 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndustryEQA: Pushing the Frontiers of Embodied Question Answering in Industrial Scenarios
May 27, 2025Existing Embodied Question Answering (EQA) benchmarks primarily focus on household environments, often overlooking safety-critical aspects and reasoning processes pertinent to industrial settings. This drawback limits the evaluation of agent readiness for real-world industrial applications. To bridge this, we introduce IndustryEQA, the first benchmark dedicated to evaluating embodied agent capabilities within safety-critical warehouse scenarios. Built upon the NVIDIA Isaac Sim platform, IndustryEQA provides high-fidelity episodic memory videos featuring diverse industrial assets, dynamic human agents, and carefully designed hazardous situations inspired by real-world safety guidelines. The benchmark includes rich annotations covering six categories: equipment safety, human safety, object recognition, attribute recognition, temporal understanding, and spatial understanding. Besides, it also provides extra reasoning evaluation based on these categories. Specifically, it comprises 971 question-answer pairs generated from small warehouse and 373 pairs from large ones, incorporating scenarios with and without human. We further propose a comprehensive evaluation framework, including various baseline models, to assess their general perception and reasoning abilities in industrial environments. IndustryEQA aims to steer EQA research towards developing more robust, safety-aware, and practically applicable embodied agents for complex industrial environments. Benchmark and codes are available.
H-MoRe: Learning Human-centric Motion Representation for Action Analysis
Apr 14, 2025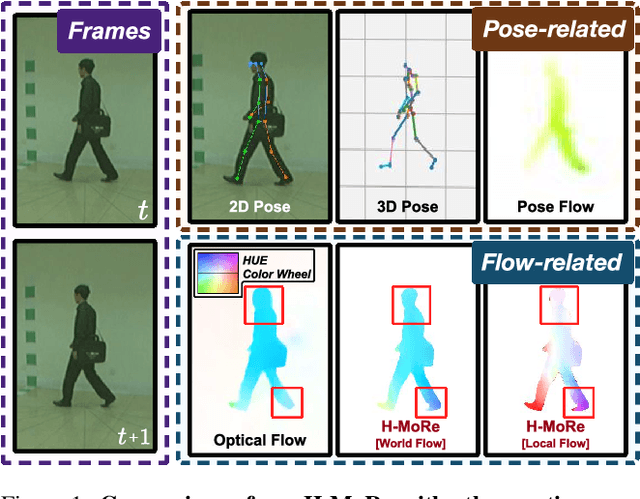
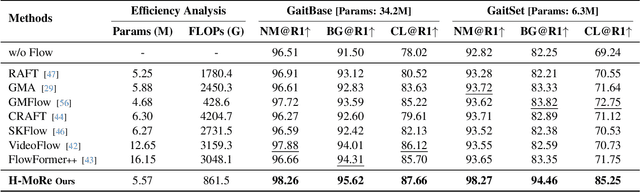
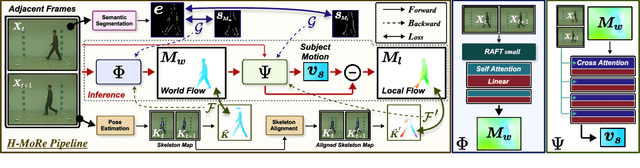
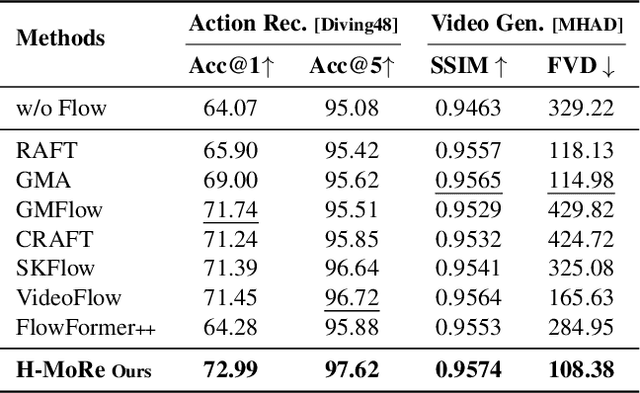
In this paper, we propose H-MoRe, a novel pipeline for learning precise human-centric motion representation. Our approach dynamically preserves relevant human motion while filtering out background movement. Notably, unlike previous methods relying on fully supervised learning from synthetic data, H-MoRe learns directly from real-world scenarios in a self-supervised manner, incorporating both human pose and body shape information. Inspired by kinematics, H-MoRe represents absolute and relative movements of each body point in a matrix format that captures nuanced motion details, termed world-local flows. H-MoRe offers refined insights into human motion, which can be integrated seamlessly into various action-related applications. Experimental results demonstrate that H-MoRe brings substantial improvements across various downstream tasks, including gait recognition(CL@R1: +16.01%), action recognition(Acc@1: +8.92%), and video generation(FVD: -67.07%). Additionally, H-MoRe exhibits high inference efficiency (34 fps), making it suitable for most real-time scenarios. Models and code will be released upon publication.
