 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSharp Monocular View Synthesis in Less Than a Second
Dec 11, 2025We present SHARP, an approach to photorealistic view synthesis from a single image. Given a single photograph, SHARP regresses the parameters of a 3D Gaussian representation of the depicted scene. This is done in less than a second on a standard GPU via a single feedforward pass through a neural network. The 3D Gaussian representation produced by SHARP can then be rendered in real time, yielding high-resolution photorealistic images for nearby views. The representation is metric, with absolute scale, supporting metric camera movements. Experimental results demonstrate that SHARP delivers robust zero-shot generalization across datasets. It sets a new state of the art on multiple datasets, reducing LPIPS by 25-34% and DISTS by 21-43% versus the best prior model, while lowering the synthesis time by three orders of magnitude. Code and weights are provided at https://github.com/apple/ml-sharp
CoMotion: Concurrent Multi-person 3D Motion
Apr 16, 2025We introduce an approach for detecting and tracking detailed 3D poses of multiple people from a single monocular camera stream. Our system maintains temporally coherent predictions in crowded scenes filled with difficult poses and occlusions. Our model performs both strong per-frame detection and a learned pose update to track people from frame to frame. Rather than match detections across time, poses are updated directly from a new input image, which enables online tracking through occlusion. We train on numerous image and video datasets leveraging pseudo-labeled annotations to produce a model that matches state-of-the-art systems in 3D pose estimation accuracy while being faster and more accurate in tracking multiple people through time. Code and weights are provided at https://github.com/apple/ml-comotion
Robust Autonomy Emerges from Self-Play
Feb 05, 2025Self-play has powered breakthroughs in two-player and multi-player games. Here we show that self-play is a surprisingly effective strategy in another domain. We show that robust and naturalistic driving emerges entirely from self-play in simulation at unprecedented scale -- 1.6~billion~km of driving. This is enabled by Gigaflow, a batched simulator that can synthesize and train on 42 years of subjective driving experience per hour on a single 8-GPU node. The resulting policy achieves state-of-the-art performance on three independent autonomous driving benchmarks. The policy outperforms the prior state of the art when tested on recorded real-world scenarios, amidst human drivers, without ever seeing human data during training. The policy is realistic when assessed against human references and achieves unprecedented robustness, averaging 17.5 years of continuous driving between incidents in simulation.
Reinforcement Learning for Long-Horizon Interactive LLM Agents
Feb 04, 2025Interactive digital agents (IDAs) leverage APIs of stateful digital environments to perform tasks in response to user requests. While IDAs powered by instruction-tuned large language models (LLMs) can react to feedback from interface invocations in multi-step exchanges, they have not been trained in their respective digital environments. Prior methods accomplish less than half of tasks in sophisticated benchmarks such as AppWorld. We present a reinforcement learning (RL) approach that trains IDAs directly in their target environments. We formalize this training as a partially observable Markov decision process and derive LOOP, a data- and memory-efficient variant of proximal policy optimization. LOOP uses no value network and maintains exactly one copy of the underlying LLM in memory, making its implementation straightforward and as memory-efficient as fine-tuning a single LLM. A 32-billion-parameter agent trained with LOOP in the AppWorld environment outperforms the much larger OpenAI o1 agent by 9 percentage points (15% relative). To our knowledge, this is the first reported application of RL to IDAs that interact with a stateful, multi-domain, multi-app environment via direct API calls. Our analysis sheds light on the effectiveness of RL in this area, showing that the agent learns to consult the API documentation, avoid unwarranted assumptions, minimize confabulation, and recover from setbacks.
