 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiveMoments: Reselected Key Photo Restoration in Live Photos via Reference-guided Diffusion
Apr 14, 2026Live Photo captures both a high-quality key photo and a short video clip to preserve the precious dynamics around the captured moment. While users may choose alternative frames as the key photo to capture better expressions or timing, these frames often exhibit noticeable quality degradation, as the photo capture ISP pipeline delivers significantly higher image quality than the video pipeline. This quality gap highlights the need for dedicated restoration techniques to enhance the reselected key photo. To this end, we propose LiveMoments, a reference-guided image restoration framework tailored for the reselected key photo in Live Photos. Our method employs a two-branch neural network: a reference branch that extracts structural and textural information from the original high-quality key photo, and a main branch that restores the reselected frame using the guidance provided by the reference branch. Furthermore, we introduce a unified Motion Alignment module that incorporates motion guidance for spatial alignment at both the latent and image levels. Experiments on real and synthetic Live Photos demonstrate that LiveMoments significantly improves perceptual quality and fidelity over existing solutions, especially in scenes with fast motion or complex structures. Our code is available at https://github.com/OpenVeraTeam/LiveMoments.
One-Shot Refiner: Boosting Feed-forward Novel View Synthesis via One-Step Diffusion
Jan 20, 2026We present a novel framework for high-fidelity novel view synthesis (NVS) from sparse images, addressing key limitations in recent feed-forward 3D Gaussian Splatting (3DGS) methods built on Vision Transformer (ViT) backbones. While ViT-based pipelines offer strong geometric priors, they are often constrained by low-resolution inputs due to computational costs. Moreover, existing generative enhancement methods tend to be 3D-agnostic, resulting in inconsistent structures across views, especially in unseen regions. To overcome these challenges, we design a Dual-Domain Detail Perception Module, which enables handling high-resolution images without being limited by the ViT backbone, and endows Gaussians with additional features to store high-frequency details. We develop a feature-guided diffusion network, which can preserve high-frequency details during the restoration process. We introduce a unified training strategy that enables joint optimization of the ViT-based geometric backbone and the diffusion-based refinement module. Experiments demonstrate that our method can maintain superior generation quality across multiple datasets.
Restore Text First, Enhance Image Later: Two-Stage Scene Text Image Super-Resolution with Glyph Structure Guidance
Oct 24, 2025
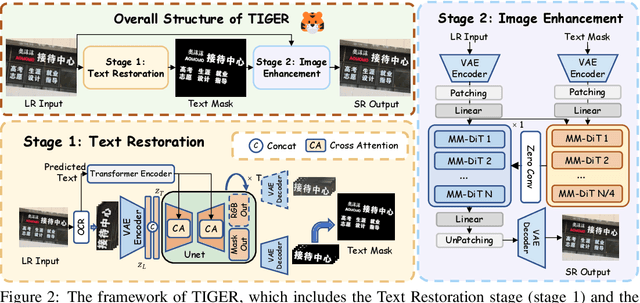
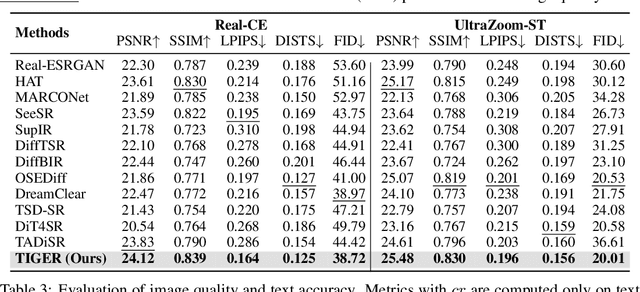
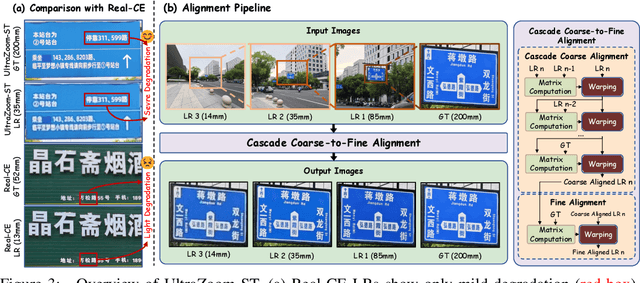
Current generative super-resolution methods show strong performance on natural images but distort text, creating a fundamental trade-off between image quality and textual readability. To address this, we introduce \textbf{TIGER} (\textbf{T}ext-\textbf{I}mage \textbf{G}uided sup\textbf{E}r-\textbf{R}esolution), a novel two-stage framework that breaks this trade-off through a \textit{"text-first, image-later"} paradigm. \textbf{TIGER} explicitly decouples glyph restoration from image enhancement: it first reconstructs precise text structures and then uses them to guide subsequent full-image super-resolution. This glyph-to-image guidance ensures both high fidelity and visual consistency. To support comprehensive training and evaluation, we also contribute the \textbf{UltraZoom-ST} (UltraZoom-Scene Text), the first scene text dataset with extreme zoom (\textbf{$\times$14.29}). Extensive experiments show that \textbf{TIGER} achieves \textbf{state-of-the-art} performance, enhancing readability while preserving overall image quality.
