 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeColosseum V2: Benchmarking Generalization for Vision Language Action Models
May 26, 2026Vision-Language-Action (VLA) models demonstrate promising generalization in robotic manipulation, driven by advances in large-scale vision and language pre-training. This progress can be misleading. Despite the zero-shot perception and language capabilities of VLAs, their overall task performance often degrades under distribution shifts, revealing gaps in how these systems translate high-level understanding into robust behavior. To systematically study this gap, we introduce Colosseum V2, a large-scale simulation benchmark for evaluating VLA generalization in robot learning across diverse conditions. The benchmark comprises 28 tasks spanning 13 task categories and two robot morphologies, covering a wide range of manipulation primitives and long-horizon behaviors. Built on the ManiSkill simulator, Colosseum V2 enables fast, GPU-parallelized evaluation and supports both in-domain and out-of-domain testing at scale. We evaluate state-of-the-art methods, including Action Chunking Transformers (ACT) and Pi0.5, and reveal limitations in both base performance and generalization. We demonstrate strong correlations between simulation and real-world metrics that support the ecological validity of the benchmark. By standardizing tasks, metrics, and evaluation protocols within a unified benchmark, Colosseum V2 enables reproducible and fair comparisons, reduced evaluation overhead, and accelerated progress toward general-purpose robot policies.
CRAFT: Video Diffusion for Bimanual Robot Data Generation
Apr 04, 2026Bimanual robot learning from demonstrations is fundamentally limited by the cost and narrow visual diversity of real-world data, which constrains policy robustness across viewpoints, object configurations, and embodiments. We present Canny-guided Robot Data Generation using Video Diffusion Transformers (CRAFT), a video diffusion-based framework for scalable bimanual demonstration generation that synthesizes temporally coherent manipulation videos while producing action labels. By conditioning video diffusion on edge-based structural cues extracted from simulator-generated trajectories, CRAFT produces physically plausible trajectory variations and supports a unified augmentation pipeline spanning object pose changes, camera viewpoints, lighting and background variations, cross-embodiment transfer, and multi-view synthesis. We leverage a pre-trained video diffusion model to convert simulated videos, along with action labels from the simulation trajectories, into action-consistent demonstrations. Starting from only a few real-world demonstrations, CRAFT generates a large, visually diverse set of photorealistic training data, bypassing the need to replay demonstrations on the real robot (Sim2Real). Across simulated and real-world bimanual tasks, CRAFT improves success rates over existing augmentation strategies and straightforward data scaling, demonstrating that diffusion-based video generation can substantially expand demonstration diversity and improve generalization for dual-arm manipulation tasks. Our project website is available at: https://craftaug.github.io/
Zero-Shot Visual Generalization in Robot Manipulation
May 16, 2025Training vision-based manipulation policies that are robust across diverse visual environments remains an important and unresolved challenge in robot learning. Current approaches often sidestep the problem by relying on invariant representations such as point clouds and depth, or by brute-forcing generalization through visual domain randomization and/or large, visually diverse datasets. Disentangled representation learning - especially when combined with principles of associative memory - has recently shown promise in enabling vision-based reinforcement learning policies to be robust to visual distribution shifts. However, these techniques have largely been constrained to simpler benchmarks and toy environments. In this work, we scale disentangled representation learning and associative memory to more visually and dynamically complex manipulation tasks and demonstrate zero-shot adaptability to visual perturbations in both simulation and on real hardware. We further extend this approach to imitation learning, specifically Diffusion Policy, and empirically show significant gains in visual generalization compared to state-of-the-art imitation learning methods. Finally, we introduce a novel technique adapted from the model equivariance literature that transforms any trained neural network policy into one invariant to 2D planar rotations, making our policy not only visually robust but also resilient to certain camera perturbations. We believe that this work marks a significant step towards manipulation policies that are not only adaptable out of the box, but also robust to the complexities and dynamical nature of real-world deployment. Supplementary videos are available at https://sites.google.com/view/vis-gen-robotics/home.
