 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImagine2Servo: Intelligent Visual Servoing with Diffusion-Driven Goal Generation for Robotic Tasks
Oct 16, 2024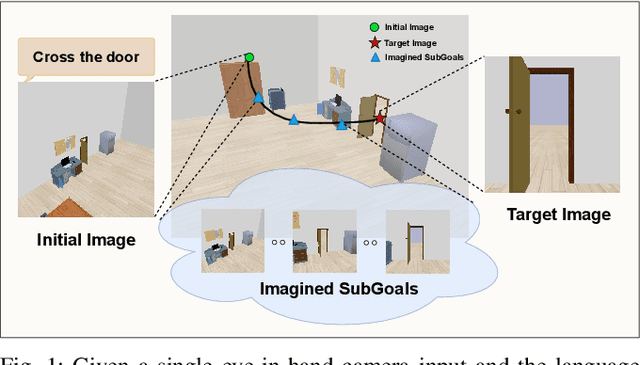
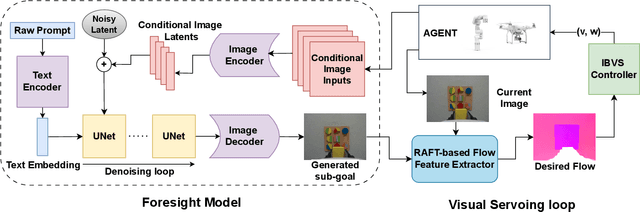
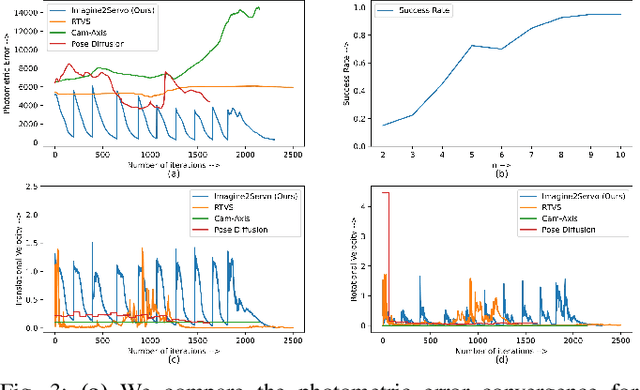

Visual servoing, the method of controlling robot motion through feedback from visual sensors, has seen significant advancements with the integration of optical flow-based methods. However, its application remains limited by inherent challenges, such as the necessity for a target image at test time, the requirement of substantial overlap between initial and target images, and the reliance on feedback from a single camera. This paper introduces Imagine2Servo, an innovative approach leveraging diffusion-based image editing techniques to enhance visual servoing algorithms by generating intermediate goal images. This methodology allows for the extension of visual servoing applications beyond traditional constraints, enabling tasks like long-range navigation and manipulation without predefined goal images. We propose a pipeline that synthesizes subgoal images grounded in the task at hand, facilitating servoing in scenarios with minimal initial and target image overlap and integrating multi-camera feedback for comprehensive task execution. Our contributions demonstrate a novel application of image generation to robotic control, significantly broadening the capabilities of visual servoing systems. Real-world experiments validate the effectiveness and versatility of the Imagine2Servo framework in accomplishing a variety of tasks, marking a notable advancement in the field of visual servoing.
OpenBot-Fleet: A System for Collective Learning with Real Robots
May 13, 2024We introduce OpenBot-Fleet, a comprehensive open-source cloud robotics system for navigation. OpenBot-Fleet uses smartphones for sensing, local compute and communication, Google Firebase for secure cloud storage and off-board compute, and a robust yet low-cost wheeled robot toact in real-world environments. The robots collect task data and upload it to the cloud where navigation policies can be learned either offline or online and can then be sent back to the robot fleet. In our experiments we distribute 72 robots to a crowd of workers who operate them in homes, and show that OpenBot-Fleet can learn robust navigation policies that generalize to unseen homes with >80% success rate. OpenBot-Fleet represents a significant step forward in cloud robotics, making it possible to deploy large continually learning robot fleets in a cost-effective and scalable manner. All materials can be found at https://www.openbot.org. A video is available at https://youtu.be/wiv2oaDgDi8
The Un-Kidnappable Robot: Acoustic Localization of Sneaking People
Oct 05, 2023



How easy is it to sneak up on a robot? We examine whether we can detect people using only the incidental sounds they produce as they move, even when they try to be quiet. We collect a robotic dataset of high-quality 4-channel audio paired with 360 degree RGB data of people moving in different indoor settings. We train models that predict if there is a moving person nearby and their location using only audio. We implement our method on a robot, allowing it to track a single person moving quietly with only passive audio sensing. For demonstration videos, see our project page: https://sites.google.com/view/unkidnappable-robot
Zero-Shot Transfer of Haptics-Based Object Insertion Policies
Jan 31, 2023