Are We Merely Justifying Results ex Post Facto? Quantifying Explanatory Inversion in Post-Hoc Model Explanations
Apr 11, 2025Post-hoc explanation methods provide interpretation by attributing predictions to input features. Natural explanations are expected to interpret how the inputs lead to the predictions. Thus, a fundamental question arises: Do these explanations unintentionally reverse the natural relationship between inputs and outputs? Specifically, are the explanations rationalizing predictions from the output rather than reflecting the true decision process? To investigate such explanatory inversion, we propose Inversion Quantification (IQ), a framework that quantifies the degree to which explanations rely on outputs and deviate from faithful input-output relationships. Using the framework, we demonstrate on synthetic datasets that widely used methods such as LIME and SHAP are prone to such inversion, particularly in the presence of spurious correlations, across tabular, image, and text domains. Finally, we propose Reproduce-by-Poking (RBP), a simple and model-agnostic enhancement to post-hoc explanation methods that integrates forward perturbation checks. We further show that under the IQ framework, RBP theoretically guarantees the mitigation of explanatory inversion. Empirically, for example, on the synthesized data, RBP can reduce the inversion by 1.8% on average across iconic post-hoc explanation approaches and domains.
Window Token Concatenation for Efficient Visual Large Language Models
Apr 05, 2025To effectively reduce the visual tokens in Visual Large Language Models (VLLMs), we propose a novel approach called Window Token Concatenation (WiCo). Specifically, we employ a sliding window to concatenate spatially adjacent visual tokens. However, directly concatenating these tokens may group diverse tokens into one, and thus obscure some fine details. To address this challenge, we propose fine-tuning the last few layers of the vision encoder to adaptively adjust the visual tokens, encouraging that those within the same window exhibit similar features. To further enhance the performance on fine-grained visual understanding tasks, we introduce WiCo+, which decomposes the visual tokens in later layers of the LLM. Such a design enjoys the merits of the large perception field of the LLM for fine-grained visual understanding while keeping a small number of visual tokens for efficient inference. We perform extensive experiments on both coarse- and fine-grained visual understanding tasks based on LLaVA-1.5 and Shikra, showing better performance compared with existing token reduction projectors. The code is available: https://github.com/JackYFL/WiCo.
Visual Large Language Models for Generalized and Specialized Applications
Jan 06, 2025



Visual-language models (VLM) have emerged as a powerful tool for learning a unified embedding space for vision and language. Inspired by large language models, which have demonstrated strong reasoning and multi-task capabilities, visual large language models (VLLMs) are gaining increasing attention for building general-purpose VLMs. Despite the significant progress made in VLLMs, the related literature remains limited, particularly from a comprehensive application perspective, encompassing generalized and specialized applications across vision (image, video, depth), action, and language modalities. In this survey, we focus on the diverse applications of VLLMs, examining their using scenarios, identifying ethics consideration and challenges, and discussing future directions for their development. By synthesizing these contents, we aim to provide a comprehensive guide that will pave the way for future innovations and broader applications of VLLMs. The paper list repository is available: https://github.com/JackYFL/awesome-VLLMs.