D-CODA: Diffusion for Coordinated Dual-Arm Data Augmentation
May 08, 2025Learning bimanual manipulation is challenging due to its high dimensionality and tight coordination required between two arms. Eye-in-hand imitation learning, which uses wrist-mounted cameras, simplifies perception by focusing on task-relevant views. However, collecting diverse demonstrations remains costly, motivating the need for scalable data augmentation. While prior work has explored visual augmentation in single-arm settings, extending these approaches to bimanual manipulation requires generating viewpoint-consistent observations across both arms and producing corresponding action labels that are both valid and feasible. In this work, we propose Diffusion for COordinated Dual-arm Data Augmentation (D-CODA), a method for offline data augmentation tailored to eye-in-hand bimanual imitation learning that trains a diffusion model to synthesize novel, viewpoint-consistent wrist-camera images for both arms while simultaneously generating joint-space action labels. It employs constrained optimization to ensure that augmented states involving gripper-to-object contacts adhere to constraints suitable for bimanual coordination. We evaluate D-CODA on 5 simulated and 3 real-world tasks. Our results across 2250 simulation trials and 300 real-world trials demonstrate that it outperforms baselines and ablations, showing its potential for scalable data augmentation in eye-in-hand bimanual manipulation. Our project website is at: https://dcodaaug.github.io/D-CODA/.
VoxAct-B: Voxel-Based Acting and Stabilizing Policy for Bimanual Manipulation
Jul 04, 2024



Bimanual manipulation is critical to many robotics applications. In contrast to single-arm manipulation, bimanual manipulation tasks are challenging due to higher-dimensional action spaces. Prior works leverage large amounts of data and primitive actions to address this problem, but may suffer from sample inefficiency and limited generalization across various tasks. To this end, we propose VoxAct-B, a language-conditioned, voxel-based method that leverages Vision Language Models (VLMs) to prioritize key regions within the scene and reconstruct a voxel grid. We provide this voxel grid to our bimanual manipulation policy to learn acting and stabilizing actions. This approach enables more efficient policy learning from voxels and is generalizable to different tasks. In simulation, we show that VoxAct-B outperforms strong baselines on fine-grained bimanual manipulation tasks. Furthermore, we demonstrate VoxAct-B on real-world $\texttt{Open Drawer}$ and $\texttt{Open Jar}$ tasks using two UR5s. Code, data, and videos will be available at https://voxact-b.github.io.
VLN-Video: Utilizing Driving Videos for Outdoor Vision-and-Language Navigation
Feb 07, 2024



Outdoor Vision-and-Language Navigation (VLN) requires an agent to navigate through realistic 3D outdoor environments based on natural language instructions. The performance of existing VLN methods is limited by insufficient diversity in navigation environments and limited training data. To address these issues, we propose VLN-Video, which utilizes the diverse outdoor environments present in driving videos in multiple cities in the U.S. augmented with automatically generated navigation instructions and actions to improve outdoor VLN performance. VLN-Video combines the best of intuitive classical approaches and modern deep learning techniques, using template infilling to generate grounded navigation instructions, combined with an image rotation similarity-based navigation action predictor to obtain VLN style data from driving videos for pretraining deep learning VLN models. We pre-train the model on the Touchdown dataset and our video-augmented dataset created from driving videos with three proxy tasks: Masked Language Modeling, Instruction and Trajectory Matching, and Next Action Prediction, so as to learn temporally-aware and visually-aligned instruction representations. The learned instruction representation is adapted to the state-of-the-art navigator when fine-tuning on the Touchdown dataset. Empirical results demonstrate that VLN-Video significantly outperforms previous state-of-the-art models by 2.1% in task completion rate, achieving a new state-of-the-art on the Touchdown dataset.
