 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMult-DPO: Multinomial Direct Preference Optimization for Recommender Systems
Jun 08, 2026Direct preference optimization (DPO) is a simple and effective alignment strategy for large language models (LLMs) based on pairwise preferences. In recommender systems, however, user feedback is rarely pairwise. For a given context, e.g., a user, a session, or a conversation, we typically observe set-wise preferences with multiple positive items, where every positive item should outrank every unobserved or explicitly negative item, with no prescribed order among the positives or the negatives themselves. A natural generalization is to use the Plackett-Luce (PL) reward model, which extends the Bradley-Terry reward model underlying vanilla DPO from pairwise preferences to full rankings of candidates. However, we show that adapting the PL model to set-wise preferences requires marginalizing over all positive orderings, where the resulting expression is combinatorial in complexity. To address this fundamental challenge, we propose Mult-DPO, a novel DPO objective with a tractable multinomial surrogate likelihood over set-wise preference events for the user-preference alignment of LLM-based recommender systems. The multinomial construction is not itself a ranking distribution, but it is defined on the same reward-induced weight space and admits a closed-form DPO-style objective, enabling direct alignment of LLMs with multiple candidates through a classification-style objective. In addition, we prove that the multinomial DPO loss is a tractable upper bound on the marginalized PL DPO loss when optimizing against the set-wise preference data. We further characterize the tightness of this bound in terms of the relative total weight of positives versus negatives, which provides insights into tightening the bound with richer or harder negatives. Finally, we extend Mult-DPO to the alignment of LLMs with multiple preference levels. Code is available at https://github.com/yaochenzhu/Mult_DPO
A Survey of Weight Space Learning: Understanding, Representation, and Generation
Mar 10, 2026Neural network weights are typically viewed as the end product of training, while most deep learning research focuses on data, features, and architectures. However, recent advances show that the set of all possible weight values (weight space) itself contains rich structure: pretrained models form organized distributions, exhibit symmetries, and can be embedded, compared, or even generated. Understanding such structures has tremendous impact on how neural networks are analyzed and compared, and on how knowledge is transferred across models, beyond individual training instances. This emerging research direction, which we refer to as Weight Space Learning (WSL), treats neural weights as a meaningful domain for analysis and modeling. This survey provides the first unified taxonomy of WSL. We categorize existing methods into three core dimensions: Weight Space Understanding (WSU), which studies the geometry and symmetries of weights; Weight Space Representation (WSR), which learns embeddings over model weights; and Weight Space Generation (WSG), which synthesizes new weights through hypernetworks or generative models. We further show how these developments enable practical applications, including model retrieval, continual and federated learning, neural architecture search, and data-free reconstruction. By consolidating fragmented progress under a coherent framework, this survey highlights weight space as a learnable, structured domain with growing impact across model analysis, transferring, and weight generation. We release an accompanying resource at https://github.com/Zehong-Wang/Awesome-Weight-Space-Learning.
Mind the Gap in Cultural Alignment: Task-Aware Culture Management for Large Language Models
Feb 25, 2026Large language models (LLMs) are increasingly deployed in culturally sensitive real-world tasks. However, existing cultural alignment approaches fail to align LLMs' broad cultural values with the specific goals of downstream tasks and suffer from cross-culture interference. We propose CultureManager, a novel pipeline for task-specific cultural alignment. CultureManager synthesizes task-aware cultural data in line with target task formats, grounded in culturally relevant web search results. To prevent conflicts between cultural norms, it manages multi-culture knowledge learned in separate adapters with a culture router that selects the appropriate one to apply. Experiments across ten national cultures and culture-sensitive tasks show consistent improvements over prompt-based and fine-tuning baselines. Our results demonstrate the necessity of task adaptation and modular culture management for effective cultural alignment.
CausalFlip: A Benchmark for LLM Causal Judgment Beyond Semantic Matching
Feb 23, 2026As large language models (LLMs) witness increasing deployment in complex, high-stakes decision-making scenarios, it becomes imperative to ground their reasoning in causality rather than spurious correlations. However, strong performance on traditional reasoning benchmarks does not guarantee true causal reasoning ability of LLMs, as high accuracy may still arise from memorizing semantic patterns instead of analyzing the underlying true causal structures. To bridge this critical gap, we propose a new causal reasoning benchmark, CausalFlip, designed to encourage the development of new LLM paradigm or training algorithms that ground LLM reasoning in causality rather than semantic correlation. CausalFlip consists of causal judgment questions built over event triples that could form different confounder, chain, and collider relations. Based on this, for each event triple, we construct pairs of semantically similar questions that reuse the same events but yield opposite causal answers, where models that rely heavily on semantic matching are systematically driven toward incorrect predictions. To further probe models' reliance on semantic patterns, we introduce a noisy-prefix evaluation that prepends causally irrelevant text before intermediate causal reasoning steps without altering the underlying causal relations or the logic of the reasoning process. We evaluate LLMs under multiple training paradigms, including answer-only training, explicit Chain-of-Thought (CoT) supervision, and a proposed internalized causal reasoning approach that aims to mitigate explicit reliance on correlation in the reasoning process. Our results show that explicit CoT can still be misled by spurious semantic correlations, where internalizing reasoning steps yields substantially improved causal grounding, suggesting that it is promising to better elicit the latent causal reasoning capabilities of base LLMs.
