 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End 3D Spatiotemporal Perception with Multimodal Fusion and V2X Collaboration
Dec 26, 2025Multi-view cooperative perception and multimodal fusion are essential for reliable 3D spatiotemporal understanding in autonomous driving, especially under occlusions, limited viewpoints, and communication delays in V2X scenarios. This paper proposes XET-V2X, a multi-modal fused end-to-end tracking framework for v2x collaboration that unifies multi-view multimodal sensing within a shared spatiotemporal representation. To efficiently align heterogeneous viewpoints and modalities, XET-V2X introduces a dual-layer spatial cross-attention module based on multi-scale deformable attention. Multi-view image features are first aggregated to enhance semantic consistency, followed by point cloud fusion guided by the updated spatial queries, enabling effective cross-modal interaction while reducing computational overhead. Experiments on the real-world V2X-Seq-SPD dataset and the simulated V2X-Sim-V2V and V2X-Sim-V2I benchmarks demonstrate consistent improvements in detection and tracking performance under varying communication delays. Both quantitative results and qualitative visualizations indicate that XET-V2X achieves robust and temporally stable perception in complex traffic scenarios.
LiDAR-based End-to-end Temporal Perception for Vehicle-Infrastructure Cooperation
Nov 22, 2024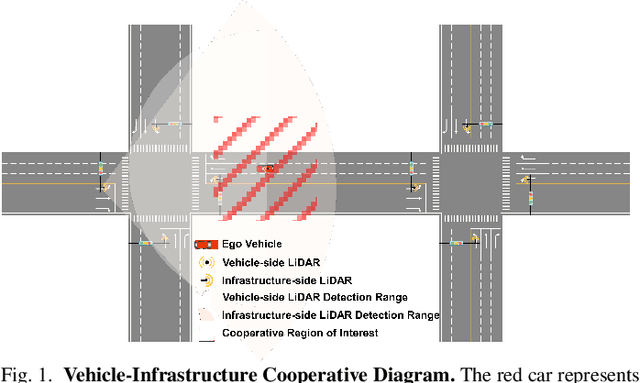
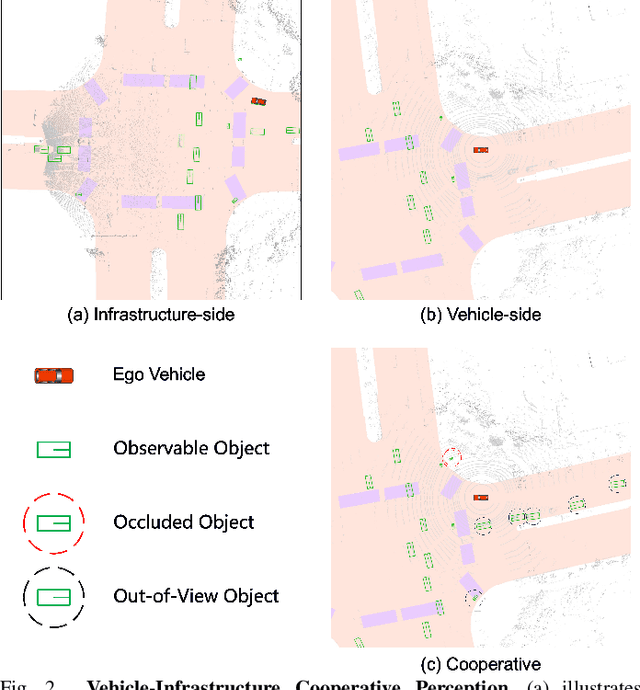
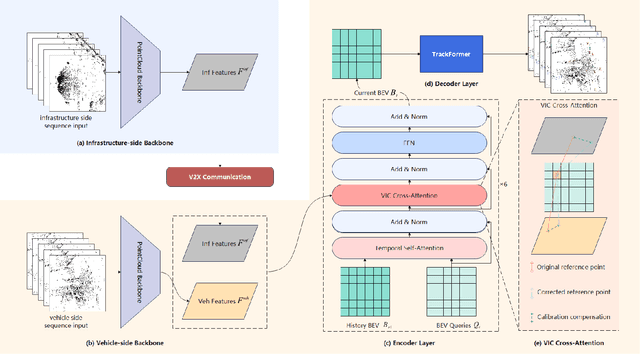
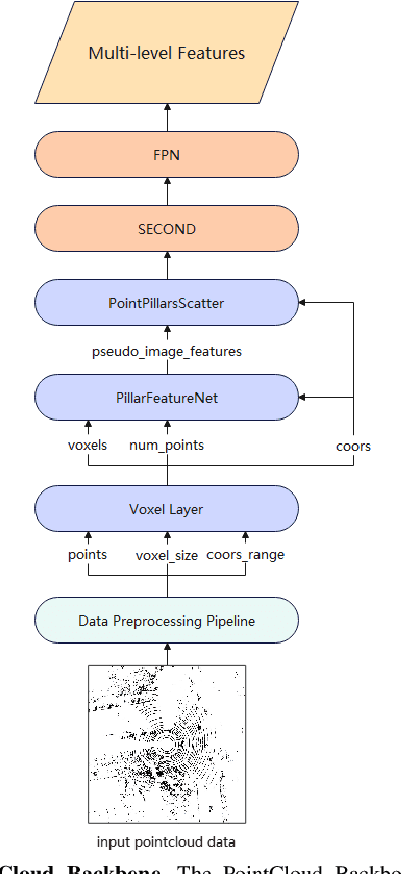
Temporal perception, the ability to detect and track objects over time, is critical in autonomous driving for maintaining a comprehensive understanding of dynamic environments. However, this task is hindered by significant challenges, including incomplete perception caused by occluded objects and observational blind spots, which are common in single-vehicle perception systems. To address these issues, we introduce LET-VIC, a LiDAR-based End-to-End Tracking framework for Vehicle-Infrastructure Cooperation (VIC). LET-VIC leverages Vehicle-to-Everything (V2X) communication to enhance temporal perception by fusing spatial and temporal data from both vehicle and infrastructure sensors. First, it spatially integrates Bird's Eye View (BEV) features from vehicle-side and infrastructure-side LiDAR data, creating a comprehensive view that mitigates occlusions and compensates for blind spots. Second, LET-VIC incorporates temporal context across frames, allowing the model to leverage historical data for enhanced tracking stability and accuracy. To further improve robustness, LET-VIC includes a Calibration Error Compensation (CEC) module to address sensor misalignments and ensure precise feature alignment. Experiments on the V2X-Seq-SPD dataset demonstrate that LET-VIC significantly outperforms baseline models, achieving at least a 13.7% improvement in mAP and a 13.1% improvement in AMOTA without considering communication delays. This work offers a practical solution and a new research direction for advancing temporal perception in autonomous driving through vehicle-infrastructure cooperation.