Conformation Generation using Transformer Flows
Nov 16, 2024

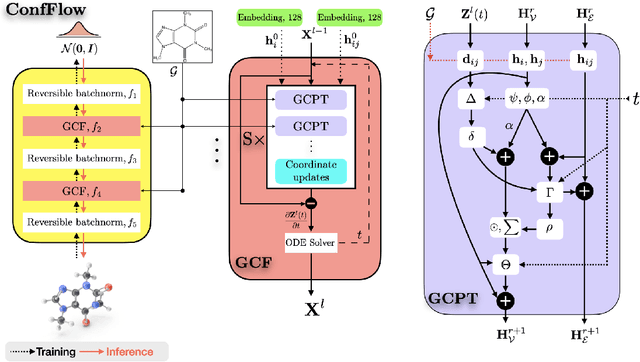

Estimating three-dimensional conformations of a molecular graph allows insight into the molecule's biological and chemical functions. Fast generation of valid conformations is thus central to molecular modeling. Recent advances in graph-based deep networks have accelerated conformation generation from hours to seconds. However, current network architectures do not scale well to large molecules. Here we present ConfFlow, a flow-based model for conformation generation based on transformer networks. In contrast with existing approaches, ConfFlow directly samples in the coordinate space without enforcing any explicit physical constraints. The generative procedure is highly interpretable and is akin to force field updates in molecular dynamics simulation. When applied to the generation of large molecule conformations, ConfFlow improve accuracy by up to $40\%$ relative to state-of-the-art learning-based methods. The source code is made available at https://github.com/IntelLabs/ConfFlow.
Cut Your Losses in Large-Vocabulary Language Models
Nov 13, 2024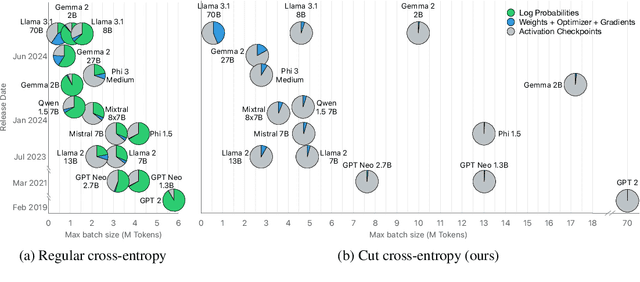
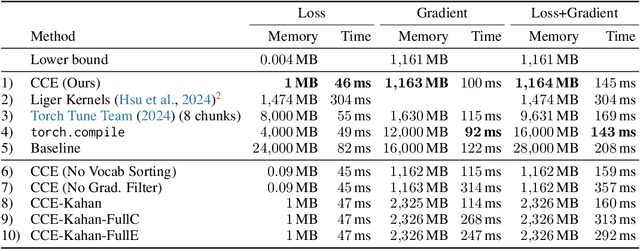
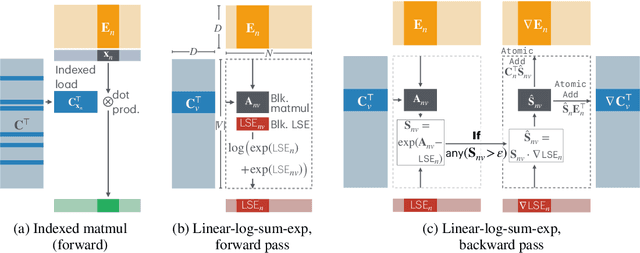
As language models grow ever larger, so do their vocabularies. This has shifted the memory footprint of LLMs during training disproportionately to one single layer: the cross-entropy in the loss computation. Cross-entropy builds up a logit matrix with entries for each pair of input tokens and vocabulary items and, for small models, consumes an order of magnitude more memory than the rest of the LLM combined. We propose Cut Cross-Entropy (CCE), a method that computes the cross-entropy loss without materializing the logits for all tokens into global memory. Rather, CCE only computes the logit for the correct token and evaluates the log-sum-exp over all logits on the fly. We implement a custom kernel that performs the matrix multiplications and the log-sum-exp reduction over the vocabulary in flash memory, making global memory consumption for the cross-entropy computation negligible. This has a dramatic effect. Taking the Gemma 2 (2B) model as an example, CCE reduces the memory footprint of the loss computation from 24 GB to 1 MB, and the total training-time memory consumption of the classifier head from 28 GB to 1 GB. To improve the throughput of CCE, we leverage the inherent sparsity of softmax and propose to skip elements of the gradient computation that have a negligible (i.e., below numerical precision) contribution to the gradient. Experiments demonstrate that the dramatic reduction in memory consumption is accomplished without sacrificing training speed or convergence.
