 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-free score-based diffusion for parameter-dependent stochastic dynamical systems
Feb 02, 2026Simulating parameter-dependent stochastic differential equations (SDEs) presents significant computational challenges, as separate high-fidelity simulations are typically required for each parameter value of interest. Despite the success of machine learning methods in learning SDE dynamics, existing approaches either require expensive neural network training for score function estimation or lack the ability to handle continuous parameter dependence. We present a training-free conditional diffusion model framework for learning stochastic flow maps of parameter-dependent SDEs, where both drift and diffusion coefficients depend on physical parameters. The key technical innovation is a joint kernel-weighted Monte Carlo estimator that approximates the conditional score function using trajectory data sampled at discrete parameter values, enabling interpolation across both state space and the continuous parameter domain. Once trained, the resulting generative model produces sample trajectories for any parameter value within the training range without retraining, significantly accelerating parameter studies, uncertainty quantification, and real-time filtering applications. The performance of the proposed approach is demonstrated via three numerical examples of increasing complexity, showing accurate approximation of conditional distributions across varying parameter values.
Robot Learning from a Physical World Model
Nov 10, 2025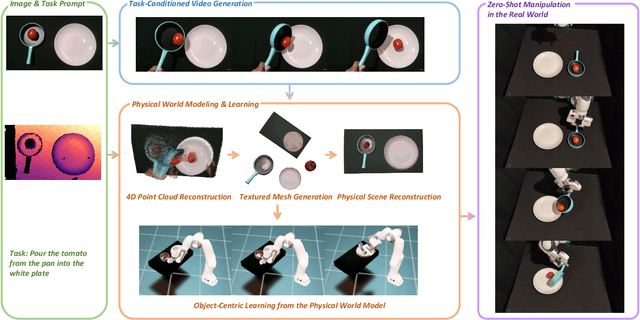

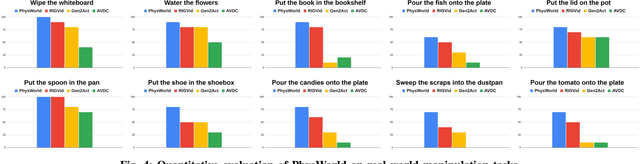

We introduce PhysWorld, a framework that enables robot learning from video generation through physical world modeling. Recent video generation models can synthesize photorealistic visual demonstrations from language commands and images, offering a powerful yet underexplored source of training signals for robotics. However, directly retargeting pixel motions from generated videos to robots neglects physics, often resulting in inaccurate manipulations. PhysWorld addresses this limitation by coupling video generation with physical world reconstruction. Given a single image and a task command, our method generates task-conditioned videos and reconstructs the underlying physical world from the videos, and the generated video motions are grounded into physically accurate actions through object-centric residual reinforcement learning with the physical world model. This synergy transforms implicit visual guidance into physically executable robotic trajectories, eliminating the need for real robot data collection and enabling zero-shot generalizable robotic manipulation. Experiments on diverse real-world tasks demonstrate that PhysWorld substantially improves manipulation accuracy compared to previous approaches. Visit \href{https://pointscoder.github.io/PhysWorld_Web/}{the project webpage} for details.
Automated CAD Modeling Sequence Generation from Text Descriptions via Transformer-Based Large Language Models
May 26, 2025Designing complex computer-aided design (CAD) models is often time-consuming due to challenges such as computational inefficiency and the difficulty of generating precise models. We propose a novel language-guided framework for industrial design automation to address these issues, integrating large language models (LLMs) with computer-automated design (CAutoD).Through this framework, CAD models are automatically generated from parameters and appearance descriptions, supporting the automation of design tasks during the detailed CAD design phase. Our approach introduces three key innovations: (1) a semi-automated data annotation pipeline that leverages LLMs and vision-language large models (VLLMs) to generate high-quality parameters and appearance descriptions; (2) a Transformer-based CAD generator (TCADGen) that predicts modeling sequences via dual-channel feature aggregation; (3) an enhanced CAD modeling generation model, called CADLLM, that is designed to refine the generated sequences by incorporating the confidence scores from TCADGen. Experimental results demonstrate that the proposed approach outperforms traditional methods in both accuracy and efficiency, providing a powerful tool for automating industrial workflows and generating complex CAD models from textual prompts. The code is available at https://jianxliao.github.io/cadllm-page/
Sequential Multi-Object Grasping with One Dexterous Hand
Mar 12, 2025
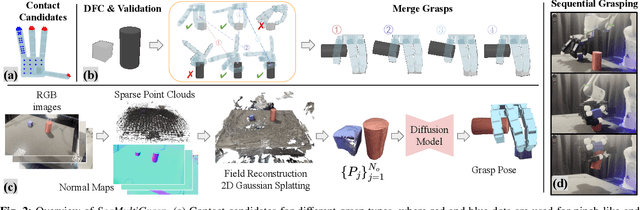

