 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrincipled Reflection Separation via Nonlinear Superposition and Feature Interaction
Jun 01, 2026Single-image reflection separation is fundamentally challenged by the entanglement of transmission and reflection layers under complex image formation processes. Existing approaches largely rely on simplified assumptions or independent modeling, limiting their ability to handle real-world scenarios. In this work, we revisit the problem from a unified perspective and identify a key issue of existing approaches, i.e., the widely adopted linear composition model in the sRGB domain fails to capture the nonlinear coupling introduced by real-world image signal processing pipelines. To address this, we introduce a learnable nonlinear superposition model that more faithfully characterizes layer interactions and improves decomposition fidelity. Building upon this formulation, we propose a generalized dual-stream interactive framework that explicitly models bidirectional dependencies between transmission and reflection through feature exchange. This framework unifies activation-, gating-, and attention-based interaction mechanisms, and is compatible with both CNN and Transformer backbones. Extensive experiments on diverse real-world benchmarks demonstrate that the proposed approach achieves superior performance with strong generalization capability. More importantly, our study reveals that reflection separation is not about undoing a linear mixture, but about learning nonlinear formation and interaction}, offering new insights into the design of principled image decomposition models. Code and models are publicly available at https://mingcv.github.io/DIRS-Page.
On the Global Photometric Alignment for Low-Level Vision
Apr 09, 2026Supervised low-level vision models rely on pixel-wise losses against paired references, yet paired training sets exhibit per-pair photometric inconsistency, say, different image pairs demand different global brightness, color, or white-balance mappings. This inconsistency enters through task-intrinsic photometric transfer (e.g., low-light enhancement) or unintended acquisition shifts (e.g., de-raining), and in either case causes an optimization pathology. Standard reconstruction losses allocate disproportionate gradient budget to conflicting per-pair photometric targets, crowding out content restoration. In this paper, we investigate this issue and prove that, under least-squares decomposition, the photometric and structural components of the prediction-target residual are orthogonal, and that the spatially dense photometric component dominates the gradient energy. Motivated by this analysis, we propose Photometric Alignment Loss (PAL). This flexible supervision objective discounts nuisance photometric discrepancy via closed-form affine color alignment while preserving restoration-relevant supervision, requiring only covariance statistics and tiny matrix inversion with negligible overhead. Across 6 tasks, 16 datasets, and 16 architectures, PAL consistently improves metrics and generalization. The implementation is in the appendix.
FAROS: Robust Federated Learning with Adaptive Scaling against Backdoor Attacks
Jan 05, 2026Federated Learning (FL) enables multiple clients to collaboratively train a shared model without exposing local data. However, backdoor attacks pose a significant threat to FL. These attacks aim to implant a stealthy trigger into the global model, causing it to mislead on inputs that possess a specific trigger while functioning normally on benign data. Although pre-aggregation detection is a main defense direction, existing state-of-the-art defenses often rely on fixed defense parameters. This reliance makes them vulnerable to single-point-of-failure risks, rendering them less effective against sophisticated attackers. To address these limitations, we propose FAROS, an enhanced FL framework that incorporates Adaptive Differential Scaling (ADS) and Robust Core-set Computing (RCC). The ADS mechanism adjusts the defense's sensitivity dynamically, based on the dispersion of uploaded gradients by clients in each round. This allows it to counter attackers who strategically shift between stealthiness and effectiveness. Furthermore, the RCC effectively mitigates the risk of single-point failure by computing the centroid of a core set comprising clients with the highest confidence. We conducted extensive experiments across various datasets, models, and attack scenarios. The results demonstrate that our method outperforms current defenses in both attack success rate and main task accuracy.
NTIRE 2025 Image Shadow Removal Challenge Report
Jun 18, 2025



This work examines the findings of the NTIRE 2025 Shadow Removal Challenge. A total of 306 participants have registered, with 17 teams successfully submitting their solutions during the final evaluation phase. Following the last two editions, this challenge had two evaluation tracks: one focusing on reconstruction fidelity and the other on visual perception through a user study. Both tracks were evaluated with images from the WSRD+ dataset, simulating interactions between self- and cast-shadows with a large number of diverse objects, textures, and materials.
