 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Autonomy Emerges from Self-Play
Feb 05, 2025Self-play has powered breakthroughs in two-player and multi-player games. Here we show that self-play is a surprisingly effective strategy in another domain. We show that robust and naturalistic driving emerges entirely from self-play in simulation at unprecedented scale -- 1.6~billion~km of driving. This is enabled by Gigaflow, a batched simulator that can synthesize and train on 42 years of subjective driving experience per hour on a single 8-GPU node. The resulting policy achieves state-of-the-art performance on three independent autonomous driving benchmarks. The policy outperforms the prior state of the art when tested on recorded real-world scenarios, amidst human drivers, without ever seeing human data during training. The policy is realistic when assessed against human references and achieves unprecedented robustness, averaging 17.5 years of continuous driving between incidents in simulation.
Reinforcement Learning for Long-Horizon Interactive LLM Agents
Feb 04, 2025Interactive digital agents (IDAs) leverage APIs of stateful digital environments to perform tasks in response to user requests. While IDAs powered by instruction-tuned large language models (LLMs) can react to feedback from interface invocations in multi-step exchanges, they have not been trained in their respective digital environments. Prior methods accomplish less than half of tasks in sophisticated benchmarks such as AppWorld. We present a reinforcement learning (RL) approach that trains IDAs directly in their target environments. We formalize this training as a partially observable Markov decision process and derive LOOP, a data- and memory-efficient variant of proximal policy optimization. LOOP uses no value network and maintains exactly one copy of the underlying LLM in memory, making its implementation straightforward and as memory-efficient as fine-tuning a single LLM. A 32-billion-parameter agent trained with LOOP in the AppWorld environment outperforms the much larger OpenAI o1 agent by 9 percentage points (15% relative). To our knowledge, this is the first reported application of RL to IDAs that interact with a stateful, multi-domain, multi-app environment via direct API calls. Our analysis sheds light on the effectiveness of RL in this area, showing that the agent learns to consult the API documentation, avoid unwarranted assumptions, minimize confabulation, and recover from setbacks.
Cut Your Losses in Large-Vocabulary Language Models
Nov 13, 2024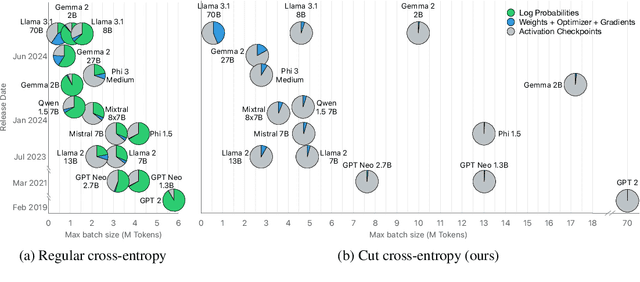
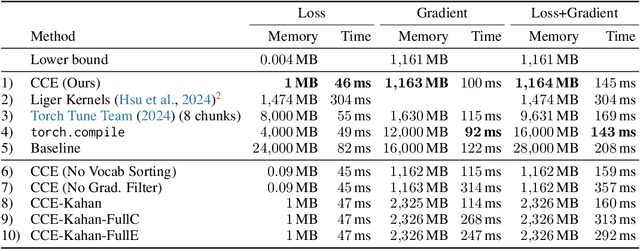
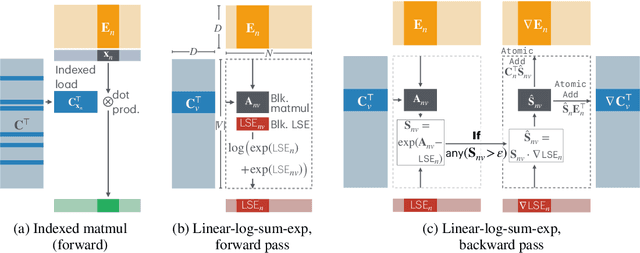
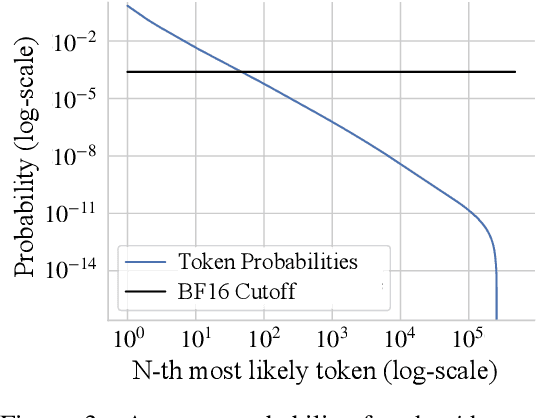
As language models grow ever larger, so do their vocabularies. This has shifted the memory footprint of LLMs during training disproportionately to one single layer: the cross-entropy in the loss computation. Cross-entropy builds up a logit matrix with entries for each pair of input tokens and vocabulary items and, for small models, consumes an order of magnitude more memory than the rest of the LLM combined. We propose Cut Cross-Entropy (CCE), a method that computes the cross-entropy loss without materializing the logits for all tokens into global memory. Rather, CCE only computes the logit for the correct token and evaluates the log-sum-exp over all logits on the fly. We implement a custom kernel that performs the matrix multiplications and the log-sum-exp reduction over the vocabulary in flash memory, making global memory consumption for the cross-entropy computation negligible. This has a dramatic effect. Taking the Gemma 2 (2B) model as an example, CCE reduces the memory footprint of the loss computation from 24 GB to 1 MB, and the total training-time memory consumption of the classifier head from 28 GB to 1 GB. To improve the throughput of CCE, we leverage the inherent sparsity of softmax and propose to skip elements of the gradient computation that have a negligible (i.e., below numerical precision) contribution to the gradient. Experiments demonstrate that the dramatic reduction in memory consumption is accomplished without sacrificing training speed or convergence.