Does Spatial Cognition Emerge in Frontier Models?
Oct 09, 2024Not yet. We present SPACE, a benchmark that systematically evaluates spatial cognition in frontier models. Our benchmark builds on decades of research in cognitive science. It evaluates large-scale mapping abilities that are brought to bear when an organism traverses physical environments, smaller-scale reasoning about object shapes and layouts, and cognitive infrastructure such as spatial attention and memory. For many tasks, we instantiate parallel presentations via text and images, allowing us to benchmark both large language models and large multimodal models. Results suggest that contemporary frontier models fall short of the spatial intelligence of animals, performing near chance level on a number of classic tests of animal cognition.
Depth Pro: Sharp Monocular Metric Depth in Less Than a Second
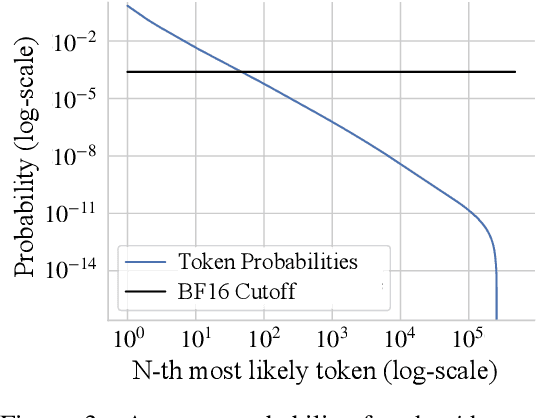
Oct 02, 2024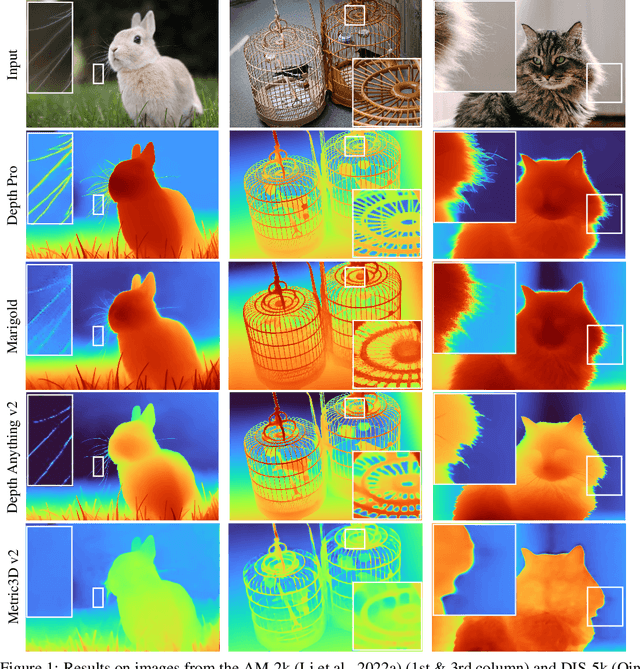
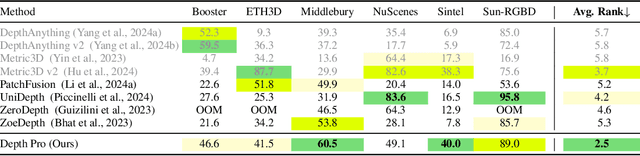
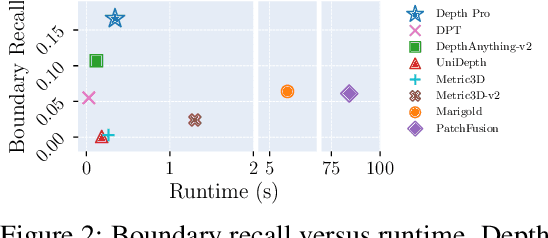
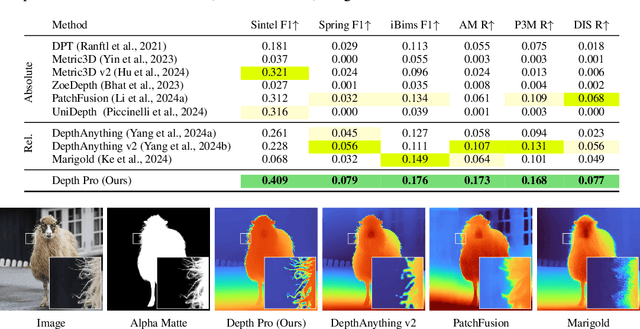
We present a foundation model for zero-shot metric monocular depth estimation. Our model, Depth Pro, synthesizes high-resolution depth maps with unparalleled sharpness and high-frequency details. The predictions are metric, with absolute scale, without relying on the availability of metadata such as camera intrinsics. And the model is fast, producing a 2.25-megapixel depth map in 0.3 seconds on a standard GPU. These characteristics are enabled by a number of technical contributions, including an efficient multi-scale vision transformer for dense prediction, a training protocol that combines real and synthetic datasets to achieve high metric accuracy alongside fine boundary tracing, dedicated evaluation metrics for boundary accuracy in estimated depth maps, and state-of-the-art focal length estimation from a single image. Extensive experiments analyze specific design choices and demonstrate that Depth Pro outperforms prior work along multiple dimensions. We release code and weights at https://github.com/apple/ml-depth-pro
OpenBot-Fleet: A System for Collective Learning with Real Robots