IAPO: Information-Aware Policy Optimization for Token-Efficient Reasoning
Feb 22, 2026Large language models increasingly rely on long chains of thought to improve accuracy, yet such gains come with substantial inference-time costs. We revisit token-efficient post-training and argue that existing sequence-level reward-shaping methods offer limited control over how reasoning effort is allocated across tokens. To bridge the gap, we propose IAPO, an information-theoretic post-training framework that assigns token-wise advantages based on each token's conditional mutual information (MI) with the final answer. This yields an explicit, principled mechanism for identifying informative reasoning steps and suppressing low-utility exploration. We provide a theoretical analysis showing that our IAPO can induce monotonic reductions in reasoning verbosity without harming correctness. Empirically, IAPO consistently improves reasoning accuracy while reducing reasoning length by up to 36%, outperforming existing token-efficient RL methods across various reasoning datasets. Extensive empirical evaluations demonstrate that information-aware advantage shaping is a powerful and general direction for token-efficient post-training. The code is available at https://github.com/YinhanHe123/IAPO.
Saliency-Aware Multi-Route Thinking: Revisiting Vision-Language Reasoning
Feb 18, 2026Vision-language models (VLMs) aim to reason by jointly leveraging visual and textual modalities. While allocating additional inference-time computation has proven effective for large language models (LLMs), achieving similar scaling in VLMs remains challenging. A key obstacle is that visual inputs are typically provided only once at the start of generation, while textual reasoning (e.g., early visual summaries) is generated autoregressively, causing reasoning to become increasingly text-dominated and allowing early visual grounding errors to accumulate. Moreover, vanilla guidance for visual grounding during inference is often coarse and noisy, making it difficult to steer reasoning over long texts. To address these challenges, we propose \emph{Saliency-Aware Principle} (SAP) selection. SAP operates on high-level reasoning principles rather than token-level trajectories, which enable stable control over discrete generation under noisy feedback while allowing later reasoning steps to re-consult visual evidence when renewed grounding is required. In addition, SAP supports multi-route inference, enabling parallel exploration of diverse reasoning behaviors. SAP is model-agnostic and data-free, requiring no additional training. Empirical results show that SAP achieves competitive performance, especially in reducing object hallucination, under comparable token-generation budgets while yielding more stable reasoning and lower response latency than CoT-style long sequential reasoning.
Generalizing GNNs with Tokenized Mixture of Experts
Feb 09, 2026Deployed graph neural networks (GNNs) are frozen at deployment yet must fit clean data, generalize under distribution shifts, and remain stable to perturbations. We show that static inference induces a fundamental tradeoff: improving stability requires reducing reliance on shift-sensitive features, leaving an irreducible worst-case generalization floor. Instance-conditional routing can break this ceiling, but is fragile because shifts can mislead routing and perturbations can make routing fluctuate. We capture these effects via two decompositions separating coverage vs selection, and base sensitivity vs fluctuation amplification. Based on these insights, we propose STEM-GNN, a pretrain-then-finetune framework with a mixture-of-experts encoder for diverse computation paths, a vector-quantized token interface to stabilize encoder-to-head signals, and a Lipschitz-regularized head to bound output amplification. Across nine node, link, and graph benchmarks, STEM-GNN achieves a stronger three-way balance, improving robustness to degree/homophily shifts and to feature/edge corruptions while remaining competitive on clean graphs.
PhysicsAgentABM: Physics-Guided Generative Agent-Based Modeling
Feb 05, 2026Large language model (LLM)-based multi-agent systems enable expressive agent reasoning but are expensive to scale and poorly calibrated for timestep-aligned state-transition simulation, while classical agent-based models (ABMs) offer interpretability but struggle to integrate rich individual-level signals and non-stationary behaviors. We propose PhysicsAgentABM, which shifts inference to behaviorally coherent agent clusters: state-specialized symbolic agents encode mechanistic transition priors, a multimodal neural transition model captures temporal and interaction dynamics, and uncertainty-aware epistemic fusion yields calibrated cluster-level transition distributions. Individual agents then stochastically realize transitions under local constraints, decoupling population inference from entity-level variability. We further introduce ANCHOR, an LLM agent-driven clustering strategy based on cross-contextual behavioral responses and a novel contrastive loss, reducing LLM calls by up to 6-8 times. Experiments across public health, finance, and social sciences show consistent gains in event-time accuracy and calibration over mechanistic, neural, and LLM baselines. By re-architecting generative ABM around population-level inference with uncertainty-aware neuro-symbolic fusion, PhysicsAgentABM establishes a new paradigm for scalable and calibrated simulation with LLMs.