Alexa, play with robot: Introducing the First Alexa Prize SimBot Challenge on Embodied AI
Aug 09, 2023



The Alexa Prize program has empowered numerous university students to explore, experiment, and showcase their talents in building conversational agents through challenges like the SocialBot Grand Challenge and the TaskBot Challenge. As conversational agents increasingly appear in multimodal and embodied contexts, it is important to explore the affordances of conversational interaction augmented with computer vision and physical embodiment. This paper describes the SimBot Challenge, a new challenge in which university teams compete to build robot assistants that complete tasks in a simulated physical environment. This paper provides an overview of the SimBot Challenge, which included both online and offline challenge phases. We describe the infrastructure and support provided to the teams including Alexa Arena, the simulated environment, and the ML toolkit provided to teams to accelerate their building of vision and language models. We summarize the approaches the participating teams took to overcome research challenges and extract key lessons learned. Finally, we provide analysis of the performance of the competing SimBots during the competition.
Exploiting Generalization in Offline Reinforcement Learning via Unseen State Augmentations
Aug 07, 2023



Offline reinforcement learning (RL) methods strike a balance between exploration and exploitation by conservative value estimation -- penalizing values of unseen states and actions. Model-free methods penalize values at all unseen actions, while model-based methods are able to further exploit unseen states via model rollouts. However, such methods are handicapped in their ability to find unseen states far away from the available offline data due to two factors -- (a) very short rollout horizons in models due to cascading model errors, and (b) model rollouts originating solely from states observed in offline data. We relax the second assumption and present a novel unseen state augmentation strategy to allow exploitation of unseen states where the learned model and value estimates generalize. Our strategy finds unseen states by value-informed perturbations of seen states followed by filtering out states with epistemic uncertainty estimates too high (high error) or too low (too similar to seen data). We observe improved performance in several offline RL tasks and find that our augmentation strategy consistently leads to overall lower average dataset Q-value estimates i.e. more conservative Q-value estimates than a baseline.
Towards Efficient MPPI Trajectory Generation with Unscented Guidance: U-MPPI Control Strategy
Jun 21, 2023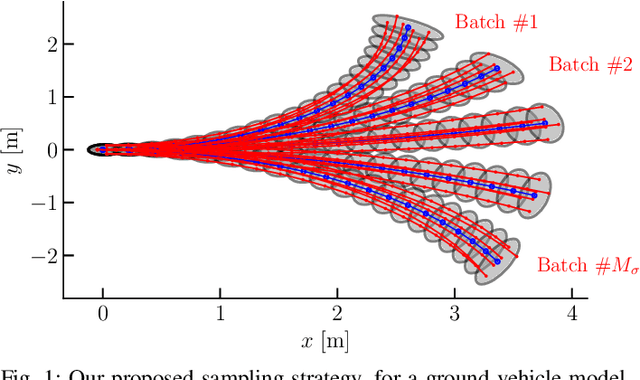

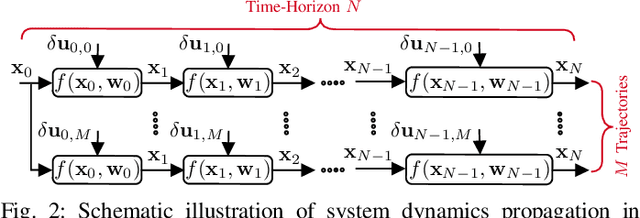
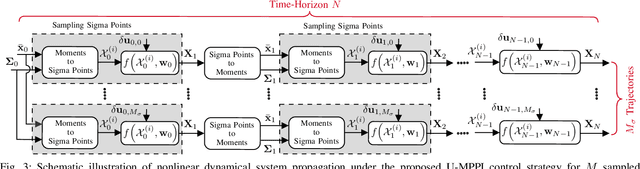
The classical Model Predictive Path Integral (MPPI) control framework lacks reliable safety guarantees since it relies on a risk-neutral trajectory evaluation technique, which can present challenges for safety-critical applications such as autonomous driving. Additionally, if the majority of MPPI sampled trajectories concentrate in high-cost regions, it may generate an infeasible control sequence. To address this challenge, we propose the U-MPPI control strategy, a novel methodology that can effectively manage system uncertainties while integrating a more efficient trajectory sampling strategy. The core concept is to leverage the Unscented Transform (UT) to propagate not only the mean but also the covariance of the system dynamics, going beyond the traditional MPPI method. As a result, it introduces a novel and more efficient trajectory sampling strategy, significantly enhancing state-space exploration and ultimately reducing the risk of being trapped in local minima. Furthermore, by leveraging the uncertainty information provided by UT, we incorporate a risk-sensitive cost function that explicitly accounts for risk or uncertainty throughout the trajectory evaluation process, resulting in a more resilient control system capable of handling uncertain conditions. By conducting extensive simulations of 2D aggressive autonomous navigation in both known and unknown cluttered environments, we verify the efficiency and robustness of our proposed U-MPPI control strategy compared to the baseline MPPI. We further validate the practicality of U-MPPI through real-world demonstrations in unknown cluttered environments, showcasing its superior ability to incorporate both the UT and local costmap into the optimization problem without introducing additional complexity.
