 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNVSMask3D: Hard Visual Prompting with Camera Pose Interpolation for 3D Open Vocabulary Instance Segmentation
Apr 20, 2025Vision-language models (VLMs) have demonstrated impressive zero-shot transfer capabilities in image-level visual perception tasks. However, they fall short in 3D instance-level segmentation tasks that require accurate localization and recognition of individual objects. To bridge this gap, we introduce a novel 3D Gaussian Splatting based hard visual prompting approach that leverages camera interpolation to generate diverse viewpoints around target objects without any 2D-3D optimization or fine-tuning. Our method simulates realistic 3D perspectives, effectively augmenting existing hard visual prompts by enforcing geometric consistency across viewpoints. This training-free strategy seamlessly integrates with prior hard visual prompts, enriching object-descriptive features and enabling VLMs to achieve more robust and accurate 3D instance segmentation in diverse 3D scenes.
A2-GNN: Angle-Annular GNN for Visual Descriptor-free Camera Relocalization
Feb 27, 2025Visual localization involves estimating the 6-degree-of-freedom (6-DoF) camera pose within a known scene. A critical step in this process is identifying pixel-to-point correspondences between 2D query images and 3D models. Most advanced approaches currently rely on extensive visual descriptors to establish these correspondences, facing challenges in storage, privacy issues and model maintenance. Direct 2D-3D keypoint matching without visual descriptors is becoming popular as it can overcome those challenges. However, existing descriptor-free methods suffer from low accuracy or heavy computation. Addressing this gap, this paper introduces the Angle-Annular Graph Neural Network (A2-GNN), a simple approach that efficiently learns robust geometric structural representations with annular feature extraction. Specifically, this approach clusters neighbors and embeds each group's distance information and angle as supplementary information to capture local structures. Evaluation on matching and visual localization datasets demonstrates that our approach achieves state-of-the-art accuracy with low computational overhead among visual description-free methods. Our code will be released on https://github.com/YejunZhang/a2-gnn.
DepthLab: From Partial to Complete
Dec 24, 2024



Missing values remain a common challenge for depth data across its wide range of applications, stemming from various causes like incomplete data acquisition and perspective alteration. This work bridges this gap with DepthLab, a foundation depth inpainting model powered by image diffusion priors. Our model features two notable strengths: (1) it demonstrates resilience to depth-deficient regions, providing reliable completion for both continuous areas and isolated points, and (2) it faithfully preserves scale consistency with the conditioned known depth when filling in missing values. Drawing on these advantages, our approach proves its worth in various downstream tasks, including 3D scene inpainting, text-to-3D scene generation, sparse-view reconstruction with DUST3R, and LiDAR depth completion, exceeding current solutions in both numerical performance and visual quality. Our project page with source code is available at https://johanan528.github.io/depthlab_web/.
SLAM3R: Real-Time Dense Scene Reconstruction from Monocular RGB Videos
Dec 12, 2024In this paper, we introduce \textbf{SLAM3R}, a novel and effective monocular RGB SLAM system for real-time and high-quality dense 3D reconstruction. SLAM3R provides an end-to-end solution by seamlessly integrating local 3D reconstruction and global coordinate registration through feed-forward neural networks. Given an input video, the system first converts it into overlapping clips using a sliding window mechanism. Unlike traditional pose optimization-based methods, SLAM3R directly regresses 3D pointmaps from RGB images in each window and progressively aligns and deforms these local pointmaps to create a globally consistent scene reconstruction - all without explicitly solving any camera parameters. Experiments across datasets consistently show that SLAM3R achieves state-of-the-art reconstruction accuracy and completeness while maintaining real-time performance at 20+ FPS. Code and weights at: \url{https://github.com/PKU-VCL-3DV/SLAM3R}.
Reloc3r: Large-Scale Training of Relative Camera Pose Regression for Generalizable, Fast, and Accurate Visual Localization
Dec 11, 2024