MolEdit: Knowledge Editing for Multimodal Molecule Language Models
Nov 16, 2025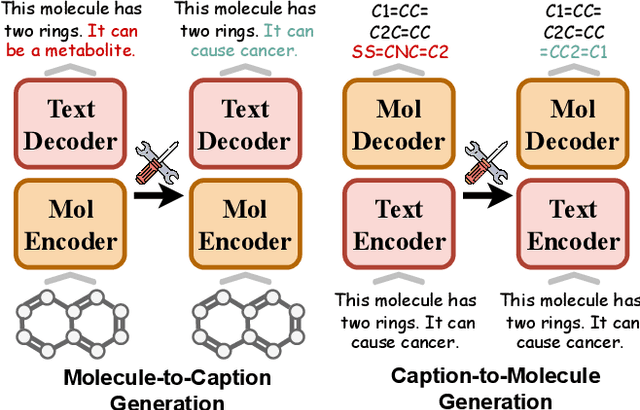
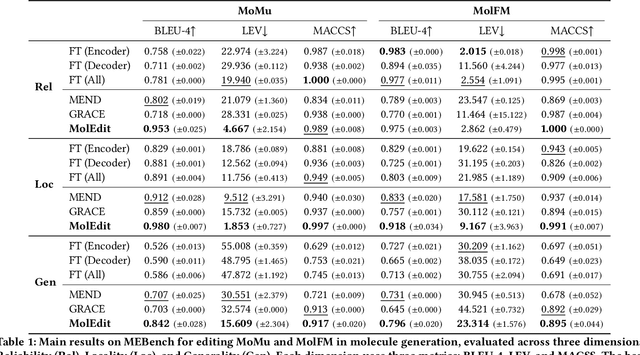

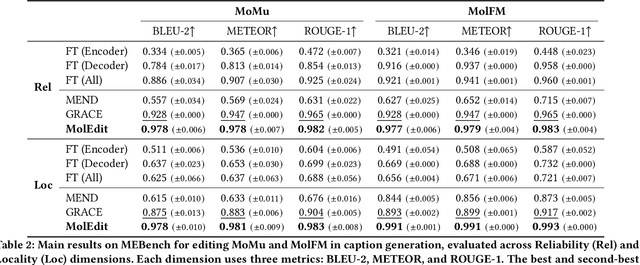
Understanding and continuously refining multimodal molecular knowledge is crucial for advancing biomedicine, chemistry, and materials science. Molecule language models (MoLMs) have become powerful tools in these domains, integrating structural representations (e.g., SMILES strings, molecular graphs) with rich contextual descriptions (e.g., physicochemical properties). However, MoLMs can encode and propagate inaccuracies due to outdated web-mined training corpora or malicious manipulation, jeopardizing downstream discovery pipelines. While knowledge editing has been explored for general-domain AI, its application to MoLMs remains uncharted, presenting unique challenges due to the multifaceted and interdependent nature of molecular knowledge. In this paper, we take the first step toward MoLM editing for two critical tasks: molecule-to-caption generation and caption-to-molecule generation. To address molecule-specific challenges, we propose MolEdit, a powerful framework that enables targeted modifications while preserving unrelated molecular knowledge. MolEdit combines a Multi-Expert Knowledge Adapter that routes edits to specialized experts for different molecular facets with an Expertise-Aware Editing Switcher that activates the adapters only when input closely matches the stored edits across all expertise, minimizing interference with unrelated knowledge. To systematically evaluate editing performance, we introduce MEBench, a comprehensive benchmark assessing multiple dimensions, including Reliability (accuracy of the editing), Locality (preservation of irrelevant knowledge), and Generality (robustness to reformed queries). Across extensive experiments on two popular MoLM backbones, MolEdit delivers up to 18.8% higher Reliability and 12.0% better Locality than baselines while maintaining efficiency. The code is available at: https://github.com/LzyFischer/MolEdit.
GraphTOP: Graph Topology-Oriented Prompting for Graph Neural Networks
Oct 25, 2025Graph Neural Networks (GNNs) have revolutionized the field of graph learning by learning expressive graph representations from massive graph data. As a common pattern to train powerful GNNs, the "pre-training, adaptation" scheme first pre-trains GNNs over unlabeled graph data and subsequently adapts them to specific downstream tasks. In the adaptation phase, graph prompting is an effective strategy that modifies input graph data with learnable prompts while keeping pre-trained GNN models frozen. Typically, existing graph prompting studies mainly focus on *feature-oriented* methods that apply graph prompts to node features or hidden representations. However, these studies often achieve suboptimal performance, as they consistently overlook the potential of *topology-oriented* prompting, which adapts pre-trained GNNs by modifying the graph topology. In this study, we conduct a pioneering investigation of graph prompting in terms of graph topology. We propose the first **Graph** **T**opology-**O**riented **P**rompting (GraphTOP) framework to effectively adapt pre-trained GNN models for downstream tasks. More specifically, we reformulate topology-oriented prompting as an edge rewiring problem within multi-hop local subgraphs and relax it into the continuous probability space through reparameterization while ensuring tight relaxation and preserving graph sparsity. Extensive experiments on five graph datasets under four pre-training strategies demonstrate that our proposed GraphTOP outshines six baselines on multiple node classification datasets. Our code is available at https://github.com/xbfu/GraphTOP.