 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaze-Regularized VLMs for Ego-Centric Behavior Understanding
Mar 24, 2026Eye gaze, encompassing fixations and saccades, provides critical insights into human intentions and future actions. This study introduces a gaze-regularized framework that enhances Vision Language Models (VLMs) for egocentric behavior understanding. Unlike existing methods that rely solely on visual data and overlook gaze information, our approach directly incorporates gaze information into the VLM architecture during training. By generating gaze-based queries, the model dynamically focuses on gaze-highlighted regions, while a gaze-regularization mechanism ensures the alignment of model attention with human attention patterns. To better understand how gaze can be effectively integrated into VLMs, we conducted extensive experiments exploring various strategies for incorporating gaze data. These innovations enable the prediction of future events with detailed action descriptions. Experimental results demonstrate a nearly 13 % improvement in semantic scores compared to baseline models not leveraging gaze data, highlighting the effectiveness of our approach. This work establishes a foundation for leveraging the human gaze in VLMs, significantly boosting their predictive capabilities in applications requiring accurate and robust future event prediction.
Gaze-Regularized Vision-Language-Action Models for Robotic Manipulation
Mar 24, 2026Despite advances in Vision-Language-Action (VLA) models, robotic manipulation struggles with fine-grained tasks because current models lack mechanisms for active visual attention allocation. Human gaze naturally encodes intent, planning, and execution patterns -- offering a powerful supervisory signal for guiding robot perception. We introduce a gaze-regularized training framework that aligns VLA models' internal attention with human visual patterns without architectural modifications or inference-time overhead. Our method transforms temporally aggregated gaze heatmaps into patch-level distributions and regularizes the transformer's attention through KL divergence, creating an inductive bias toward task-relevant features while preserving deployment efficiency. When integrated into existing VLA architectures, our approach yields 4-12% improvements across manipulation benchmarks. The gaze-regularized models reach equivalent performance with fewer training steps and maintain robustness under lighting variations and sensor noise. Beyond performance metrics, the learned attention patterns produce interpretable visualizations that mirror human strategies, enhancing trust in robotic systems. Moreover, our framework requires no eye-tracking equipment and applies directly to existing datasets. These results demonstrate that human perceptual priors can significantly accelerate robot learning while improving both task performance and system interpretability.
Agri-R1: Empowering Generalizable Agricultural Reasoning in Vision-Language Models with Reinforcement Learning
Jan 08, 2026Agricultural disease diagnosis challenges VLMs, as conventional fine-tuning requires extensive labels, lacks interpretability, and generalizes poorly. While reasoning improves model robustness, existing methods rely on costly expert annotations and rarely address the open-ended, diverse nature of agricultural queries. To address these limitations, we propose \textbf{Agri-R1}, a reasoning-enhanced large model for agriculture. Our framework automates high-quality reasoning data generation via vision-language synthesis and LLM-based filtering, using only 19\% of available samples. Training employs Group Relative Policy Optimization (GRPO) with a novel proposed reward function that integrates domain-specific lexicons and fuzzy matching to assess both correctness and linguistic flexibility in open-ended responses. Evaluated on CDDMBench, our resulting 3B-parameter model achieves performance competitive with 7B- to 13B-parameter baselines, showing a +23.2\% relative gain in disease recognition accuracy, +33.3\% in agricultural knowledge QA, and a +26.10-point improvement in cross-domain generalization over standard fine-tuning. Ablation studies confirm that the synergy between structured reasoning data and GRPO-driven exploration underpins these gains, with benefits scaling as question complexity increases.
Learning Human-Humanoid Coordination for Collaborative Object Carrying
Oct 16, 2025Human-humanoid collaboration shows significant promise for applications in healthcare, domestic assistance, and manufacturing. While compliant robot-human collaboration has been extensively developed for robotic arms, enabling compliant human-humanoid collaboration remains largely unexplored due to humanoids' complex whole-body dynamics. In this paper, we propose a proprioception-only reinforcement learning approach, COLA, that combines leader and follower behaviors within a single policy. The model is trained in a closed-loop environment with dynamic object interactions to predict object motion patterns and human intentions implicitly, enabling compliant collaboration to maintain load balance through coordinated trajectory planning. We evaluate our approach through comprehensive simulator and real-world experiments on collaborative carrying tasks, demonstrating the effectiveness, generalization, and robustness of our model across various terrains and objects. Simulation experiments demonstrate that our model reduces human effort by 24.7%. compared to baseline approaches while maintaining object stability. Real-world experiments validate robust collaborative carrying across different object types (boxes, desks, stretchers, etc.) and movement patterns (straight-line, turning, slope climbing). Human user studies with 23 participants confirm an average improvement of 27.4% compared to baseline models. Our method enables compliant human-humanoid collaborative carrying without requiring external sensors or complex interaction models, offering a practical solution for real-world deployment.