Visual localization aims to determine the camera pose of a query image relative to a database of posed images. In recent years, deep neural networks that directly regress camera poses have gained popularity due to their fast inference capabilities. However, existing methods struggle to either generalize well to new scenes or provide accurate camera pose estimates. To address these issues, we present \textbf{Reloc3r}, a simple yet effective visual localization framework. It consists of an elegantly designed relative pose regression network, and a minimalist motion averaging module for absolute pose estimation. Trained on approximately 8 million posed image pairs, Reloc3r achieves surprisingly good performance and generalization ability. We conduct extensive experiments on 6 public datasets, consistently demonstrating the effectiveness and efficiency of the proposed method. It provides high-quality camera pose estimates in real time and generalizes to novel scenes. Code, weights, and data at: \url{https://github.com/ffrivera0/reloc3r}.
DeSplat: Decomposed Gaussian Splatting for Distractor-Free Rendering
Nov 29, 2024Gaussian splatting enables fast novel view synthesis in static 3D environments. However, reconstructing real-world environments remains challenging as distractors or occluders break the multi-view consistency assumption required for accurate 3D reconstruction. Most existing methods rely on external semantic information from pre-trained models, introducing additional computational overhead as pre-processing steps or during optimization. In this work, we propose a novel method, DeSplat, that directly separates distractors and static scene elements purely based on volume rendering of Gaussian primitives. We initialize Gaussians within each camera view for reconstructing the view-specific distractors to separately model the static 3D scene and distractors in the alpha compositing stages. DeSplat yields an explicit scene separation of static elements and distractors, achieving comparable results to prior distractor-free approaches without sacrificing rendering speed. We demonstrate DeSplat's effectiveness on three benchmark data sets for distractor-free novel view synthesis. See the project website at https://aaltoml.github.io/desplat/.
Gaussian Splatting in Mirrors: Reflection-Aware Rendering via Virtual Camera Optimization
Oct 02, 2024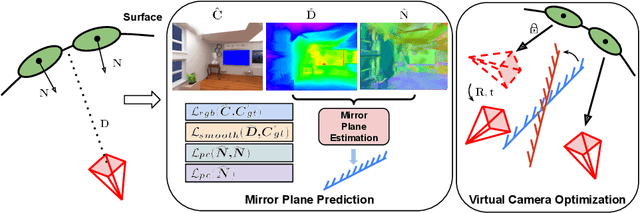
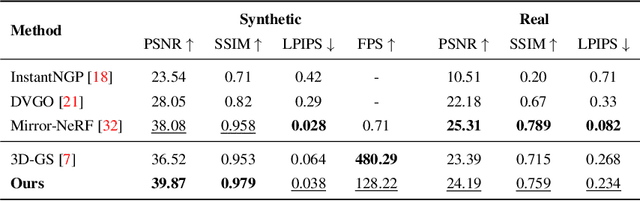
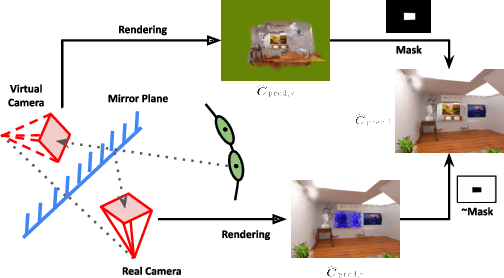

Recent advancements in 3D Gaussian Splatting (3D-GS) have revolutionized novel view synthesis, facilitating real-time, high-quality image rendering. However, in scenarios involving reflective surfaces, particularly mirrors, 3D-GS often misinterprets reflections as virtual spaces, resulting in blurred and inconsistent multi-view rendering within mirrors. Our paper presents a novel method aimed at obtaining high-quality multi-view consistent reflection rendering by modelling reflections as physically-based virtual cameras. We estimate mirror planes with depth and normal estimates from 3D-GS and define virtual cameras that are placed symmetrically about the mirror plane. These virtual cameras are then used to explain mirror reflections in the scene. To address imperfections in mirror plane estimates, we propose a straightforward yet effective virtual camera optimization method to enhance reflection quality. We collect a new mirror dataset including three real-world scenarios for more diverse evaluation. Experimental validation on both Mirror-Nerf and our real-world dataset demonstrate the efficacy of our approach. We achieve comparable or superior results while significantly reducing training time compared to previous state-of-the-art.
Differentiable Product Quantization for Memory Efficient Camera Relocalization
Jul 23, 2024