TinySR: Pruning Diffusion for Real-World Image Super-Resolution
Aug 24, 2025
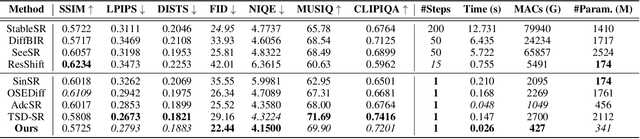
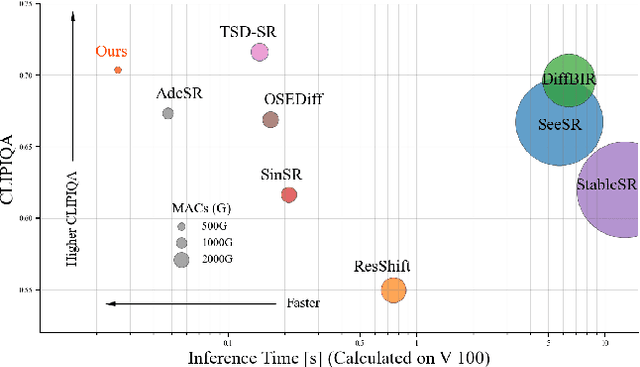
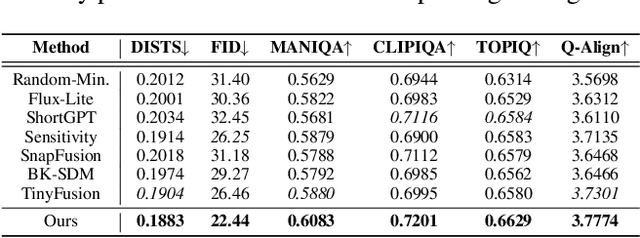
Real-world image super-resolution (Real-ISR) focuses on recovering high-quality images from low-resolution inputs that suffer from complex degradations like noise, blur, and compression. Recently, diffusion models (DMs) have shown great potential in this area by leveraging strong generative priors to restore fine details. However, their iterative denoising process incurs high computational overhead, posing challenges for real-time applications. Although one-step distillation methods, such as OSEDiff and TSD-SR, offer faster inference, they remain fundamentally constrained by their large, over-parameterized model architectures. In this work, we present TinySR, a compact yet effective diffusion model specifically designed for Real-ISR that achieves real-time performance while maintaining perceptual quality. We introduce a Dynamic Inter-block Activation and an Expansion-Corrosion Strategy to facilitate more effective decision-making in depth pruning. We achieve VAE compression through channel pruning, attention removal and lightweight SepConv. We eliminate time- and prompt-related modules and perform pre-caching techniques to further speed up the model. TinySR significantly reduces computational cost and model size, achieving up to 5.68x speedup and 83% parameter reduction compared to its teacher TSD-SR, while still providing high quality results.
BokehDiff: Neural Lens Blur with One-Step Diffusion
Jul 24, 2025We introduce BokehDiff, a novel lens blur rendering method that achieves physically accurate and visually appealing outcomes, with the help of generative diffusion prior. Previous methods are bounded by the accuracy of depth estimation, generating artifacts in depth discontinuities. Our method employs a physics-inspired self-attention module that aligns with the image formation process, incorporating depth-dependent circle of confusion constraint and self-occlusion effects. We adapt the diffusion model to the one-step inference scheme without introducing additional noise, and achieve results of high quality and fidelity. To address the lack of scalable paired data, we propose to synthesize photorealistic foregrounds with transparency with diffusion models, balancing authenticity and scene diversity.
Text-Aware Real-World Image Super-Resolution via Diffusion Model with Joint Segmentation Decoders
Jun 05, 2025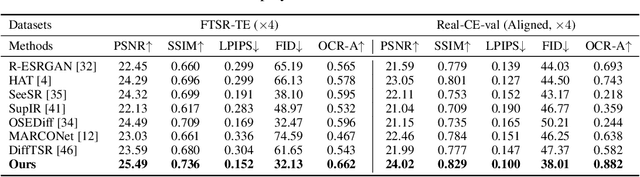
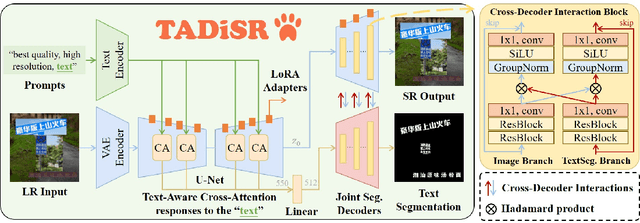
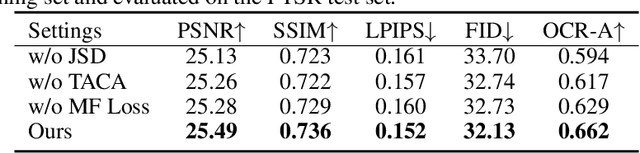

The introduction of generative models has significantly advanced image super-resolution (SR) in handling real-world degradations. However, they often incur fidelity-related issues, particularly distorting textual structures. In this paper, we introduce a novel diffusion-based SR framework, namely TADiSR, which integrates text-aware attention and joint segmentation decoders to recover not only natural details but also the structural fidelity of text regions in degraded real-world images. Moreover, we propose a complete pipeline for synthesizing high-quality images with fine-grained full-image text masks, combining realistic foreground text regions with detailed background content. Extensive experiments demonstrate that our approach substantially enhances text legibility in super-resolved images, achieving state-of-the-art performance across multiple evaluation metrics and exhibiting strong generalization to real-world scenarios. Our code is available at \href{https://github.com/mingcv/TADiSR}{here}.