LiDAR-based End-to-end Temporal Perception for Vehicle-Infrastructure Cooperation
Nov 22, 2024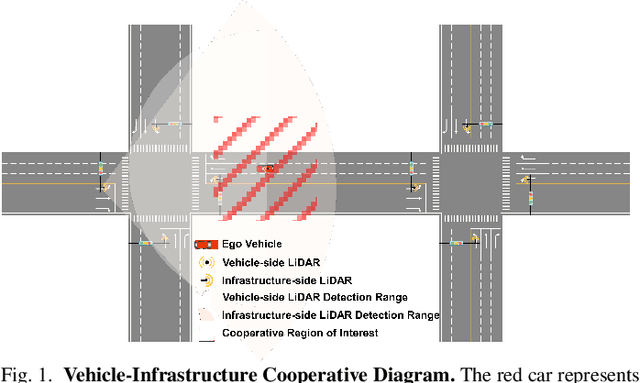
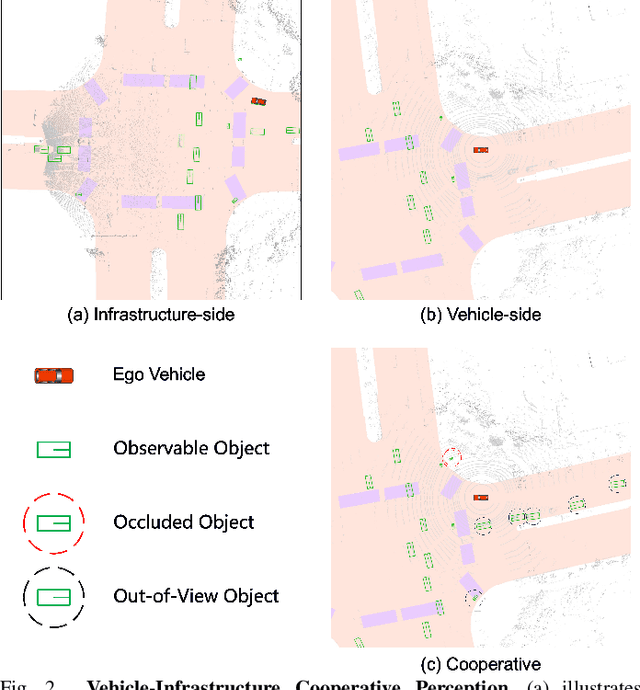
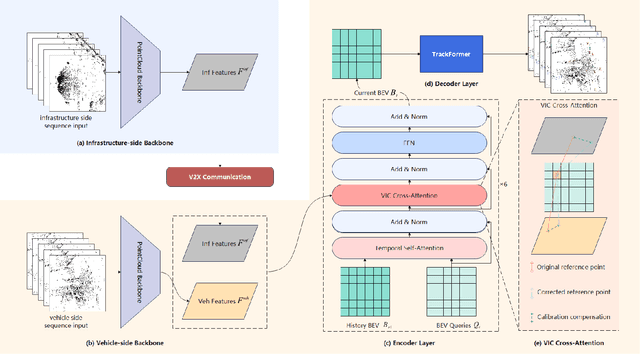
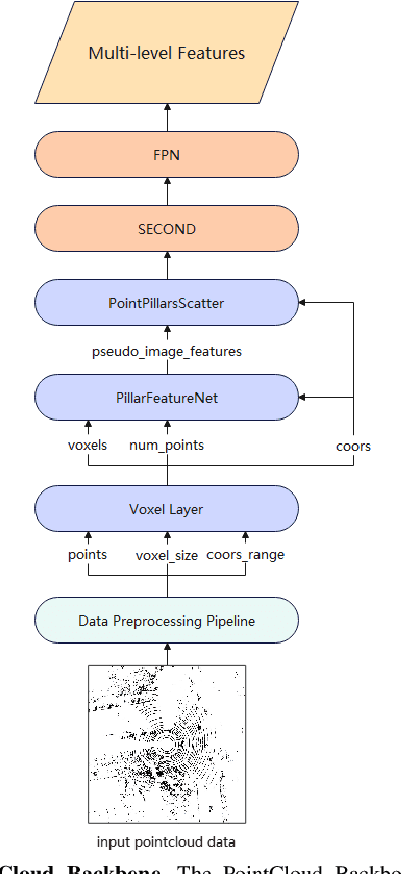
Temporal perception, the ability to detect and track objects over time, is critical in autonomous driving for maintaining a comprehensive understanding of dynamic environments. However, this task is hindered by significant challenges, including incomplete perception caused by occluded objects and observational blind spots, which are common in single-vehicle perception systems. To address these issues, we introduce LET-VIC, a LiDAR-based End-to-End Tracking framework for Vehicle-Infrastructure Cooperation (VIC). LET-VIC leverages Vehicle-to-Everything (V2X) communication to enhance temporal perception by fusing spatial and temporal data from both vehicle and infrastructure sensors. First, it spatially integrates Bird's Eye View (BEV) features from vehicle-side and infrastructure-side LiDAR data, creating a comprehensive view that mitigates occlusions and compensates for blind spots. Second, LET-VIC incorporates temporal context across frames, allowing the model to leverage historical data for enhanced tracking stability and accuracy. To further improve robustness, LET-VIC includes a Calibration Error Compensation (CEC) module to address sensor misalignments and ensure precise feature alignment. Experiments on the V2X-Seq-SPD dataset demonstrate that LET-VIC significantly outperforms baseline models, achieving at least a 13.7% improvement in mAP and a 13.1% improvement in AMOTA without considering communication delays. This work offers a practical solution and a new research direction for advancing temporal perception in autonomous driving through vehicle-infrastructure cooperation.
