 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSaFeR: Safety-Critical Scenario Generation for Autonomous Driving Test via Feasibility-Constrained Token Resampling
Mar 04, 2026Safety-critical scenario generation is crucial for evaluating autonomous driving systems. However, existing approaches often struggle to balance three conflicting objectives: adversarial criticality, physical feasibility, and behavioral realism. To bridge this gap, we propose SaFeR: safety-critical scenario generation for autonomous driving test via feasibility-constrained token resampling. We first formulate traffic generation as a discrete next token prediction problem, employing a Transformer-based model as a realism prior to capture naturalistic driving distributions. To capture complex interactions while effectively mitigating attention noise, we propose a novel differential attention mechanism within the realism prior. Building on this prior, SaFeR implements a novel resampling strategy that induces adversarial behaviors within a high-probability trust region to maintain naturalism, while enforcing a feasibility constraint derived from the Largest Feasible Region (LFR). By approximating the LFR via offline reinforcement learning, SaFeR effectively prevents the generation of theoretically inevitable collisions. Closed-loop experiments on the Waymo Open Motion Dataset and nuPlan demonstrate that SaFeR significantly outperforms state-of-the-art baselines, achieving a higher solution rate and superior kinematic realism while maintaining strong adversarial effectiveness.
LLaMo: Scaling Pretrained Language Models for Unified Motion Understanding and Generation with Continuous Autoregressive Tokens
Feb 12, 2026Recent progress in large models has led to significant advances in unified multimodal generation and understanding. However, the development of models that unify motion-language generation and understanding remains largely underexplored. Existing approaches often fine-tune large language models (LLMs) on paired motion-text data, which can result in catastrophic forgetting of linguistic capabilities due to the limited scale of available text-motion pairs. Furthermore, prior methods typically convert motion into discrete representations via quantization to integrate with language models, introducing substantial jitter artifacts from discrete tokenization. To address these challenges, we propose LLaMo, a unified framework that extends pretrained LLMs through a modality-specific Mixture-of-Transformers (MoT) architecture. This design inherently preserves the language understanding of the base model while enabling scalable multimodal adaptation. We encode human motion into a causal continuous latent space and maintain the next-token prediction paradigm in the decoder-only backbone through a lightweight flow-matching head, allowing for streaming motion generation in real-time (>30 FPS). Leveraging the comprehensive language understanding of pretrained LLMs and large-scale motion-text pretraining, our experiments demonstrate that LLaMo achieves high-fidelity text-to-motion generation and motion-to-text captioning in general settings, especially zero-shot motion generation, marking a significant step towards a general unified motion-language large model.
HuMoCon: Concept Discovery for Human Motion Understanding
May 27, 2025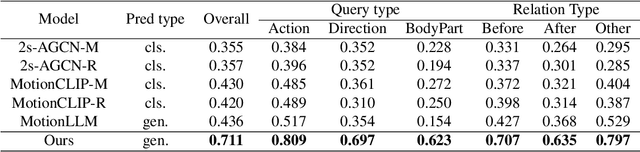
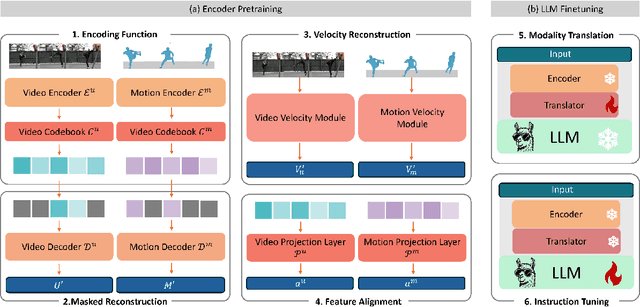
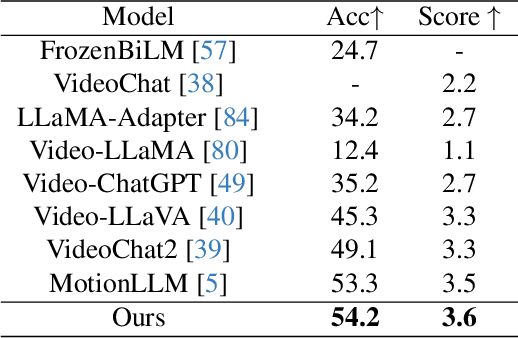
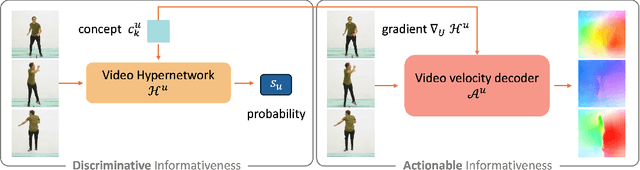
We present HuMoCon, a novel motion-video understanding framework designed for advanced human behavior analysis. The core of our method is a human motion concept discovery framework that efficiently trains multi-modal encoders to extract semantically meaningful and generalizable features. HuMoCon addresses key challenges in motion concept discovery for understanding and reasoning, including the lack of explicit multi-modality feature alignment and the loss of high-frequency information in masked autoencoding frameworks. Our approach integrates a feature alignment strategy that leverages video for contextual understanding and motion for fine-grained interaction modeling, further with a velocity reconstruction mechanism to enhance high-frequency feature expression and mitigate temporal over-smoothing. Comprehensive experiments on standard benchmarks demonstrate that HuMoCon enables effective motion concept discovery and significantly outperforms state-of-the-art methods in training large models for human motion understanding. We will open-source the associated code with our paper.
* 18 pages, 10 figures
CigTime: Corrective Instruction Generation Through Inverse Motion Editing
Dec 06, 2024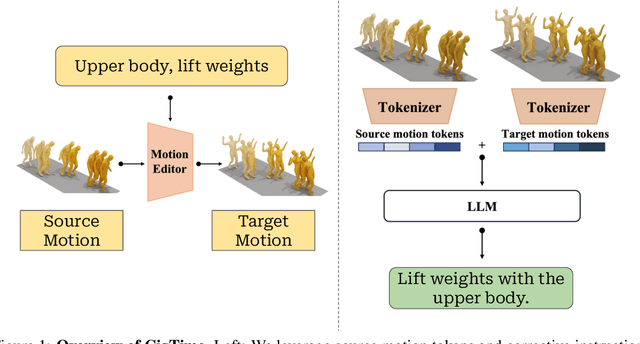
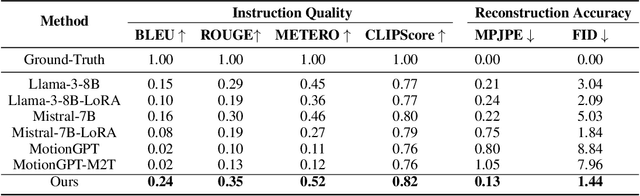