May 13, 2024We introduce OpenBot-Fleet, a comprehensive open-source cloud robotics system for navigation. OpenBot-Fleet uses smartphones for sensing, local compute and communication, Google Firebase for secure cloud storage and off-board compute, and a robust yet low-cost wheeled robot toact in real-world environments. The robots collect task data and upload it to the cloud where navigation policies can be learned either offline or online and can then be sent back to the robot fleet. In our experiments we distribute 72 robots to a crowd of workers who operate them in homes, and show that OpenBot-Fleet can learn robust navigation policies that generalize to unseen homes with >80% success rate. OpenBot-Fleet represents a significant step forward in cloud robotics, making it possible to deploy large continually learning robot fleets in a cost-effective and scalable manner. All materials can be found at https://www.openbot.org. A video is available at https://youtu.be/wiv2oaDgDi8
Reaching the Limit in Autonomous Racing: Optimal Control versus Reinforcement Learning
Oct 18, 2023A central question in robotics is how to design a control system for an agile mobile robot. This paper studies this question systematically, focusing on a challenging setting: autonomous drone racing. We show that a neural network controller trained with reinforcement learning (RL) outperformed optimal control (OC) methods in this setting. We then investigated which fundamental factors have contributed to the success of RL or have limited OC. Our study indicates that the fundamental advantage of RL over OC is not that it optimizes its objective better but that it optimizes a better objective. OC decomposes the problem into planning and control with an explicit intermediate representation, such as a trajectory, that serves as an interface. This decomposition limits the range of behaviors that can be expressed by the controller, leading to inferior control performance when facing unmodeled effects. In contrast, RL can directly optimize a task-level objective and can leverage domain randomization to cope with model uncertainty, allowing the discovery of more robust control responses. Our findings allowed us to push an agile drone to its maximum performance, achieving a peak acceleration greater than 12 times the gravitational acceleration and a peak velocity of 108 kilometers per hour. Our policy achieved superhuman control within minutes of training on a standard workstation. This work presents a milestone in agile robotics and sheds light on the role of RL and OC in robot control.