An Empirical Evaluation of Deep Learning on Highway Driving
Apr 17, 2015
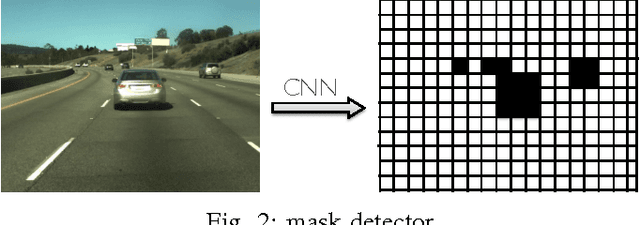
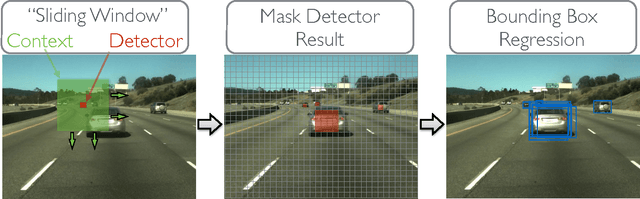
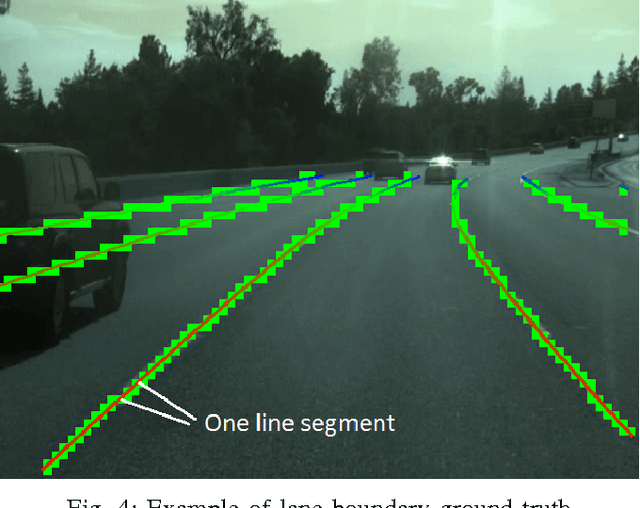
Numerous groups have applied a variety of deep learning techniques to computer vision problems in highway perception scenarios. In this paper, we presented a number of empirical evaluations of recent deep learning advances. Computer vision, combined with deep learning, has the potential to bring about a relatively inexpensive, robust solution to autonomous driving. To prepare deep learning for industry uptake and practical applications, neural networks will require large data sets that represent all possible driving environments and scenarios. We collect a large data set of highway data and apply deep learning and computer vision algorithms to problems such as car and lane detection. We show how existing convolutional neural networks (CNNs) can be used to perform lane and vehicle detection while running at frame rates required for a real-time system. Our results lend credence to the hypothesis that deep learning holds promise for autonomous driving.
Deep learning for class-generic object detection
Dec 24, 2013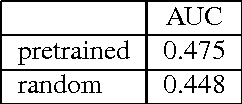
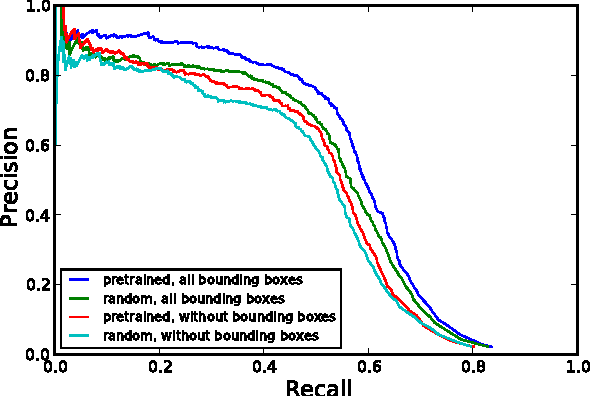

We investigate the use of deep neural networks for the novel task of class generic object detection. We show that neural networks originally designed for image recognition can be trained to detect objects within images, regardless of their class, including objects for which no bounding box labels have been provided. In addition, we show that bounding box labels yield a 1% performance increase on the ImageNet recognition challenge.