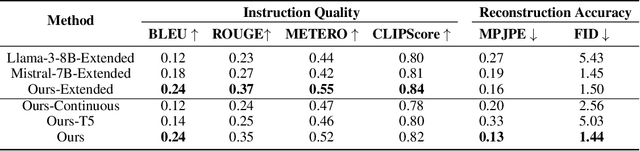
Recent advancements in models linking natural language with human motions have shown significant promise in motion generation and editing based on instructional text. Motivated by applications in sports coaching and motor skill learning, we investigate the inverse problem: generating corrective instructional text, leveraging motion editing and generation models. We introduce a novel approach that, given a user's current motion (source) and the desired motion (target), generates text instructions to guide the user towards achieving the target motion. We leverage large language models to generate corrective texts and utilize existing motion generation and editing frameworks to compile datasets of triplets (source motion, target motion, and corrective text). Using this data, we propose a new motion-language model for generating corrective instructions. We present both qualitative and quantitative results across a diverse range of applications that largely improve upon baselines. Our approach demonstrates its effectiveness in instructional scenarios, offering text-based guidance to correct and enhance user performance.
BID: Boundary-Interior Decoding for Unsupervised Temporal Action Localization Pre-Trainin
Mar 12, 2024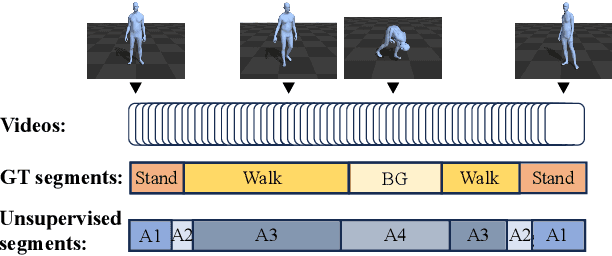
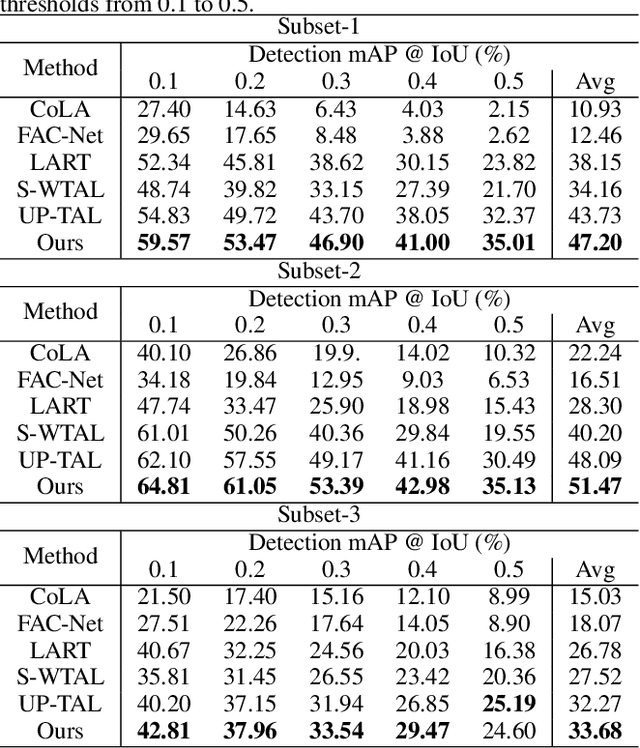
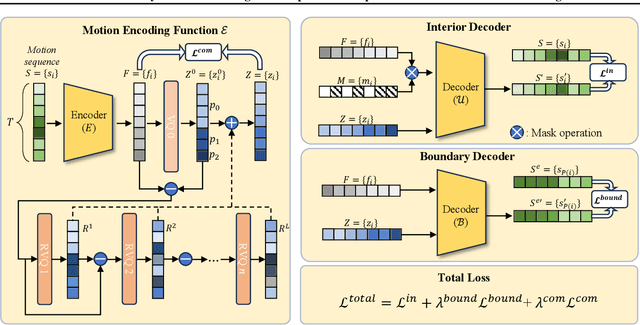
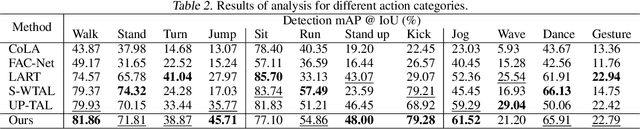
Skeleton-based motion representations are robust for action localization and understanding for their invariance to perspective, lighting, and occlusion, compared with images. Yet, they are often ambiguous and incomplete when taken out of context, even for human annotators. As infants discern gestures before associating them with words, actions can be conceptualized before being grounded with labels. Therefore, we propose the first unsupervised pre-training framework, Boundary-Interior Decoding (BID), that partitions a skeleton-based motion sequence into discovered semantically meaningful pre-action segments. By fine-tuning our pre-training network with a small number of annotated data, we show results out-performing SOTA methods by a large margin.
EMDB: The Electromagnetic Database of Global 3D Human Pose and Shape in the Wild
Aug 31, 2023


