 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenBot-Fleet: A System for Collective Learning with Real Robots
May 13, 2024We introduce OpenBot-Fleet, a comprehensive open-source cloud robotics system for navigation. OpenBot-Fleet uses smartphones for sensing, local compute and communication, Google Firebase for secure cloud storage and off-board compute, and a robust yet low-cost wheeled robot toact in real-world environments. The robots collect task data and upload it to the cloud where navigation policies can be learned either offline or online and can then be sent back to the robot fleet. In our experiments we distribute 72 robots to a crowd of workers who operate them in homes, and show that OpenBot-Fleet can learn robust navigation policies that generalize to unseen homes with >80% success rate. OpenBot-Fleet represents a significant step forward in cloud robotics, making it possible to deploy large continually learning robot fleets in a cost-effective and scalable manner. All materials can be found at https://www.openbot.org. A video is available at https://youtu.be/wiv2oaDgDi8
Zero-Shot Transfer of Haptics-Based Object Insertion Policies
Jan 31, 2023



Humans naturally exploit haptic feedback during contact-rich tasks like loading a dishwasher or stocking a bookshelf. Current robotic systems focus on avoiding unexpected contact, often relying on strategically placed environment sensors. Recently, contact-exploiting manipulation policies have been trained in simulation and deployed on real robots. However, they require some form of real-world adaptation to bridge the sim-to-real gap, which might not be feasible in all scenarios. In this paper we train a contact-exploiting manipulation policy in simulation for the contact-rich household task of loading plates into a slotted holder, which transfers without any fine-tuning to the real robot. We investigate various factors necessary for this zero-shot transfer, like time delay modeling, memory representation, and domain randomization. Our policy transfers with minimal sim-to-real gap and significantly outperforms heuristic and learnt baselines. It also generalizes to plates of different sizes and weights. Demonstration videos and code are available at https://sites.google.com/view/compliant-object-insertion.
ARC -- Actor Residual Critic for Adversarial Imitation Learning
Jun 05, 2022
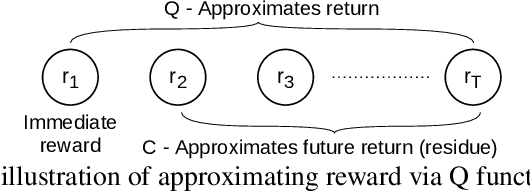
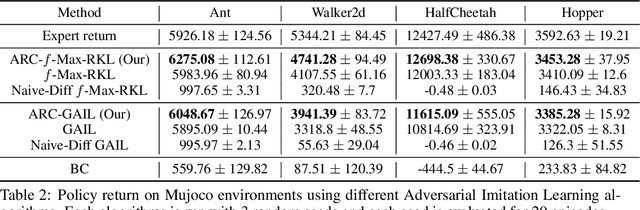
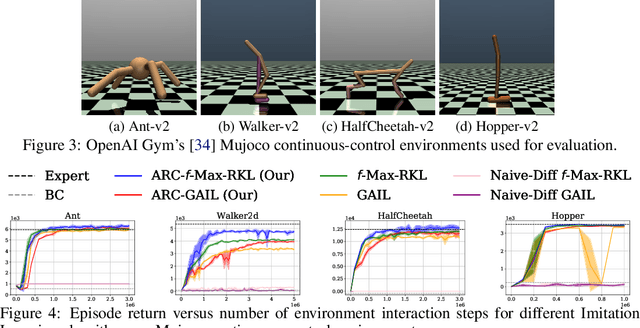
Adversarial Imitation Learning (AIL) is a class of popular state-of-the-art Imitation Learning algorithms where an artificial adversary's misclassification is used as a reward signal and is optimized by any standard Reinforcement Learning (RL) algorithm. Unlike most RL settings, the reward in AIL is differentiable but model-free RL algorithms do not make use of this property to train a policy. In contrast, we leverage the differentiability property of the AIL reward function and formulate a class of Actor Residual Critic (ARC) RL algorithms that draw a parallel to the standard Actor-Critic (AC) algorithms in RL literature and uses a residual critic, C function (instead of the standard Q function) to approximate only the discounted future return (excluding the immediate reward). ARC algorithms have similar convergence properties as the standard AC algorithms with the additional advantage that the gradient through the immediate reward is exact. For the discrete (tabular) case with finite states, actions, and known dynamics, we prove that policy iteration with $C$ function converges to an optimal policy. In the continuous case with function approximation and unknown dynamics, we experimentally show that ARC aided AIL outperforms standard AIL in simulated continuous-control and real robotic manipulation tasks. ARC algorithms are simple to implement and can be incorporated into any existing AIL implementation with an AC algorithm.