Text-Aware Real-World Image Super-Resolution via Diffusion Model with Joint Segmentation Decoders
Jun 05, 2025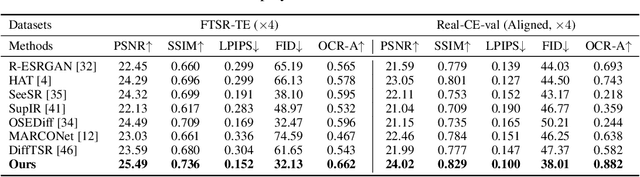
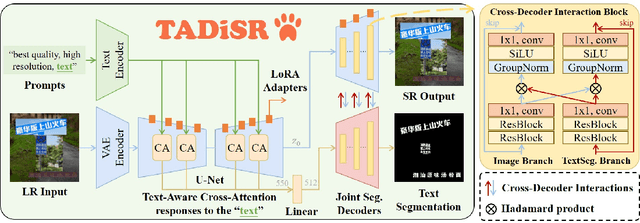
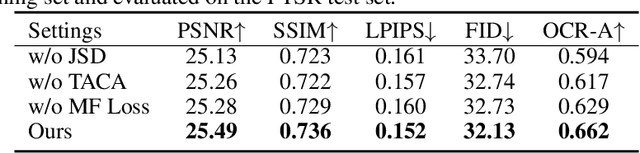

The introduction of generative models has significantly advanced image super-resolution (SR) in handling real-world degradations. However, they often incur fidelity-related issues, particularly distorting textual structures. In this paper, we introduce a novel diffusion-based SR framework, namely TADiSR, which integrates text-aware attention and joint segmentation decoders to recover not only natural details but also the structural fidelity of text regions in degraded real-world images. Moreover, we propose a complete pipeline for synthesizing high-quality images with fine-grained full-image text masks, combining realistic foreground text regions with detailed background content. Extensive experiments demonstrate that our approach substantially enhances text legibility in super-resolved images, achieving state-of-the-art performance across multiple evaluation metrics and exhibiting strong generalization to real-world scenarios. Our code is available at \href{https://github.com/mingcv/TADiSR}{here}.
MODEM: A Morton-Order Degradation Estimation Mechanism for Adverse Weather Image Recovery
May 23, 2025


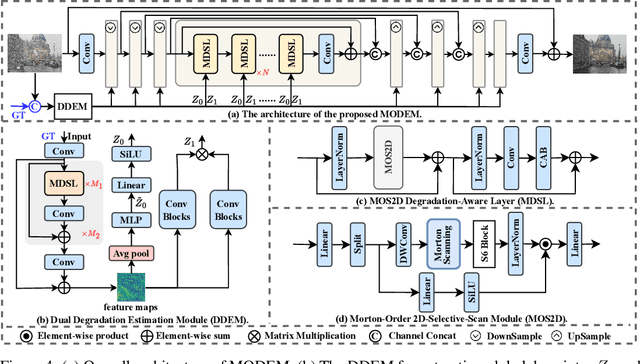
Restoring images degraded by adverse weather remains a significant challenge due to the highly non-uniform and spatially heterogeneous nature of weather-induced artifacts, e.g., fine-grained rain streaks versus widespread haze. Accurately estimating the underlying degradation can intuitively provide restoration models with more targeted and effective guidance, enabling adaptive processing strategies. To this end, we propose a Morton-Order Degradation Estimation Mechanism (MODEM) for adverse weather image restoration. Central to MODEM is the Morton-Order 2D-Selective-Scan Module (MOS2D), which integrates Morton-coded spatial ordering with selective state-space models to capture long-range dependencies while preserving local structural coherence. Complementing MOS2D, we introduce a Dual Degradation Estimation Module (DDEM) that disentangles and estimates both global and local degradation priors. These priors dynamically condition the MOS2D modules, facilitating adaptive and context-aware restoration. Extensive experiments and ablation studies demonstrate that MODEM achieves state-of-the-art results across multiple benchmarks and weather types, highlighting its effectiveness in modeling complex degradation dynamics. Our code will be released at https://github.com/hainuo-wang/MODEM.git.