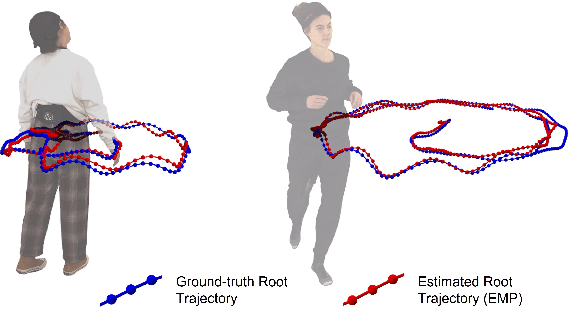
We present EMDB, the Electromagnetic Database of Global 3D Human Pose and Shape in the Wild. EMDB is a novel dataset that contains high-quality 3D SMPL pose and shape parameters with global body and camera trajectories for in-the-wild videos. We use body-worn, wireless electromagnetic (EM) sensors and a hand-held iPhone to record a total of 58 minutes of motion data, distributed over 81 indoor and outdoor sequences and 10 participants. Together with accurate body poses and shapes, we also provide global camera poses and body root trajectories. To construct EMDB, we propose a multi-stage optimization procedure, which first fits SMPL to the 6-DoF EM measurements and then refines the poses via image observations. To achieve high-quality results, we leverage a neural implicit avatar model to reconstruct detailed human surface geometry and appearance, which allows for improved alignment and smoothness via a dense pixel-level objective. Our evaluations, conducted with a multi-view volumetric capture system, indicate that EMDB has an expected accuracy of 2.3 cm positional and 10.6 degrees angular error, surpassing the accuracy of previous in-the-wild datasets. We evaluate existing state-of-the-art monocular RGB methods for camera-relative and global pose estimation on EMDB. EMDB is publicly available under https://ait.ethz.ch/emdb
Visual Estimation of Fingertip Pressure on Diverse Surfaces using Easily Captured Data
Jan 05, 2023