Exploiting VLM Localizability and Semantics for Open Vocabulary Action Detection
Nov 17, 2024



Action detection aims to detect (recognize and localize) human actions spatially and temporally in videos. Existing approaches focus on the closed-set setting where an action detector is trained and tested on videos from a fixed set of action categories. However, this constrained setting is not viable in an open world where test videos inevitably come beyond the trained action categories. In this paper, we address the practical yet challenging Open-Vocabulary Action Detection (OVAD) problem. It aims to detect any action in test videos while training a model on a fixed set of action categories. To achieve such an open-vocabulary capability, we propose a novel method OpenMixer that exploits the inherent semantics and localizability of large vision-language models (VLM) within the family of query-based detection transformers (DETR). Specifically, the OpenMixer is developed by spatial and temporal OpenMixer blocks (S-OMB and T-OMB), and a dynamically fused alignment (DFA) module. The three components collectively enjoy the merits of strong generalization from pre-trained VLMs and end-to-end learning from DETR design. Moreover, we established OVAD benchmarks under various settings, and the experimental results show that the OpenMixer performs the best over baselines for detecting seen and unseen actions. We release the codes, models, and dataset splits at https://github.com/Cogito2012/OpenMixer.
A Survey of Multimodal Sarcasm Detection
Oct 24, 2024



Sarcasm is a rhetorical device that is used to convey the opposite of the literal meaning of an utterance. Sarcasm is widely used on social media and other forms of computer-mediated communication motivating the use of computational models to identify it automatically. While the clear majority of approaches to sarcasm detection have been carried out on text only, sarcasm detection often requires additional information present in tonality, facial expression, and contextual images. This has led to the introduction of multimodal models, opening the possibility to detect sarcasm in multiple modalities such as audio, images, text, and video. In this paper, we present the first comprehensive survey on multimodal sarcasm detection - henceforth MSD - to date. We survey papers published between 2018 and 2023 on the topic, and discuss the models and datasets used for this task. We also present future research directions in MSD.
Learning to Localize Actions in Instructional Videos with LLM-Based Multi-Pathway Text-Video Alignment
Sep 22, 2024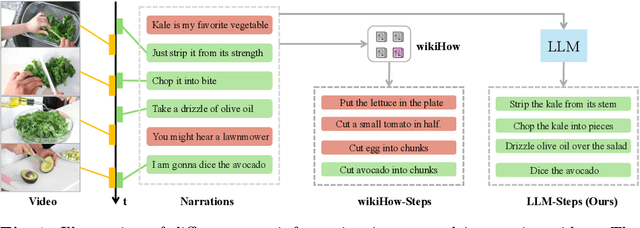



Learning to localize temporal boundaries of procedure steps in instructional videos is challenging due to the limited availability of annotated large-scale training videos. Recent works focus on learning the cross-modal alignment between video segments and ASR-transcripted narration texts through contrastive learning. However, these methods fail to account for the alignment noise, i.e., irrelevant narrations to the instructional task in videos and unreliable timestamps in narrations. To address these challenges, this work proposes a novel training framework. Motivated by the strong capabilities of Large Language Models (LLMs) in procedure understanding and text summarization, we first apply an LLM to filter out task-irrelevant information and summarize task-related procedure steps (LLM-steps) from narrations. To further generate reliable pseudo-matching between the LLM-steps and the video for training, we propose the Multi-Pathway Text-Video Alignment (MPTVA) strategy. The key idea is to measure alignment between LLM-steps and videos via multiple pathways, including: (1) step-narration-video alignment using narration timestamps, (2) direct step-to-video alignment based on their long-term semantic similarity, and (3) direct step-to-video alignment focusing on short-term fine-grained semantic similarity learned from general video domains. The results from different pathways are fused to generate reliable pseudo step-video matching. We conducted extensive experiments across various tasks and problem settings to evaluate our proposed method. Our approach surpasses state-of-the-art methods in three downstream tasks: procedure step grounding, step localization, and narration grounding by 5.9\%, 3.1\%, and 2.8\%.