Proximal Policy Gradient Arborescence for Quality Diversity Reinforcement Learning
May 23, 2023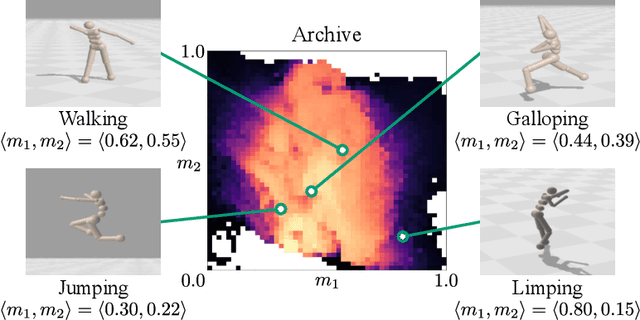
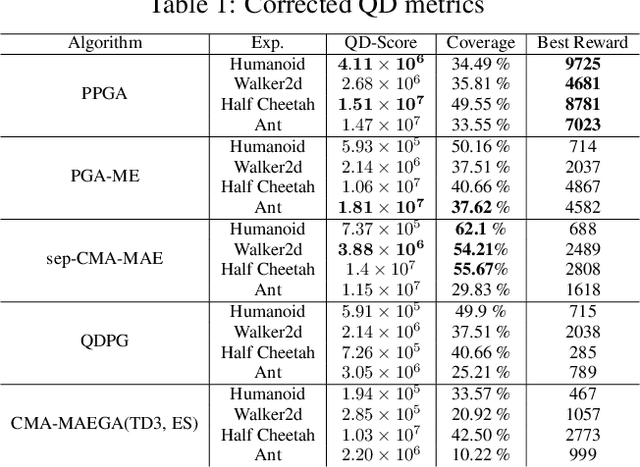
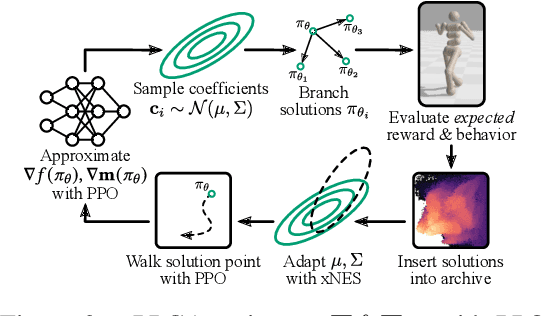
Training generally capable agents that perform well in unseen dynamic environments is a long-term goal of robot learning. Quality Diversity Reinforcement Learning (QD-RL) is an emerging class of reinforcement learning (RL) algorithms that blend insights from Quality Diversity (QD) and RL to produce a collection of high performing and behaviorally diverse policies with respect to a behavioral embedding. Existing QD-RL approaches have thus far taken advantage of sample-efficient off-policy RL algorithms. However, recent advances in high-throughput, massively parallelized robotic simulators have opened the door for algorithms that can take advantage of such parallelism, and it is unclear how to scale existing off-policy QD-RL methods to these new data-rich regimes. In this work, we take the first steps to combine on-policy RL methods, specifically Proximal Policy Optimization (PPO), that can leverage massive parallelism, with QD, and propose a new QD-RL method with these high-throughput simulators and on-policy training in mind. Our proposed Proximal Policy Gradient Arborescence (PPGA) algorithm yields a 4x improvement over baselines on the challenging humanoid domain.