping with One Dexterous Hand
Mar 12, 2025
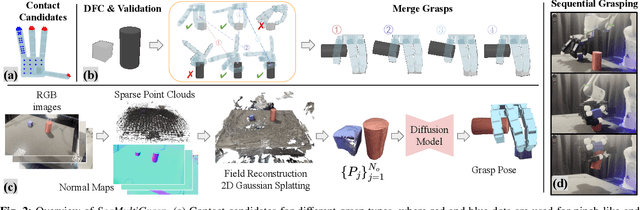

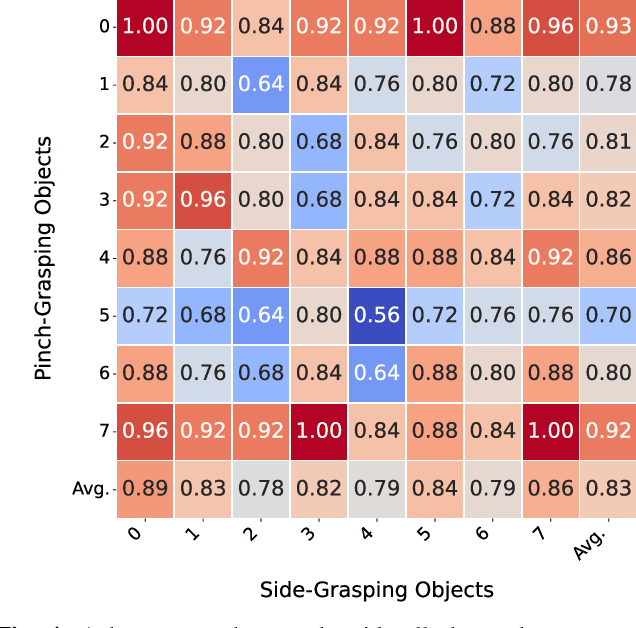
Sequentially grasping multiple objects with multi-fingered hands is common in daily life, where humans can fully leverage the dexterity of their hands to enclose multiple objects. However, the diversity of object geometries and the complex contact interactions required for high-DOF hands to grasp one object while enclosing another make sequential multi-object grasping challenging for robots. In this paper, we propose SeqMultiGrasp, a system for sequentially grasping objects with a four-fingered Allegro Hand. We focus on sequentially grasping two objects, ensuring that the hand fully encloses one object before lifting it and then grasps the second object without dropping the first. Our system first synthesizes single-object grasp candidates, where each grasp is constrained to use only a subset of the hand's links. These grasps are then validated in a physics simulator to ensure stability and feasibility. Next, we merge the validated single-object grasp poses to construct multi-object grasp configurations. For real-world deployment, we train a diffusion model conditioned on point clouds to propose grasp poses, followed by a heuristic-based execution strategy. We test our system using $8 \times 8$ object combinations in simulation and $6 \times 3$ object combinations in real. Our diffusion-based grasp model obtains an average success rate of 65.8% over 1600 simulation trials and 56.7% over 90 real-world trials, suggesting that it is a promising approach for sequential multi-object grasping with multi-fingered hands. Supplementary material is available on our project website: https://hesic73.github.io/SeqMultiGrasp.
SparseGrasp: Robotic Grasping via 3D Semantic Gaussian Splatting from Sparse Multi-View RGB Images
Dec 03, 2024Language-guided robotic grasping is a rapidly advancing field where robots are instructed using human language to grasp specific objects. However, existing methods often depend on dense camera views and struggle to quickly update scenes, limiting their effectiveness in changeable environments. In contrast, we propose SparseGrasp, a novel open-vocabulary robotic grasping system that operates efficiently with sparse-view RGB images and handles scene updates fastly. Our system builds upon and significantly enhances existing computer vision modules in robotic learning. Specifically, SparseGrasp utilizes DUSt3R to generate a dense point cloud as the initialization for 3D Gaussian Splatting (3DGS), maintaining high fidelity even under sparse supervision. Importantly, SparseGrasp incorporates semantic awareness from recent vision foundation models. To further improve processing efficiency, we repurpose Principal Component Analysis (PCA) to compress features from 2D models. Additionally, we introduce a novel render-and-compare strategy that ensures rapid scene updates, enabling multi-turn grasping in changeable environments. Experimental results show that SparseGrasp significantly outperforms state-of-the-art methods in terms of both speed and adaptability, providing a robust solution for multi-turn grasping in changeable environment.
LAC-Net: Linear-Fusion Attention-Guided Convolutional Network for Accurate Robotic Grasping Under the Occlusion
Aug 06, 2024



This paper addresses the challenge of perceiving complete object shapes through visual perception. While prior studies have demonstrated encouraging outcomes in segmenting the visible parts of objects within a scene, amodal segmentation, in particular, has the potential to allow robots to infer the occluded parts of objects. To this end, this paper introduces a new framework that explores amodal segmentation for robotic grasping in cluttered scenes, thus greatly enhancing robotic grasping abilities. Initially, we use a conventional segmentation algorithm to detect the visible segments of the target object, which provides shape priors for completing the full object mask. Particularly, to explore how to utilize semantic features from RGB images and geometric information from depth images, we propose a Linear-fusion Attention-guided Convolutional Network (LAC-Net). LAC-Net utilizes the linear-fusion strategy to effectively fuse this cross-modal data, and then uses the prior visible mask as attention map to guide the network to focus on target feature locations for further complete mask recovery. Using the amodal mask of the target object provides advantages in selecting more accurate and robust grasp points compared to relying solely on the visible segments. The results on different datasets show that our method achieves state-of-the-art performance. Furthermore, the robot experiments validate the feasibility and robustness of this method in the real world. Our code and demonstrations are available on the project page: https://jrryzh.github.io/LAC-Net.