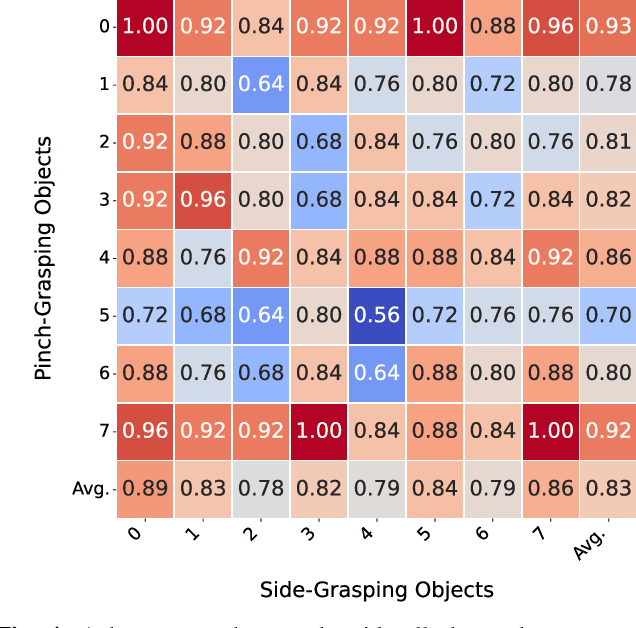
Sequentially grasping multiple objects with multi-fingered hands is common in daily life, where humans can fully leverage the dexterity of their hands to enclose multiple objects. However, the diversity of object geometries and the complex contact interactions required for high-DOF hands to grasp one object while enclosing another make sequential multi-object grasping challenging for robots. In this paper, we propose SeqMultiGrasp, a system for sequentially grasping objects with a four-fingered Allegro Hand. We focus on sequentially grasping two objects, ensuring that the hand fully encloses one object before lifting it and then grasps the second object without dropping the first. Our system first synthesizes single-object grasp candidates, where each grasp is constrained to use only a subset of the hand's links. These grasps are then validated in a physics simulator to ensure stability and feasibility. Next, we merge the validated single-object grasp poses to construct multi-object grasp configurations. For real-world deployment, we train a diffusion model conditioned on point clouds to propose grasp poses, followed by a heuristic-based execution strategy. We test our system using $8 \times 8$ object combinations in simulation and $6 \times 3$ object combinations in real. Our diffusion-based grasp model obtains an average success rate of 65.8% over 1600 simulation trials and 56.7% over 90 real-world trials, suggesting that it is a promising approach for sequential multi-object grasping with multi-fingered hands. Supplementary material is available on our project website: https://hesic73.github.io/SeqMultiGrasp.
VoxAct-B: Voxel-Based Acting and Stabilizing Policy for Bimanual Manipulation
Jul 04, 2024



Bimanual manipulation is critical to many robotics applications. In contrast to single-arm manipulation, bimanual manipulation tasks are challenging due to higher-dimensional action spaces. Prior works leverage large amounts of data and primitive actions to address this problem, but may suffer from sample inefficiency and limited generalization across various tasks. To this end, we propose VoxAct-B, a language-conditioned, voxel-based method that leverages Vision Language Models (VLMs) to prioritize key regions within the scene and reconstruct a voxel grid. We provide this voxel grid to our bimanual manipulation policy to learn acting and stabilizing actions. This approach enables more efficient policy learning from voxels and is generalizable to different tasks. In simulation, we show that VoxAct-B outperforms strong baselines on fine-grained bimanual manipulation tasks. Furthermore, we demonstrate VoxAct-B on real-world $\texttt{Open Drawer}$ and $\texttt{Open Jar}$ tasks using two UR5s. Code, data, and videos will be available at https://voxact-b.github.io.