 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFace Normal Estimation from Rags to Riches
Jan 05, 2026Although recent approaches to face normal estimation have achieved promising results, their effectiveness heavily depends on large-scale paired data for training. This paper concentrates on relieving this requirement via developing a coarse-to-fine normal estimator. Concretely, our method first trains a neat model from a small dataset to produce coarse face normals that perform as guidance (called exemplars) for the following refinement. A self-attention mechanism is employed to capture long-range dependencies, thus remedying severe local artifacts left in estimated coarse facial normals. Then, a refinement network is customized for the sake of mapping input face images together with corresponding exemplars to fine-grained high-quality facial normals. Such a logical function split can significantly cut the requirement of massive paired data and computational resource. Extensive experiments and ablation studies are conducted to demonstrate the efficacy of our design and reveal its superiority over state-of-the-art methods in terms of both training expense as well as estimation quality. Our code and models are open-sourced at: https://github.com/AutoHDR/FNR2R.git.
Temporal Reasoning with Large Language Models Augmented by Evolving Knowledge Graphs
Sep 18, 2025



Large language models (LLMs) excel at many language understanding tasks but struggle to reason over knowledge that evolves. To address this, recent work has explored augmenting LLMs with knowledge graphs (KGs) to provide structured, up-to-date information. However, many existing approaches assume a static snapshot of the KG and overlook the temporal dynamics and factual inconsistencies inherent in real-world data. To address the challenge of reasoning over temporally shifting knowledge, we propose EvoReasoner, a temporal-aware multi-hop reasoning algorithm that performs global-local entity grounding, multi-route decomposition, and temporally grounded scoring. To ensure that the underlying KG remains accurate and up-to-date, we introduce EvoKG, a noise-tolerant KG evolution module that incrementally updates the KG from unstructured documents through confidence-based contradiction resolution and temporal trend tracking. We evaluate our approach on temporal QA benchmarks and a novel end-to-end setting where the KG is dynamically updated from raw documents. Our method outperforms both prompting-based and KG-enhanced baselines, effectively narrowing the gap between small and large LLMs on dynamic question answering. Notably, an 8B-parameter model using our approach matches the performance of a 671B model prompted seven months later. These results highlight the importance of combining temporal reasoning with KG evolution for robust and up-to-date LLM performance. Our code is publicly available at github.com/junhongmit/TREK.
NTIRE 2025 Image Shadow Removal Challenge Report
Jun 18, 2025



This work examines the findings of the NTIRE 2025 Shadow Removal Challenge. A total of 306 participants have registered, with 17 teams successfully submitting their solutions during the final evaluation phase. Following the last two editions, this challenge had two evaluation tracks: one focusing on reconstruction fidelity and the other on visual perception through a user study. Both tracks were evaluated with images from the WSRD+ dataset, simulating interactions between self- and cast-shadows with a large number of diverse objects, textures, and materials.
Text-Aware Real-World Image Super-Resolution via Diffusion Model with Joint Segmentation Decoders
Jun 05, 2025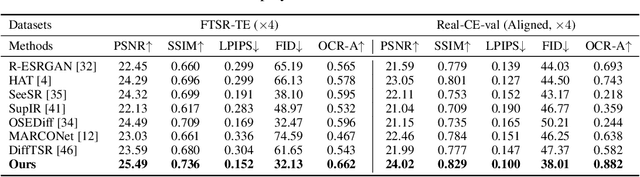
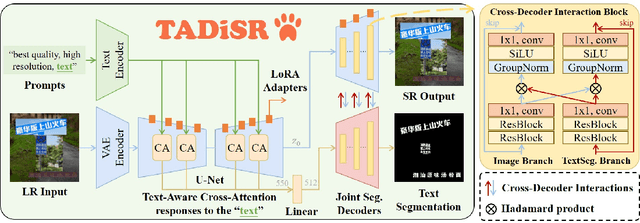
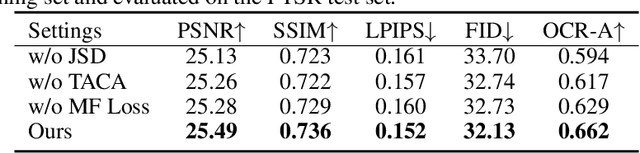

The introduction of generative models has significantly advanced image super-resolution (SR) in handling real-world degradations. However, they often incur fidelity-related issues, particularly distorting textual structures. In this paper, we introduce a novel diffusion-based SR framework, namely TADiSR, which integrates text-aware attention and joint segmentation decoders to recover not only natural details but also the structural fidelity of text regions in degraded real-world images. Moreover, we propose a complete pipeline for synthesizing high-quality images with fine-grained full-image text masks, combining realistic foreground text regions with detailed background content. Extensive experiments demonstrate that our approach substantially enhances text legibility in super-resolved images, achieving state-of-the-art performance across multiple evaluation metrics and exhibiting strong generalization to real-world scenarios. Our code is available at \href{https://github.com/mingcv/TADiSR}{here}.
MODEM: A Morton-Order Degradation Estimation Mechanism for Adverse Weather Image Recovery
May 23, 2025