Humans naturally exploit haptic feedback during contact-rich tasks like loading a dishwasher or stocking a bookshelf. Current robotic systems focus on avoiding unexpected contact, often relying on strategically placed environment sensors. Recently, contact-exploiting manipulation policies have been trained in simulation and deployed on real robots. However, they require some form of real-world adaptation to bridge the sim-to-real gap, which might not be feasible in all scenarios. In this paper we train a contact-exploiting manipulation policy in simulation for the contact-rich household task of loading plates into a slotted holder, which transfers without any fine-tuning to the real robot. We investigate various factors necessary for this zero-shot transfer, like time delay modeling, memory representation, and domain randomization. Our policy transfers with minimal sim-to-real gap and significantly outperforms heuristic and learnt baselines. It also generalizes to plates of different sizes and weights. Demonstration videos and code are available at https://sites.google.com/view/compliant-object-insertion.
Visual Pressure Estimation and Control for Soft Robotic Grippers
Apr 14, 2022



Soft robotic grippers facilitate contact-rich manipulation, including robust grasping of varied objects. Yet the beneficial compliance of a soft gripper also results in significant deformation that can make precision manipulation challenging. We present visual pressure estimation & control (VPEC), a method that uses a single RGB image of an unmodified soft gripper from an external camera to directly infer pressure applied to the world by the gripper. We present inference results for a pneumatic gripper and a tendon-actuated gripper making contact with a flat surface. We also show that VPEC enables precision manipulation via closed-loop control of inferred pressure. We present results for a mobile manipulator (Stretch RE1 from Hello Robot) using visual servoing to do the following: achieve target pressures when making contact; follow a spatial pressure trajectory; and grasp small objects, including a microSD card, a washer, a penny, and a pill. Overall, our results show that VPEC enables grippers with high compliance to perform precision manipulation.
PressureVision: Estimating Hand Pressure from a Single RGB Image
Mar 19, 2022

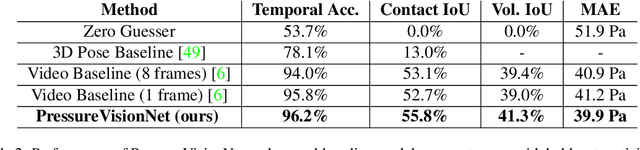

People often interact with their surroundings by applying pressure with their hands. Machine perception of hand pressure has been limited by the challenges of placing sensors between the hand and the contact surface. We explore the possibility of using a conventional RGB camera to infer hand pressure. The central insight is that the application of pressure by a hand results in informative appearance changes. Hands share biomechanical properties that result in similar observable phenomena, such as soft-tissue deformation, blood distribution, hand pose, and cast shadows. We collected videos of 36 participants with diverse skin tone applying pressure to an instrumented planar surface. We then trained a deep model (PressureVisionNet) to infer a pressure image from a single RGB image. Our model infers pressure for participants outside of the training data and outperforms baselines. We also show that the output of our model depends on the appearance of the hand and cast shadows near contact regions. Overall, our results suggest the appearance of a previously unobserved human hand can be used to accurately infer applied pressure.
ContactOpt: Optimizing Contact to Improve Grasps
Apr 15, 2021
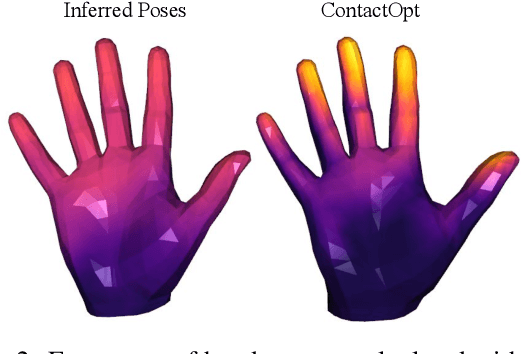
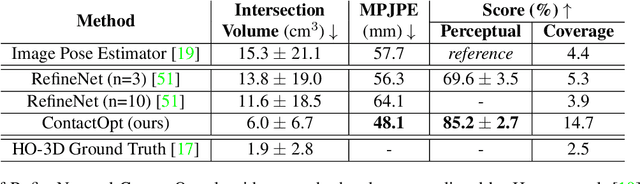

