 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntropy-Preserving Reinforcement Learning
Mar 12, 2026Policy gradient algorithms have driven many recent advancements in language model reasoning. An appealing property is their ability to learn from exploration on their own trajectories, a process crucial for fostering diverse and creative solutions. As we show in this paper, many policy gradient algorithms naturally reduce the entropy -- and thus the diversity of explored trajectories -- as part of training, yielding a policy increasingly limited in its ability to explore. In this paper, we argue that entropy should be actively monitored and controlled throughout training. We formally analyze the contributions of leading policy gradient objectives on entropy dynamics, identify empirical factors (such as numerical precision) that significantly impact entropy behavior, and propose explicit mechanisms for entropy control. These include REPO, a family of algorithms that modify the advantage function to regulate entropy, and ADAPO, an adaptive asymmetric clipping approach. Models trained with our entropy-preserving methods maintain diversity throughout training, yielding final policies that are more performant and retain their trainability for sequential learning in new environments.
* Published at ICLR 2026
Robust Autonomy Emerges from Self-Play
Feb 05, 2025Self-play has powered breakthroughs in two-player and multi-player games. Here we show that self-play is a surprisingly effective strategy in another domain. We show that robust and naturalistic driving emerges entirely from self-play in simulation at unprecedented scale -- 1.6~billion~km of driving. This is enabled by Gigaflow, a batched simulator that can synthesize and train on 42 years of subjective driving experience per hour on a single 8-GPU node. The resulting policy achieves state-of-the-art performance on three independent autonomous driving benchmarks. The policy outperforms the prior state of the art when tested on recorded real-world scenarios, amidst human drivers, without ever seeing human data during training. The policy is realistic when assessed against human references and achieves unprecedented robustness, averaging 17.5 years of continuous driving between incidents in simulation.
Reinforcement Learning for Long-Horizon Interactive LLM Agents
Feb 04, 2025Interactive digital agents (IDAs) leverage APIs of stateful digital environments to perform tasks in response to user requests. While IDAs powered by instruction-tuned large language models (LLMs) can react to feedback from interface invocations in multi-step exchanges, they have not been trained in their respective digital environments. Prior methods accomplish less than half of tasks in sophisticated benchmarks such as AppWorld. We present a reinforcement learning (RL) approach that trains IDAs directly in their target environments. We formalize this training as a partially observable Markov decision process and derive LOOP, a data- and memory-efficient variant of proximal policy optimization. LOOP uses no value network and maintains exactly one copy of the underlying LLM in memory, making its implementation straightforward and as memory-efficient as fine-tuning a single LLM. A 32-billion-parameter agent trained with LOOP in the AppWorld environment outperforms the much larger OpenAI o1 agent by 9 percentage points (15% relative). To our knowledge, this is the first reported application of RL to IDAs that interact with a stateful, multi-domain, multi-app environment via direct API calls. Our analysis sheds light on the effectiveness of RL in this area, showing that the agent learns to consult the API documentation, avoid unwarranted assumptions, minimize confabulation, and recover from setbacks.
QuadSwarm: A Modular Multi-Quadrotor Simulator for Deep Reinforcement Learning with Direct Thrust Control
Jun 15, 2023Reinforcement learning (RL) has shown promise in creating robust policies for robotics tasks. However, contemporary RL algorithms are data-hungry, often requiring billions of environment transitions to train successful policies. This necessitates the use of fast and highly-parallelizable simulators. In addition to speed, such simulators need to model the physics of the robots and their interaction with the environment to a level acceptable for transferring policies learned in simulation to reality. We present QuadSwarm, a fast, reliable simulator for research in single and multi-robot RL for quadrotors that addresses both issues. QuadSwarm, with fast forward-dynamics propagation decoupled from rendering, is designed to be highly parallelizable such that throughput scales linearly with additional compute. It provides multiple components tailored toward multi-robot RL, including diverse training scenarios, and provides domain randomization to facilitate the development and sim2real transfer of multi-quadrotor control policies. Initial experiments suggest that QuadSwarm achieves over 48,500 simulation samples per second (SPS) on a single quadrotor and over 62,000 SPS on eight quadrotors on a 16-core CPU. The code can be found in https://github.com/Zhehui-Huang/quad-swarm-rl.