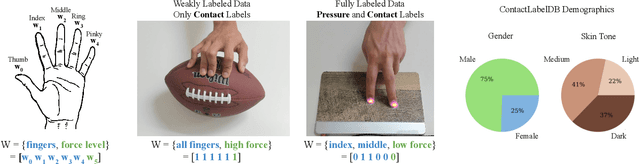
Prior research has shown that deep models can estimate the pressure applied by a hand to a surface based on a single RGB image. Training these models requires high-resolution pressure measurements that are difficult to obtain with physical sensors. Additionally, even experts cannot reliably annotate pressure from images. Thus, data collection is a critical barrier to generalization and improved performance. We present a novel approach that enables training data to be efficiently captured from unmodified surfaces with only an RGB camera and a cooperative participant. Our key insight is that people can be prompted to perform actions that correspond with categorical labels (contact labels) describing contact pressure, such as using a specific fingertip to make low-force contact. We present ContactLabelNet, which visually estimates pressure applied by fingertips. With the use of contact labels, ContactLabelNet achieves improved performance, generalizes to novel surfaces, and outperforms models from prior work.
MotionDeltaCNN: Sparse CNN Inference of Frame Differences in Moving Camera Videos
Oct 18, 2022
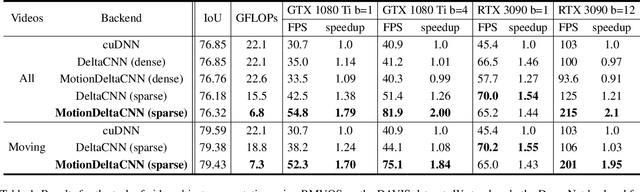

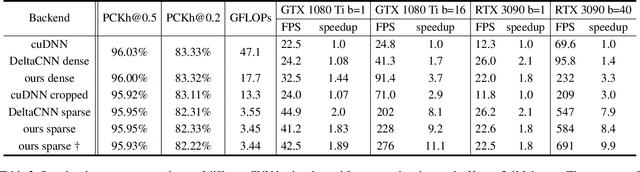
Convolutional neural network inference on video input is computationally expensive and has high memory bandwidth requirements. Recently, researchers managed to reduce the cost of processing upcoming frames by only processing pixels that changed significantly. Using sparse convolutions, the sparsity of frame differences can be translated to speedups on current inference devices. However, previous work was relying on static cameras. Moving cameras add new challenges in how to fuse newly unveiled image regions with already processed regions efficiently to minimize the update rate - without increasing memory overhead and without knowing the camera extrinsics of future frames. In this work, we propose MotionDeltaCNN, a CNN framework that supports moving cameras and variable resolution input. We propose a spherical buffer which enables seamless fusion of newly unveiled regions and previously processed regions - without increasing the memory footprint. Our evaluations show that we outperform previous work significantly by explicitly adding support for moving camera input.
Visual Pressure Estimation and Control for Soft Robotic Grippers
Apr 14, 2022



Soft robotic grippers facilitate contact-rich manipulation, including robust grasping of varied objects. Yet the beneficial compliance of a soft gripper also results in significant deformation that can make precision manipulation challenging. We present visual pressure estimation & control (VPEC), a method that uses a single RGB image of an unmodified soft gripper from an external camera to directly infer pressure applied to the world by the gripper. We present inference results for a pneumatic gripper and a tendon-actuated gripper making contact with a flat surface. We also show that VPEC enables precision manipulation via closed-loop control of inferred pressure. We present results for a mobile manipulator (Stretch RE1 from Hello Robot) using visual servoing to do the following: achieve target pressures when making contact; follow a spatial pressure trajectory; and grasp small objects, including a microSD card, a washer, a penny, and a pill. Overall, our results show that VPEC enables grippers with high compliance to perform precision manipulation.
PressureVision: Estimating Hand Pressure from a Single RGB Image
Mar 19, 2022

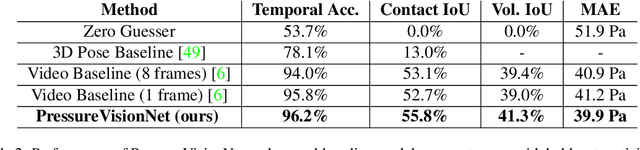

People often interact with their surroundings by applying pressure with their hands. Machine perception of hand pressure has been limited by the challenges of placing sensors between the hand and the contact surface. We explore the possibility of using a conventional RGB camera to infer hand pressure. The central insight is that the application of pressure by a hand results in informative appearance changes. Hands share biomechanical properties that result in similar observable phenomena, such as soft-tissue deformation, blood distribution, hand pose, and cast shadows. We collected videos of 36 participants with diverse skin tone applying pressure to an instrumented planar surface. We then trained a deep model (PressureVisionNet) to infer a pressure image from a single RGB image. Our model infers pressure for participants outside of the training data and outperforms baselines. We also show that the output of our model depends on the appearance of the hand and cast shadows near contact regions. Overall, our results suggest the appearance of a previously unobserved human hand can be used to accurately infer applied pressure.