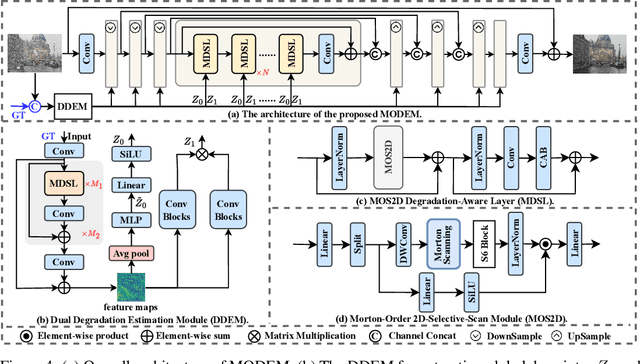
Restoring images degraded by adverse weather remains a significant challenge due to the highly non-uniform and spatially heterogeneous nature of weather-induced artifacts, e.g., fine-grained rain streaks versus widespread haze. Accurately estimating the underlying degradation can intuitively provide restoration models with more targeted and effective guidance, enabling adaptive processing strategies. To this end, we propose a Morton-Order Degradation Estimation Mechanism (MODEM) for adverse weather image restoration. Central to MODEM is the Morton-Order 2D-Selective-Scan Module (MOS2D), which integrates Morton-coded spatial ordering with selective state-space models to capture long-range dependencies while preserving local structural coherence. Complementing MOS2D, we introduce a Dual Degradation Estimation Module (DDEM) that disentangles and estimates both global and local degradation priors. These priors dynamically condition the MOS2D modules, facilitating adaptive and context-aware restoration. Extensive experiments and ablation studies demonstrate that MODEM achieves state-of-the-art results across multiple benchmarks and weather types, highlighting its effectiveness in modeling complex degradation dynamics. Our code will be released at https://github.com/hainuo-wang/MODEM.git.
Reasoning of Large Language Models over Knowledge Graphs with Super-Relations
Mar 28, 2025



While large language models (LLMs) have made significant progress in processing and reasoning over knowledge graphs, current methods suffer from a high non-retrieval rate. This limitation reduces the accuracy of answering questions based on these graphs. Our analysis reveals that the combination of greedy search and forward reasoning is a major contributor to this issue. To overcome these challenges, we introduce the concept of super-relations, which enables both forward and backward reasoning by summarizing and connecting various relational paths within the graph. This holistic approach not only expands the search space, but also significantly improves retrieval efficiency. In this paper, we propose the ReKnoS framework, which aims to Reason over Knowledge Graphs with Super-Relations. Our framework's key advantages include the inclusion of multiple relation paths through super-relations, enhanced forward and backward reasoning capabilities, and increased efficiency in querying LLMs. These enhancements collectively lead to a substantial improvement in the successful retrieval rate and overall reasoning performance. We conduct extensive experiments on nine real-world datasets to evaluate ReKnoS, and the results demonstrate the superior performance of ReKnoS over existing state-of-the-art baselines, with an average accuracy gain of 2.92%.
Differential Alignment for Domain Adaptive Object Detection
Dec 17, 2024