Physical contact between hands and objects plays a critical role in human grasps. We show that optimizing the pose of a hand to achieve expected contact with an object can improve hand poses inferred via image-based methods. Given a hand mesh and an object mesh, a deep model trained on ground truth contact data infers desirable contact across the surfaces of the meshes. Then, ContactOpt efficiently optimizes the pose of the hand to achieve desirable contact using a differentiable contact model. Notably, our contact model encourages mesh interpenetration to approximate deformable soft tissue in the hand. In our evaluations, our methods result in grasps that better match ground truth contact, have lower kinematic error, and are significantly preferred by human participants. Code and models are available online.
ContactPose: A Dataset of Grasps with Object Contact and Hand Pose
Jul 19, 2020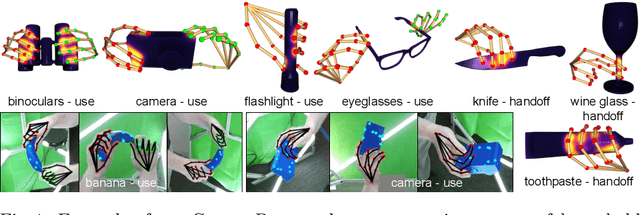
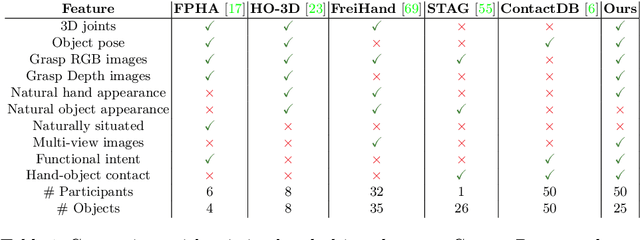
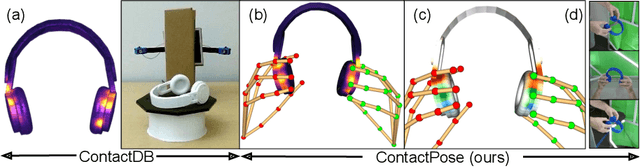
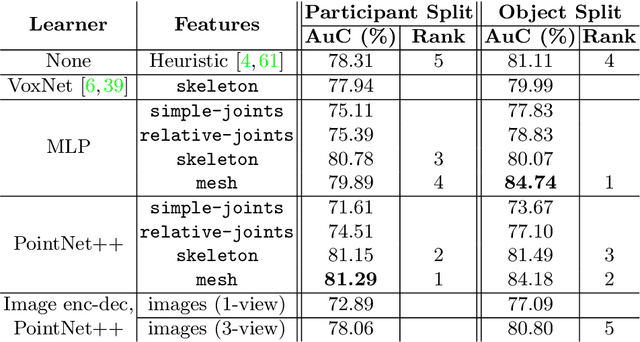
Grasping is natural for humans. However, it involves complex hand configurations and soft tissue deformation that can result in complicated regions of contact between the hand and the object. Understanding and modeling this contact can potentially improve hand models, AR/VR experiences, and robotic grasping. Yet, we currently lack datasets of hand-object contact paired with other data modalities, which is crucial for developing and evaluating contact modeling techniques. We introduce ContactPose, the first dataset of hand-object contact paired with hand pose, object pose, and RGB-D images. ContactPose has 2306 unique grasps of 25 household objects grasped with 2 functional intents by 50 participants, and more than 2.9 M RGB-D grasp images. Analysis of ContactPose data reveals interesting relationships between hand pose and contact. We use this data to rigorously evaluate various data representations, heuristics from the literature, and learning methods for contact modeling. Data, code, and trained models are available at https://contactpose.cc.gatech.edu.
Towards Markerless Grasp Capture
Jul 17, 2019