EmotiveTalk: Expressive Talking Head Generation through Audio Information Decoupling and Emotional Video Diffusion
Nov 23, 2024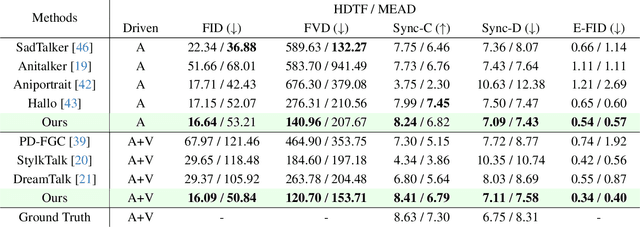
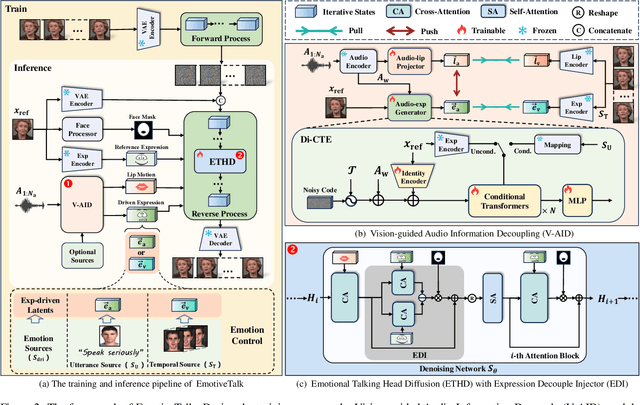
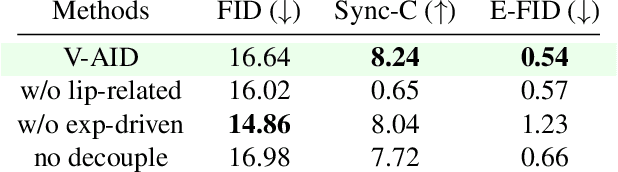

Diffusion models have revolutionized the field of talking head generation, yet still face challenges in expressiveness, controllability, and stability in long-time generation. In this research, we propose an EmotiveTalk framework to address these issues. Firstly, to realize better control over the generation of lip movement and facial expression, a Vision-guided Audio Information Decoupling (V-AID) approach is designed to generate audio-based decoupled representations aligned with lip movements and expression. Specifically, to achieve alignment between audio and facial expression representation spaces, we present a Diffusion-based Co-speech Temporal Expansion (Di-CTE) module within V-AID to generate expression-related representations under multi-source emotion condition constraints. Then we propose a well-designed Emotional Talking Head Diffusion (ETHD) backbone to efficiently generate highly expressive talking head videos, which contains an Expression Decoupling Injection (EDI) module to automatically decouple the expressions from reference portraits while integrating the target expression information, achieving more expressive generation performance. Experimental results show that EmotiveTalk can generate expressive talking head videos, ensuring the promised controllability of emotions and stability during long-time generation, yielding state-of-the-art performance compared to existing methods.