SHINE: Saliency-aware HIerarchical NEgative Ranking for Compositional Temporal Grounding
Jul 06, 2024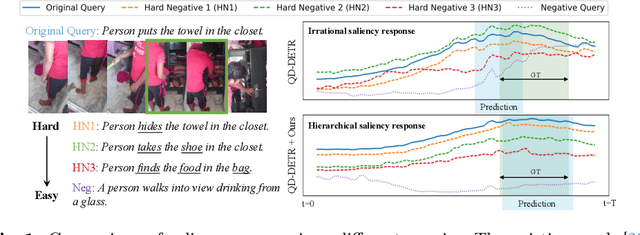
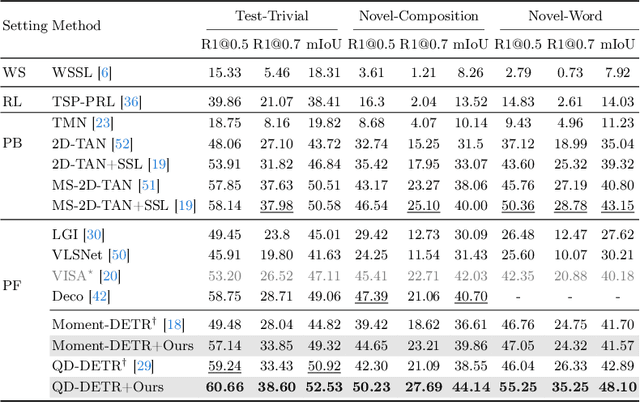
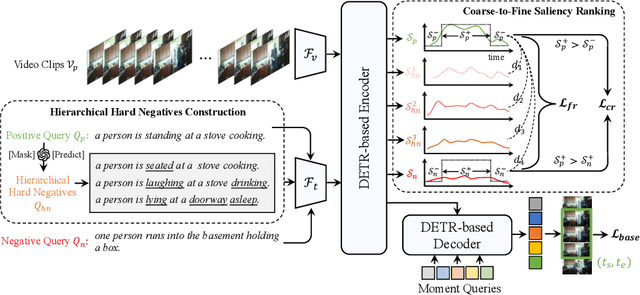
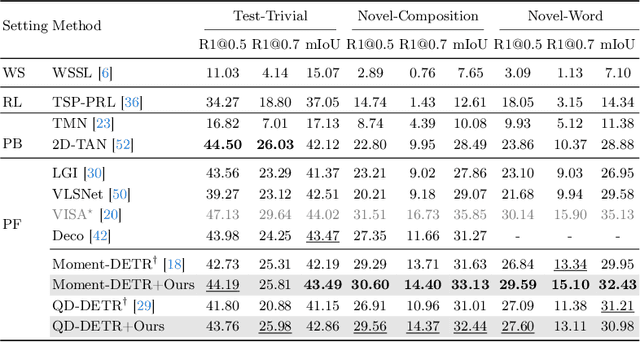
Temporal grounding, a.k.a video moment retrieval, aims at locating video segments corresponding to a given query sentence. The compositional nature of natural language enables the localization beyond predefined events, posing a certain challenge to the compositional generalizability of existing methods. Recent studies establish the correspondence between videos and queries through a decompose-reconstruct manner to achieve compositional generalization. However, they only consider dominant primitives and build negative queries through random sampling and recombination, resulting in semantically implausible negatives that hinder the models from learning rational compositions. In addition, recent DETR-based methods still underperform in compositional temporal grounding, showing irrational saliency responses when given negative queries that have subtle differences from positive queries. To address these limitations, we first propose a large language model-driven method for negative query construction, utilizing GPT-3.5-Turbo to generate semantically plausible hard negative queries. Subsequently, we introduce a coarse-to-fine saliency ranking strategy, which encourages the model to learn the multi-granularity semantic relationships between videos and hierarchical negative queries to boost compositional generalization. Extensive experiments on two challenging benchmarks validate the effectiveness and generalizability of our proposed method. Our code is available at https://github.com/zxccade/SHINE.