Camera relocalization relies on 3D models of the scene with a large memory footprint that is incompatible with the memory budget of several applications. One solution to reduce the scene memory size is map compression by removing certain 3D points and descriptor quantization. This achieves high compression but leads to performance drop due to information loss. To address the memory performance trade-off, we train a light-weight scene-specific auto-encoder network that performs descriptor quantization-dequantization in an end-to-end differentiable manner updating both product quantization centroids and network parameters through back-propagation. In addition to optimizing the network for descriptor reconstruction, we encourage it to preserve the descriptor-matching performance with margin-based metric loss functions. Results show that for a local descriptor memory of only 1MB, the synergistic combination of the proposed network and map compression achieves the best performance on the Aachen Day-Night compared to existing compression methods.
DUSt3R: Geometric 3D Vision Made Easy
Dec 21, 2023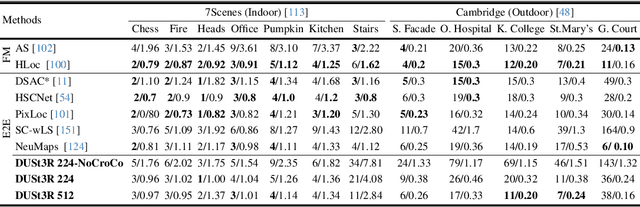
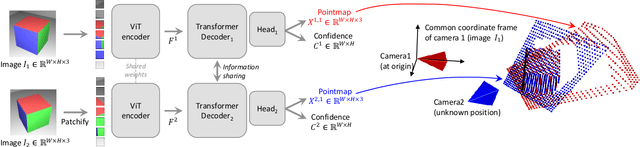
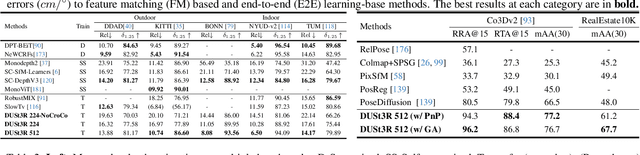

Multi-view stereo reconstruction (MVS) in the wild requires to first estimate the camera parameters e.g. intrinsic and extrinsic parameters. These are usually tedious and cumbersome to obtain, yet they are mandatory to triangulate corresponding pixels in 3D space, which is the core of all best performing MVS algorithms. In this work, we take an opposite stance and introduce DUSt3R, a radically novel paradigm for Dense and Unconstrained Stereo 3D Reconstruction of arbitrary image collections, i.e. operating without prior information about camera calibration nor viewpoint poses. We cast the pairwise reconstruction problem as a regression of pointmaps, relaxing the hard constraints of usual projective camera models. We show that this formulation smoothly unifies the monocular and binocular reconstruction cases. In the case where more than two images are provided, we further propose a simple yet effective global alignment strategy that expresses all pairwise pointmaps in a common reference frame. We base our network architecture on standard Transformer encoders and decoders, allowing us to leverage powerful pretrained models. Our formulation directly provides a 3D model of the scene as well as depth information, but interestingly, we can seamlessly recover from it, pixel matches, relative and absolute camera. Exhaustive experiments on all these tasks showcase that the proposed DUSt3R can unify various 3D vision tasks and set new SoTAs on monocular/multi-view depth estimation as well as relative pose estimation. In summary, DUSt3R makes many geometric 3D vision tasks easy.
DGC-GNN: Descriptor-free Geometric-Color Graph Neural Network for 2D-3D Matching
Jun 21, 2023Direct matching of 2D keypoints in an input image to a 3D point cloud of the scene without requiring visual descriptors has garnered increased interest due to its lower memory requirements, inherent privacy preservation, and reduced need for expensive 3D model maintenance compared to visual descriptor-based methods. However, existing algorithms often compromise on performance, resulting in a significant deterioration compared to their descriptor-based counterparts. In this paper, we introduce DGC-GNN, a novel algorithm that employs a global-to-local Graph Neural Network (GNN) that progressively exploits geometric and color cues to represent keypoints, thereby improving matching robustness. Our global-to-local procedure encodes both Euclidean and angular relations at a coarse level, forming the geometric embedding to guide the local point matching. We evaluate DGC-GNN on both indoor and outdoor datasets, demonstrating that it not only doubles the accuracy of the state-of-the-art descriptor-free algorithm but, also, substantially narrows the performance gap between descriptor-based and descriptor-free methods. The code and trained models will be made publicly available.