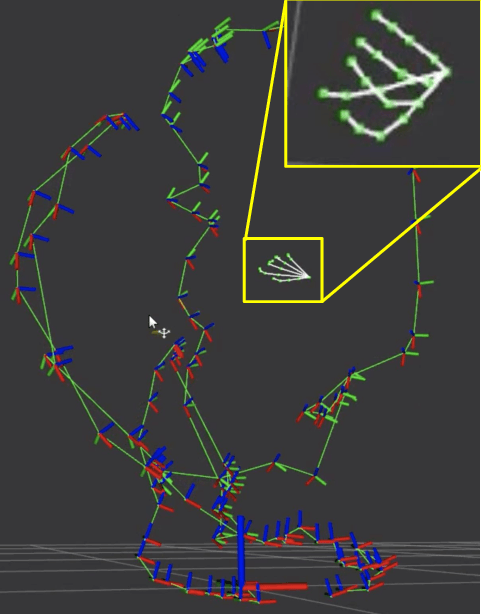

Humans excel at grasping objects and manipulating them. Capturing human grasps is important for understanding grasping behavior and reconstructing it realistically in Virtual Reality (VR). However, grasp capture - capturing the pose of a hand grasping an object, and orienting it w.r.t. the object - is difficult because of the complexity and diversity of the human hand, and occlusion. Reflective markers and magnetic trackers traditionally used to mitigate this difficulty introduce undesirable artifacts in images and can interfere with natural grasping behavior. We present preliminary work on a completely marker-less algorithm for grasp capture from a video depicting a grasp. We show how recent advances in 2D hand pose estimation can be used with well-established optimization techniques. Uniquely, our algorithm can also capture hand-object contact in detail and integrate it in the grasp capture process. This is work in progress, find more details at https://contactdb. cc.gatech.edu/grasp_capture.html.
ContactDB: Analyzing and Predicting Grasp Contact via Thermal Imaging
Apr 15, 2019
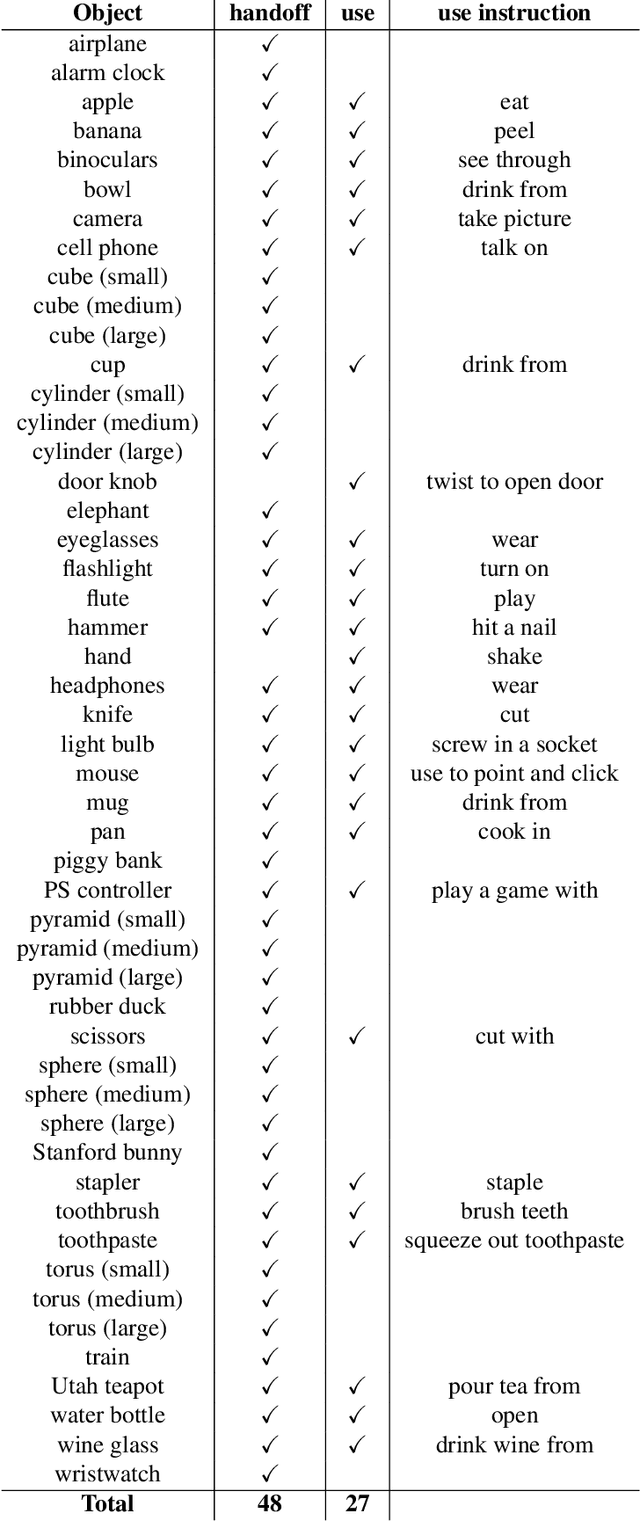

Grasping and manipulating objects is an important human skill. Since hand-object contact is fundamental to grasping, capturing it can lead to important insights. However, observing contact through external sensors is challenging because of occlusion and the complexity of the human hand. We present ContactDB, a novel dataset of contact maps for household objects that captures the rich hand-object contact that occurs during grasping, enabled by use of a thermal camera. Participants in our study grasped 3D printed objects with a post-grasp functional intent. ContactDB includes 3750 3D meshes of 50 household objects textured with contact maps and 375K frames of synchronized RGB-D+thermal images. To the best of our knowledge, this is the first large-scale dataset that records detailed contact maps for human grasps. Analysis of this data shows the influence of functional intent and object size on grasping, the tendency to touch/avoid 'active areas', and the high frequency of palm and proximal finger contact. Finally, we train state-of-the-art image translation and 3D convolution algorithms to predict diverse contact patterns from object shape. Data, code and models are available at https://contactdb.cc.gatech.edu.