Reversible Decoupling Network for Single Image Reflection Removal
Oct 10, 2024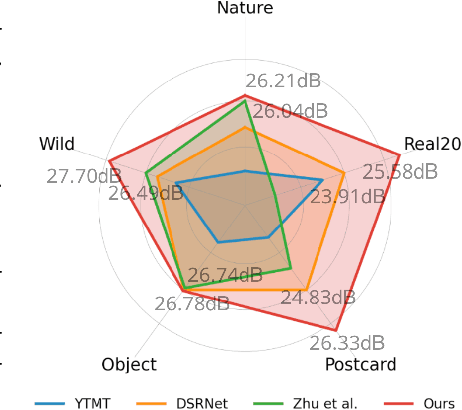
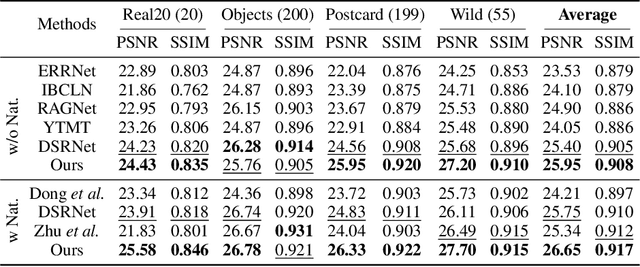
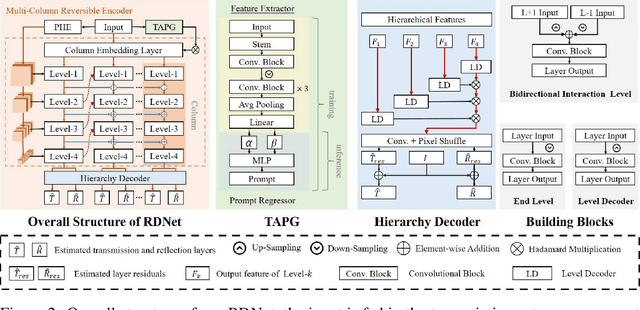

Recent deep-learning-based approaches to single-image reflection removal have shown promising advances, primarily for two reasons: 1) the utilization of recognition-pretrained features as inputs, and 2) the design of dual-stream interaction networks. However, according to the Information Bottleneck principle, high-level semantic clues tend to be compressed or discarded during layer-by-layer propagation. Additionally, interactions in dual-stream networks follow a fixed pattern across different layers, limiting overall performance. To address these limitations, we propose a novel architecture called Reversible Decoupling Network (RDNet), which employs a reversible encoder to secure valuable information while flexibly decoupling transmission- and reflection-relevant features during the forward pass. Furthermore, we customize a transmission-rate-aware prompt generator to dynamically calibrate features, further boosting performance. Extensive experiments demonstrate the superiority of RDNet over existing SOTA methods on five widely-adopted benchmark datasets. Our code will be made publicly available.
Diag2Diag: Multi modal super resolution for physics discovery with application to fusion
May 09, 2024This paper introduces a groundbreaking multi-modal neural network model designed for resolution enhancement, which innovatively leverages inter-diagnostic correlations within a system. Traditional approaches have primarily focused on uni-modal enhancement strategies, such as pixel-based image enhancement or heuristic signal interpolation. In contrast, our model employs a novel methodology by harnessing the diagnostic relationships within the physics of fusion plasma. Initially, we establish the correlation among diagnostics within the tokamak. Subsequently, we utilize these correlations to substantially enhance the temporal resolution of the Thomson Scattering diagnostic, which assesses plasma density and temperature. By increasing its resolution from conventional 200Hz to 500kHz, we facilitate a new level of insight into plasma behavior, previously attainable only through computationally intensive simulations. This enhancement goes beyond simple interpolation, offering novel perspectives on the underlying physical phenomena governing plasma dynamics.
Single Image Reflection Separation via Component Synergy
Aug 19, 2023The reflection superposition phenomenon is complex and widely distributed in the real world, which derives various simplified linear and nonlinear formulations of the problem. In this paper, based on the investigation of the weaknesses of existing models, we propose a more general form of the superposition model by introducing a learnable residue term, which can effectively capture residual information during decomposition, guiding the separated layers to be complete. In order to fully capitalize on its advantages, we further design the network structure elaborately, including a novel dual-stream interaction mechanism and a powerful decomposition network with a semantic pyramid encoder. Extensive experiments and ablation studies are conducted to verify our superiority over state-of-the-art approaches on multiple real-world benchmark datasets. Our code is publicly available at https://github.com/mingcv/DSRNet.