Hiding Leader's Identity in Leader-Follower Navigation through Multi-Agent Reinforcement Learning
Mar 10, 2021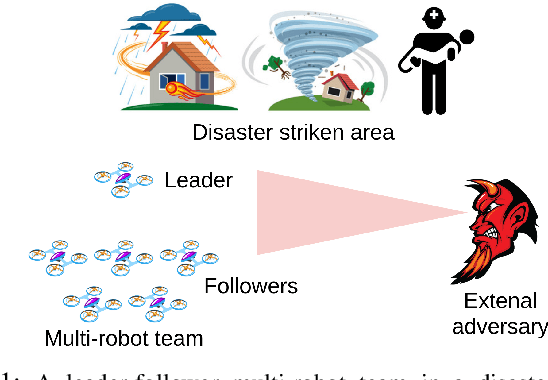
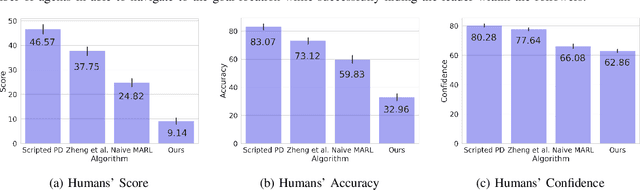
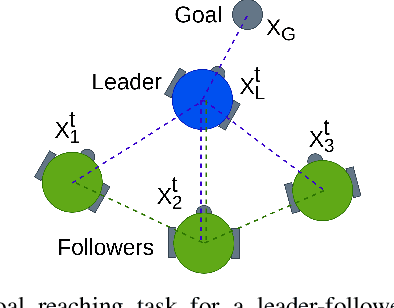
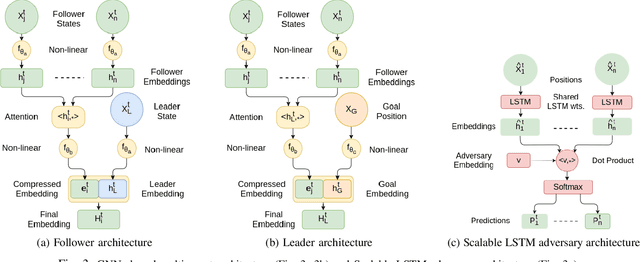
Leader-follower navigation is a popular class of multi-robot algorithms where a leader robot leads the follower robots in a team. The leader has specialized capabilities or mission critical information (e.g. goal location) that the followers lack which makes the leader crucial for the mission's success. However, this also makes the leader a vulnerability - an external adversary who wishes to sabotage the robot team's mission can simply harm the leader and the whole robot team's mission would be compromised. Since robot motion generated by traditional leader-follower navigation algorithms can reveal the identity of the leader, we propose a defense mechanism of hiding the leader's identity by ensuring the leader moves in a way that behaviorally camouflages it with the followers, making it difficult for an adversary to identify the leader. To achieve this, we combine Multi-Agent Reinforcement Learning, Graph Neural Networks and adversarial training. Our approach enables the multi-robot team to optimize the primary task performance with leader motion similar to follower motion, behaviorally camouflaging it with the followers. Our algorithm outperforms existing work that tries to hide the leader's identity in a multi-robot team by tuning traditional leader-follower control parameters with Classical Genetic Algorithms. We also evaluated human performance in inferring the leader's identity and found that humans had lower accuracy when the robot team used our proposed navigation algorithm.
Natural Emergence of Heterogeneous Strategies in Artificially Intelligent Competitive Teams
Jul 06, 2020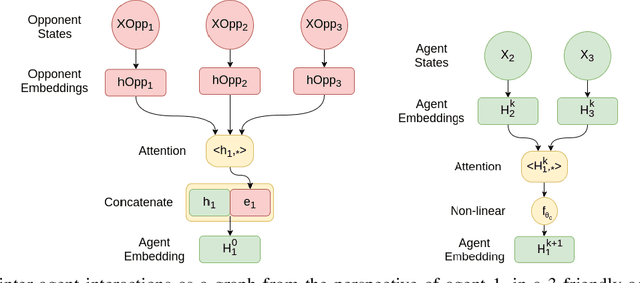
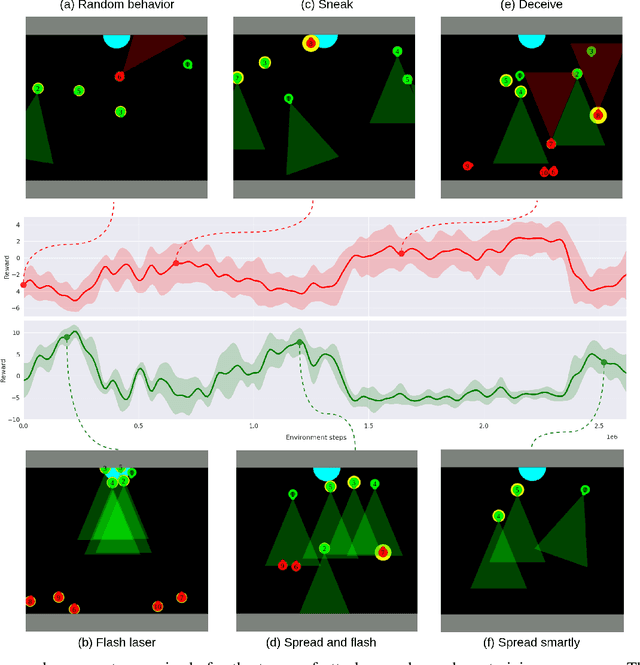

Multi agent strategies in mixed cooperative-competitive environments can be hard to craft by hand because each agent needs to coordinate with its teammates while competing with its opponents. Learning based algorithms are appealing but many scenarios require heterogeneous agent behavior for the team's success and this increases the complexity of the learning algorithm. In this work, we develop a competitive multi agent environment called FortAttack in which two teams compete against each other. We corroborate that modeling agents with Graph Neural Networks and training them with Reinforcement Learning leads to the evolution of increasingly complex strategies for each team. We observe a natural emergence of heterogeneous behavior amongst homogeneous agents when such behavior can lead to the team's success. Such heterogeneous behavior from homogeneous agents is appealing because any agent can replace the role of another agent at test time. Finally, we propose ensemble training, in which we utilize the evolved opponent strategies to train a single policy for friendly agents.