Proximal Policy Gradient Arborescence for Quality Diversity Reinforcement Learning
May 23, 2023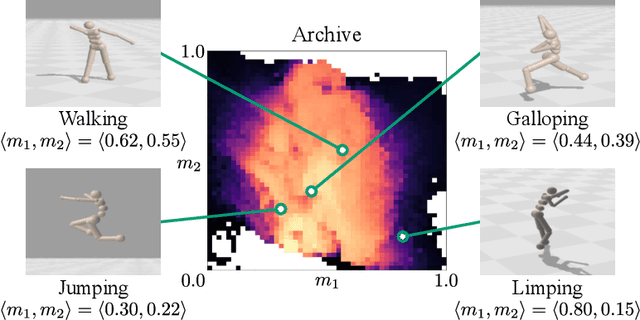
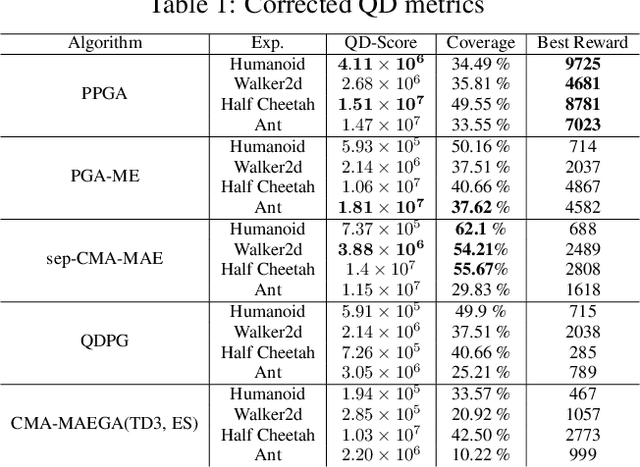
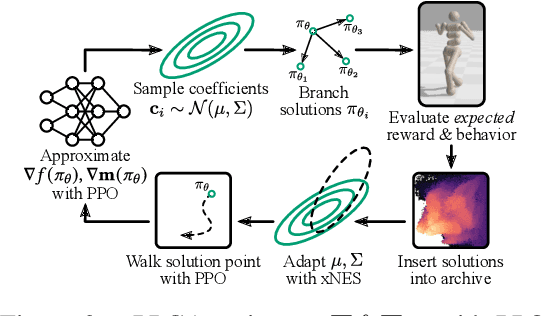
Training generally capable agents that perform well in unseen dynamic environments is a long-term goal of robot learning. Quality Diversity Reinforcement Learning (QD-RL) is an emerging class of reinforcement learning (RL) algorithms that blend insights from Quality Diversity (QD) and RL to produce a collection of high performing and behaviorally diverse policies with respect to a behavioral embedding. Existing QD-RL approaches have thus far taken advantage of sample-efficient off-policy RL algorithms. However, recent advances in high-throughput, massively parallelized robotic simulators have opened the door for algorithms that can take advantage of such parallelism, and it is unclear how to scale existing off-policy QD-RL methods to these new data-rich regimes. In this work, we take the first steps to combine on-policy RL methods, specifically Proximal Policy Optimization (PPO), that can leverage massive parallelism, with QD, and propose a new QD-RL method with these high-throughput simulators and on-policy training in mind. Our proposed Proximal Policy Gradient Arborescence (PPGA) algorithm yields a 4x improvement over baselines on the challenging humanoid domain.