HyperTASR: Hypernetwork-Driven Task-Aware Scene Representations for Robust Manipulation
Aug 26, 2025Effective policy learning for robotic manipulation requires scene representations that selectively capture task-relevant environmental features. Current approaches typically employ task-agnostic representation extraction, failing to emulate the dynamic perceptual adaptation observed in human cognition. We present HyperTASR, a hypernetwork-driven framework that modulates scene representations based on both task objectives and the execution phase. Our architecture dynamically generates representation transformation parameters conditioned on task specifications and progression state, enabling representations to evolve contextually throughout task execution. This approach maintains architectural compatibility with existing policy learning frameworks while fundamentally reconfiguring how visual features are processed. Unlike methods that simply concatenate or fuse task embeddings with task-agnostic representations, HyperTASR establishes computational separation between task-contextual and state-dependent processing paths, enhancing learning efficiency and representational quality. Comprehensive evaluations in both simulation and real-world environments demonstrate substantial performance improvements across different representation paradigms. Through ablation studies and attention visualization, we confirm that our approach selectively prioritizes task-relevant scene information, closely mirroring human adaptive perception during manipulation tasks. The project website is at \href{https://lisunphil.github.io/HyperTASR_projectpage/}{lisunphil.github.io/HyperTASR\_projectpage}.
HuMoCon: Concept Discovery for Human Motion Understanding
May 27, 2025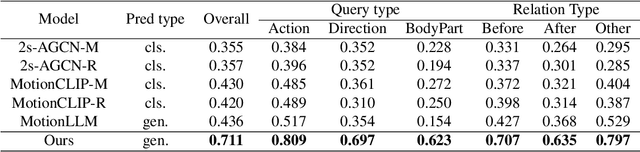
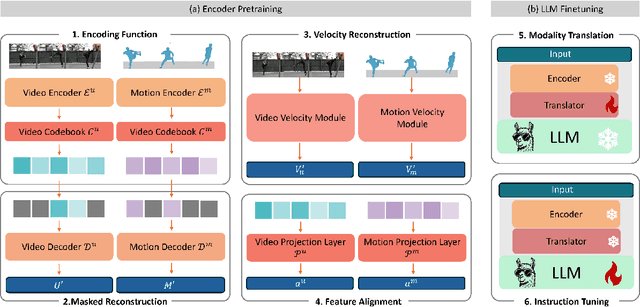
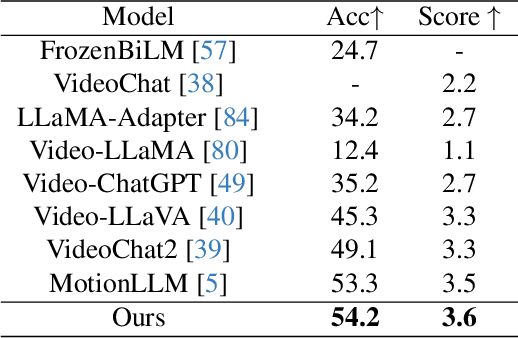
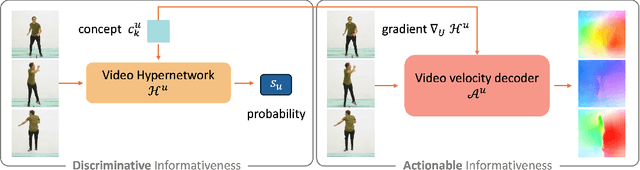
We present HuMoCon, a novel motion-video understanding framework designed for advanced human behavior analysis. The core of our method is a human motion concept discovery framework that efficiently trains multi-modal encoders to extract semantically meaningful and generalizable features. HuMoCon addresses key challenges in motion concept discovery for understanding and reasoning, including the lack of explicit multi-modality feature alignment and the loss of high-frequency information in masked autoencoding frameworks. Our approach integrates a feature alignment strategy that leverages video for contextual understanding and motion for fine-grained interaction modeling, further with a velocity reconstruction mechanism to enhance high-frequency feature expression and mitigate temporal over-smoothing. Comprehensive experiments on standard benchmarks demonstrate that HuMoCon enables effective motion concept discovery and significantly outperforms state-of-the-art methods in training large models for human motion understanding. We will open-source the associated code with our paper.