Textualize Visual Prompt for Image Editing via Diffusion Bridge
Jan 07, 2025



Visual prompt, a pair of before-and-after edited images, can convey indescribable imagery transformations and prosper in image editing. However, current visual prompt methods rely on a pretrained text-guided image-to-image generative model that requires a triplet of text, before, and after images for retraining over a text-to-image model. Such crafting triplets and retraining processes limit the scalability and generalization of editing. In this paper, we present a framework based on any single text-to-image model without reliance on the explicit image-to-image model thus enhancing the generalizability and scalability. Specifically, by leveraging the probability-flow ordinary equation, we construct a diffusion bridge to transfer the distribution between before-and-after images under the text guidance. By optimizing the text via the bridge, the framework adaptively textualizes the editing transformation conveyed by visual prompts into text embeddings without other models. Meanwhile, we introduce differential attention control during text optimization, which disentangles the text embedding from the invariance of the before-and-after images and makes it solely capture the delicate transformation and generalize to edit various images. Experiments on real images validate competitive results on the generalization, contextual coherence, and high fidelity for delicate editing with just one image pair as the visual prompt.
CoMPaSS: Enhancing Spatial Understanding in Text-to-Image Diffusion Models
Dec 17, 2024



Text-to-image diffusion models excel at generating photorealistic images, but commonly struggle to render accurate spatial relationships described in text prompts. We identify two core issues underlying this common failure: 1) the ambiguous nature of spatial-related data in existing datasets, and 2) the inability of current text encoders to accurately interpret the spatial semantics of input descriptions. We address these issues with CoMPaSS, a versatile training framework that enhances spatial understanding of any T2I diffusion model. CoMPaSS solves the ambiguity of spatial-related data with the Spatial Constraints-Oriented Pairing (SCOP) data engine, which curates spatially-accurate training data through a set of principled spatial constraints. To better exploit the curated high-quality spatial priors, CoMPaSS further introduces a Token ENcoding ORdering (TENOR) module to allow better exploitation of high-quality spatial priors, effectively compensating for the shortcoming of text encoders. Extensive experiments on four popular open-weight T2I diffusion models covering both UNet- and MMDiT-based architectures demonstrate the effectiveness of CoMPaSS by setting new state-of-the-arts with substantial relative gains across well-known benchmarks on spatial relationships generation, including VISOR (+98%), T2I-CompBench Spatial (+67%), and GenEval Position (+131%). Code will be available at https://github.com/blurgyy/CoMPaSS.
SLAM3R: Real-Time Dense Scene Reconstruction from Monocular RGB Videos
Dec 12, 2024In this paper, we introduce \textbf{SLAM3R}, a novel and effective monocular RGB SLAM system for real-time and high-quality dense 3D reconstruction. SLAM3R provides an end-to-end solution by seamlessly integrating local 3D reconstruction and global coordinate registration through feed-forward neural networks. Given an input video, the system first converts it into overlapping clips using a sliding window mechanism. Unlike traditional pose optimization-based methods, SLAM3R directly regresses 3D pointmaps from RGB images in each window and progressively aligns and deforms these local pointmaps to create a globally consistent scene reconstruction - all without explicitly solving any camera parameters. Experiments across datasets consistently show that SLAM3R achieves state-of-the-art reconstruction accuracy and completeness while maintaining real-time performance at 20+ FPS. Code and weights at: \url{https://github.com/PKU-VCL-3DV/SLAM3R}.
Reloc3r: Large-Scale Training of Relative Camera Pose Regression for Generalizable, Fast, and Accurate Visual Localization
Dec 11, 2024



Visual localization aims to determine the camera pose of a query image relative to a database of posed images. In recent years, deep neural networks that directly regress camera poses have gained popularity due to their fast inference capabilities. However, existing methods struggle to either generalize well to new scenes or provide accurate camera pose estimates. To address these issues, we present \textbf{Reloc3r}, a simple yet effective visual localization framework. It consists of an elegantly designed relative pose regression network, and a minimalist motion averaging module for absolute pose estimation. Trained on approximately 8 million posed image pairs, Reloc3r achieves surprisingly good performance and generalization ability. We conduct extensive experiments on 6 public datasets, consistently demonstrating the effectiveness and efficiency of the proposed method. It provides high-quality camera pose estimates in real time and generalizes to novel scenes. Code, weights, and data at: \url{https://github.com/ffrivera0/reloc3r}.