DexPBT: Scaling up Dexterous Manipulation for Hand-Arm Systems with Population Based Training
May 20, 2023



In this work, we propose algorithms and methods that enable learning dexterous object manipulation using simulated one- or two-armed robots equipped with multi-fingered hand end-effectors. Using a parallel GPU-accelerated physics simulator (Isaac Gym), we implement challenging tasks for these robots, including regrasping, grasp-and-throw, and object reorientation. To solve these problems we introduce a decentralized Population-Based Training (PBT) algorithm that allows us to massively amplify the exploration capabilities of deep reinforcement learning. We find that this method significantly outperforms regular end-to-end learning and is able to discover robust control policies in challenging tasks. Video demonstrations of learned behaviors and the code can be found at https://sites.google.com/view/dexpbt
DeXtreme: Transfer of Agile In-hand Manipulation from Simulation to Reality
Oct 25, 2022Recent work has demonstrated the ability of deep reinforcement learning (RL) algorithms to learn complex robotic behaviours in simulation, including in the domain of multi-fingered manipulation. However, such models can be challenging to transfer to the real world due to the gap between simulation and reality. In this paper, we present our techniques to train a) a policy that can perform robust dexterous manipulation on an anthropomorphic robot hand and b) a robust pose estimator suitable for providing reliable real-time information on the state of the object being manipulated. Our policies are trained to adapt to a wide range of conditions in simulation. Consequently, our vision-based policies significantly outperform the best vision policies in the literature on the same reorientation task and are competitive with policies that are given privileged state information via motion capture systems. Our work reaffirms the possibilities of sim-to-real transfer for dexterous manipulation in diverse kinds of hardware and simulator setups, and in our case, with the Allegro Hand and Isaac Gym GPU-based simulation. Furthermore, it opens up possibilities for researchers to achieve such results with commonly-available, affordable robot hands and cameras. Videos of the resulting policy and supplementary information, including experiments and demos, can be found at \url{https://dextreme.org/}
Decentralized Control of Quadrotor Swarms with End-to-end Deep Reinforcement Learning
Sep 16, 2021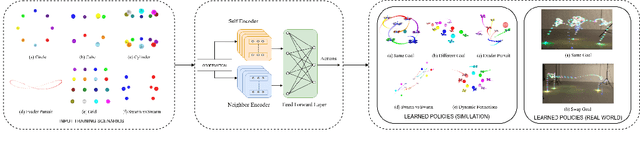
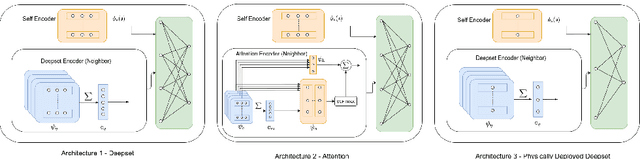

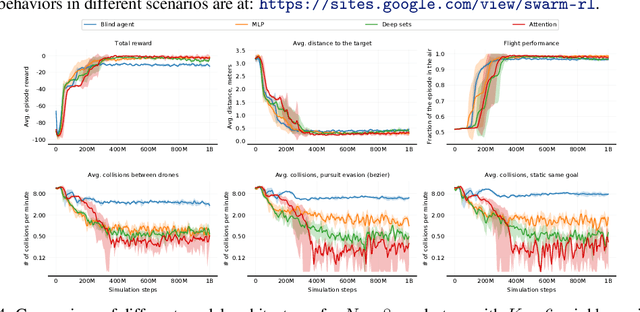
We demonstrate the possibility of learning drone swarm controllers that are zero-shot transferable to real quadrotors via large-scale multi-agent end-to-end reinforcement learning. We train policies parameterized by neural networks that are capable of controlling individual drones in a swarm in a fully decentralized manner. Our policies, trained in simulated environments with realistic quadrotor physics, demonstrate advanced flocking behaviors, perform aggressive maneuvers in tight formations while avoiding collisions with each other, break and re-establish formations to avoid collisions with moving obstacles, and efficiently coordinate in pursuit-evasion tasks. We analyze, in simulation, how different model architectures and parameters of the training regime influence the final performance of neural swarms. We demonstrate the successful deployment of the model learned in simulation to highly resource-constrained physical quadrotors performing stationkeeping and goal swapping behaviors. Code and video demonstrations are available at the project website https://sites.google.com/view/swarm-rl.