* 18 pages, 10 figures
SLAM3R: Real-Time Dense Scene Reconstruction from Monocular RGB Videos
Dec 12, 2024In this paper, we introduce \textbf{SLAM3R}, a novel and effective monocular RGB SLAM system for real-time and high-quality dense 3D reconstruction. SLAM3R provides an end-to-end solution by seamlessly integrating local 3D reconstruction and global coordinate registration through feed-forward neural networks. Given an input video, the system first converts it into overlapping clips using a sliding window mechanism. Unlike traditional pose optimization-based methods, SLAM3R directly regresses 3D pointmaps from RGB images in each window and progressively aligns and deforms these local pointmaps to create a globally consistent scene reconstruction - all without explicitly solving any camera parameters. Experiments across datasets consistently show that SLAM3R achieves state-of-the-art reconstruction accuracy and completeness while maintaining real-time performance at 20+ FPS. Code and weights at: \url{https://github.com/PKU-VCL-3DV/SLAM3R}.
Reloc3r: Large-Scale Training of Relative Camera Pose Regression for Generalizable, Fast, and Accurate Visual Localization
Dec 11, 2024



Visual localization aims to determine the camera pose of a query image relative to a database of posed images. In recent years, deep neural networks that directly regress camera poses have gained popularity due to their fast inference capabilities. However, existing methods struggle to either generalize well to new scenes or provide accurate camera pose estimates. To address these issues, we present \textbf{Reloc3r}, a simple yet effective visual localization framework. It consists of an elegantly designed relative pose regression network, and a minimalist motion averaging module for absolute pose estimation. Trained on approximately 8 million posed image pairs, Reloc3r achieves surprisingly good performance and generalization ability. We conduct extensive experiments on 6 public datasets, consistently demonstrating the effectiveness and efficiency of the proposed method. It provides high-quality camera pose estimates in real time and generalizes to novel scenes. Code, weights, and data at: \url{https://github.com/ffrivera0/reloc3r}.
CigTime: Corrective Instruction Generation Through Inverse Motion Editing
Dec 06, 2024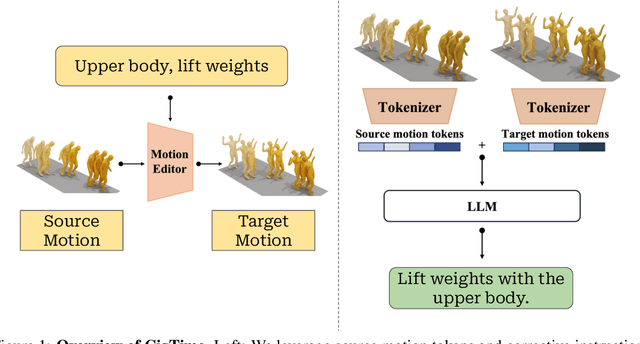
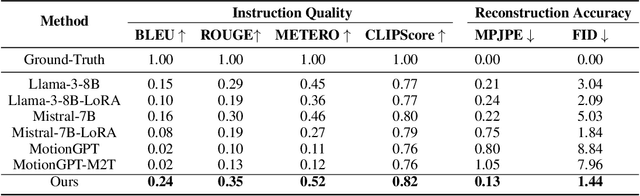

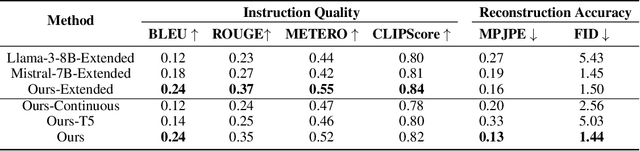
Recent advancements in models linking natural language with human motions have shown significant promise in motion generation and editing based on instructional text. Motivated by applications in sports coaching and motor skill learning, we investigate the inverse problem: generating corrective instructional text, leveraging motion editing and generation models. We introduce a novel approach that, given a user's current motion (source) and the desired motion (target), generates text instructions to guide the user towards achieving the target motion. We leverage large language models to generate corrective texts and utilize existing motion generation and editing frameworks to compile datasets of triplets (source motion, target motion, and corrective text). Using this data, we propose a new motion-language model for generating corrective instructions. We present both qualitative and quantitative results across a diverse range of applications that largely improve upon baselines. Our approach demonstrates its effectiveness in instructional scenarios, offering text-based guidance to correct and enhance user performance.