Domain adaptive object detection (DAOD) aims to generalize an object detector trained on labeled source-domain data to a target domain without annotations, the core principle of which is \emph{source-target feature alignment}. Typically, existing approaches employ adversarial learning to align the distributions of the source and target domains as a whole, barely considering the varying significance of distinct regions, say instances under different circumstances and foreground \emph{vs} background areas, during feature alignment. To overcome the shortcoming, we investigates a differential feature alignment strategy. Specifically, a prediction-discrepancy feedback instance alignment module (dubbed PDFA) is designed to adaptively assign higher weights to instances of higher teacher-student detection discrepancy, effectively handling heavier domain-specific information. Additionally, an uncertainty-based foreground-oriented image alignment module (UFOA) is proposed to explicitly guide the model to focus more on regions of interest. Extensive experiments on widely-used DAOD datasets together with ablation studies are conducted to demonstrate the efficacy of our proposed method and reveal its superiority over other SOTA alternatives. Our code is available at https://github.com/EstrellaXyu/Differential-Alignment-for-DAOD.
ShadowHack: Hacking Shadows via Luminance-Color Divide and Conquer
Dec 03, 2024
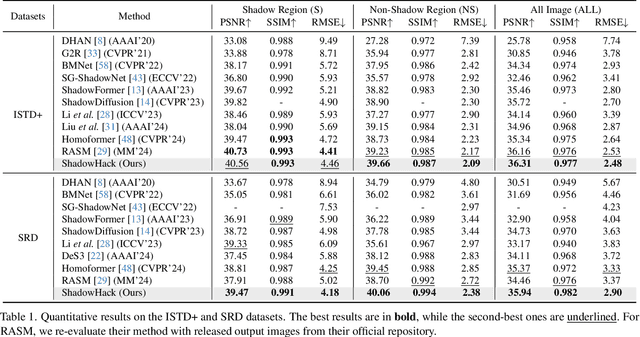
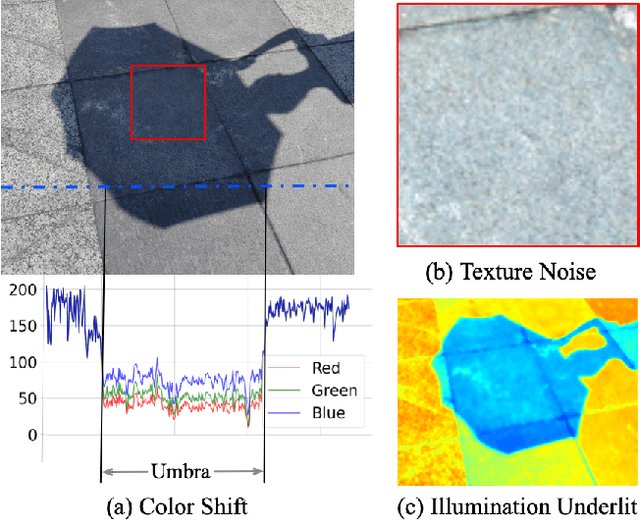
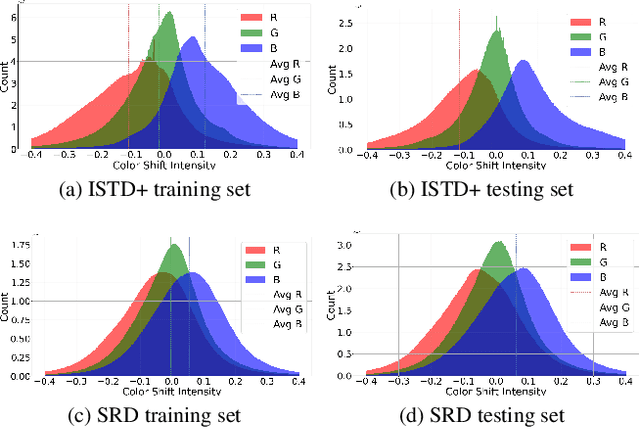
Shadows introduce challenges such as reduced brightness, texture deterioration, and color distortion in images, complicating a holistic solution. This study presents \textbf{ShadowHack}, a divide-and-conquer strategy that tackles these complexities by decomposing the original task into luminance recovery and color remedy. To brighten shadow regions and repair the corrupted textures in the luminance space, we customize LRNet, a U-shaped network with a rectified outreach attention module, to enhance information interaction and recalibrate contaminated attention maps. With luminance recovered, CRNet then leverages cross-attention mechanisms to revive vibrant colors, producing visually compelling results. Extensive experiments on multiple datasets are conducted to demonstrate the superiority of ShadowHack over existing state-of-the-art solutions both quantitatively and qualitatively, highlighting the effectiveness of our design. Our code will be made publicly available at https://github.com/lime-j/ShadowHack
Regional Attention for Shadow Removal
Nov 21, 2024



Shadow, as a natural consequence of light interacting with objects, plays a crucial role in shaping the aesthetics of an image, which however also impairs the content visibility and overall visual quality. Recent shadow removal approaches employ the mechanism of attention, due to its effectiveness, as a key component. However, they often suffer from two issues including large model size and high computational complexity for practical use. To address these shortcomings, this work devises a lightweight yet accurate shadow removal framework. First, we analyze the characteristics of the shadow removal task to seek the key information required for reconstructing shadow regions and designing a novel regional attention mechanism to effectively capture such information. Then, we customize a Regional Attention Shadow Removal Model (RASM, in short), which leverages non-shadow areas to assist in restoring shadow ones. Unlike existing attention-based models, our regional attention strategy allows each shadow region to interact more rationally with its surrounding non-shadow areas, for seeking the regional contextual correlation between shadow and non-shadow areas. Extensive experiments are conducted to demonstrate that our proposed method delivers superior performance over other state-of-the-art models in terms of accuracy and efficiency, making it appealing for practical applications.
LIME-Eval: Rethinking Low-light Image Enhancement Evaluation via Object Detection
Oct 11, 2024



Due to the nature of enhancement--the absence of paired ground-truth information, high-level vision tasks have been recently employed to evaluate the performance of low-light image enhancement. A widely-used manner is to see how accurately an object detector trained on enhanced low-light images by different candidates can perform with respect to annotated semantic labels. In this paper, we first demonstrate that the mentioned approach is generally prone to overfitting, and thus diminishes its measurement reliability. In search of a proper evaluation metric, we propose LIME-Bench, the first online benchmark platform designed to collect human preferences for low-light enhancement, providing a valuable dataset for validating the correlation between human perception and automated evaluation metrics. We then customize LIME-Eval, a novel evaluation framework that utilizes detectors pre-trained on standard-lighting datasets without object annotations, to judge the quality of enhanced images. By adopting an energy-based strategy to assess the accuracy of output confidence maps, our LIME-Eval can simultaneously bypass biases associated with retraining detectors and circumvent the reliance on annotations for dim images. Comprehensive experiments are provided to reveal the effectiveness of our LIME-Eval. Our benchmark platform (https://huggingface.co/spaces/lime-j/eval) and code (https://github.com/lime-j/lime-eval) are available online.