Megaverse: Simulating Embodied Agents at One Million Experiences per Second
Jul 21, 2021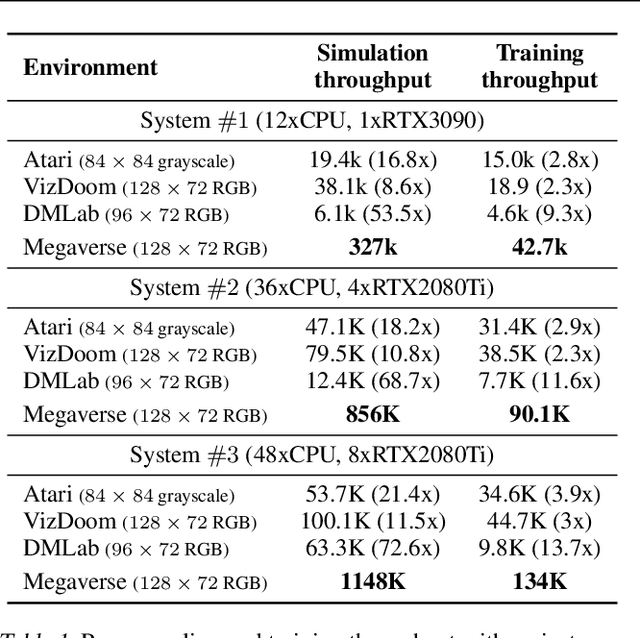
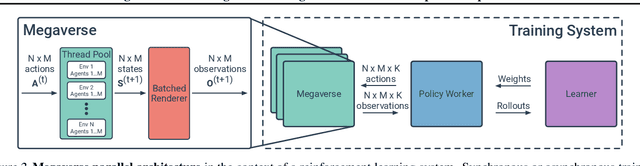
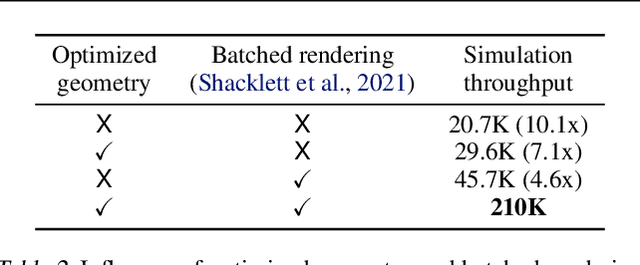
We present Megaverse, a new 3D simulation platform for reinforcement learning and embodied AI research. The efficient design of our engine enables physics-based simulation with high-dimensional egocentric observations at more than 1,000,000 actions per second on a single 8-GPU node. Megaverse is up to 70x faster than DeepMind Lab in fully-shaded 3D scenes with interactive objects. We achieve this high simulation performance by leveraging batched simulation, thereby taking full advantage of the massive parallelism of modern GPUs. We use Megaverse to build a new benchmark that consists of several single-agent and multi-agent tasks covering a variety of cognitive challenges. We evaluate model-free RL on this benchmark to provide baselines and facilitate future research. The source code is available at https://www.megaverse.info
Agents that Listen: High-Throughput Reinforcement Learning with Multiple Sensory Systems
Jul 05, 2021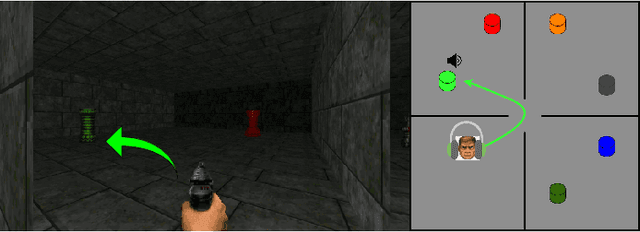
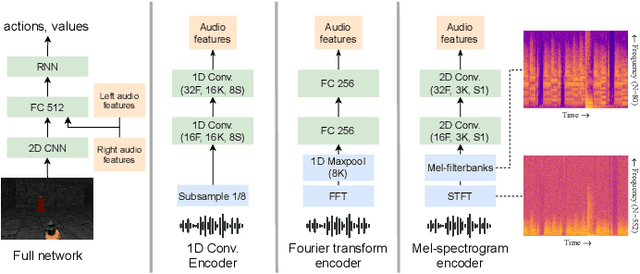

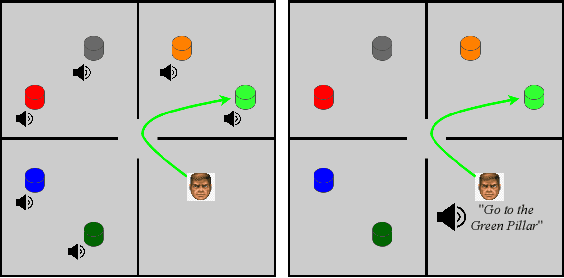
Humans and other intelligent animals evolved highly sophisticated perception systems that combine multiple sensory modalities. On the other hand, state-of-the-art artificial agents rely mostly on visual inputs or structured low-dimensional observations provided by instrumented environments. Learning to act based on combined visual and auditory inputs is still a new topic of research that has not been explored beyond simple scenarios. To facilitate progress in this area we introduce a new version of VizDoom simulator to create a highly efficient learning environment that provides raw audio observations. We study the performance of different model architectures in a series of tasks that require the agent to recognize sounds and execute instructions given in natural language. Finally, we train our agent to play the full game of Doom and find that it can consistently defeat a traditional vision-based adversary. We are currently in the process of merging the augmented simulator with the main ViZDoom code repository. Video demonstrations and experiment code can be found at https://sites.google.com/view/sound-rl.