On the Evaluation of Generative Robotic Simulations
Oct 10, 2024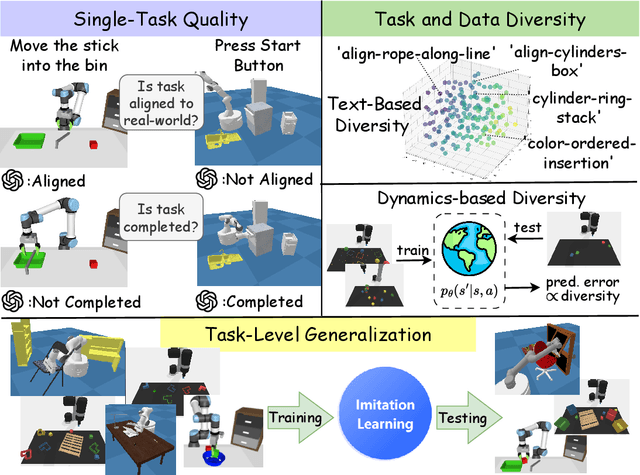
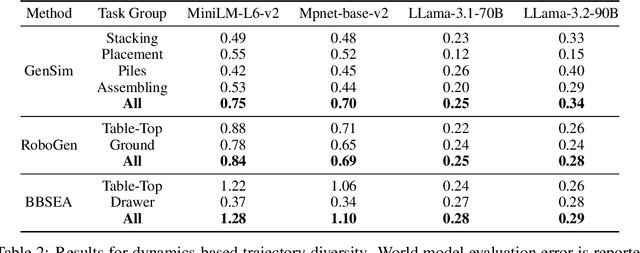
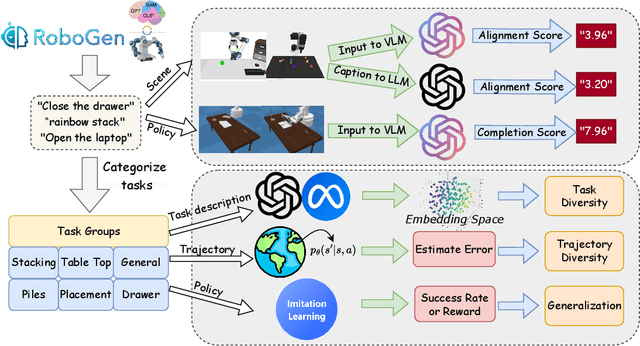
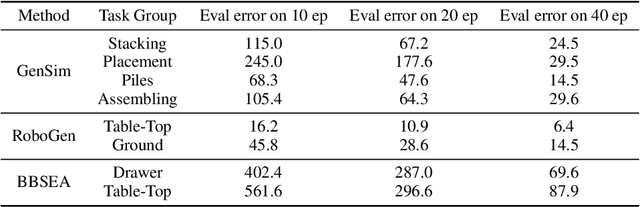
Due to the difficulty of acquiring extensive real-world data, robot simulation has become crucial for parallel training and sim-to-real transfer, highlighting the importance of scalable simulated robotic tasks. Foundation models have demonstrated impressive capacities in autonomously generating feasible robotic tasks. However, this new paradigm underscores the challenge of adequately evaluating these autonomously generated tasks. To address this, we propose a comprehensive evaluation framework tailored to generative simulations. Our framework segments evaluation into three core aspects: quality, diversity, and generalization. For single-task quality, we evaluate the realism of the generated task and the completeness of the generated trajectories using large language models and vision-language models. In terms of diversity, we measure both task and data diversity through text similarity of task descriptions and world model loss trained on collected task trajectories. For task-level generalization, we assess the zero-shot generalization ability on unseen tasks of a policy trained with multiple generated tasks. Experiments conducted on three representative task generation pipelines demonstrate that the results from our framework are highly consistent with human evaluations, confirming the feasibility and validity of our approach. The findings reveal that while metrics of quality and diversity can be achieved through certain methods, no single approach excels across all metrics, suggesting a need for greater focus on balancing these different metrics. Additionally, our analysis further highlights the common challenge of low generalization capability faced by current works. Our anonymous website: https://sites.google.com/view/evaltasks.