 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbodiedVSR: Dynamic Scene Graph-Guided Chain-of-Thought Reasoning for Visual Spatial Tasks
Mar 14, 2025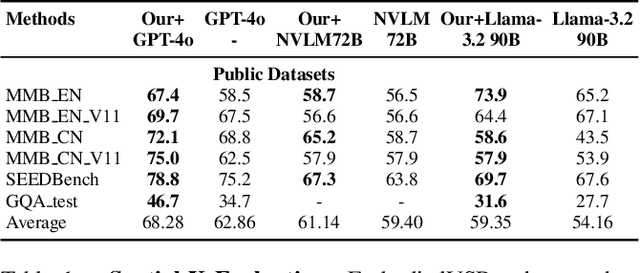
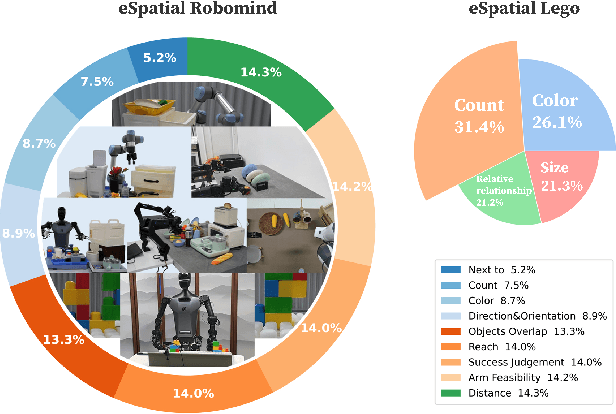
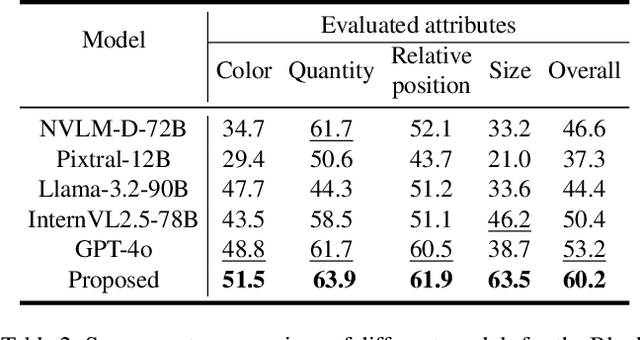
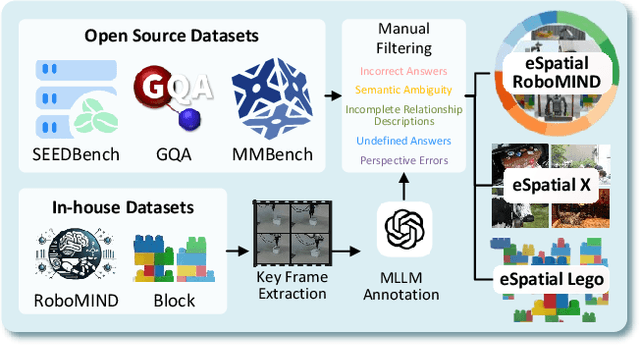
While multimodal large language models (MLLMs) have made groundbreaking progress in embodied intelligence, they still face significant challenges in spatial reasoning for complex long-horizon tasks. To address this gap, we propose EmbodiedVSR (Embodied Visual Spatial Reasoning), a novel framework that integrates dynamic scene graph-guided Chain-of-Thought (CoT) reasoning to enhance spatial understanding for embodied agents. By explicitly constructing structured knowledge representations through dynamic scene graphs, our method enables zero-shot spatial reasoning without task-specific fine-tuning. This approach not only disentangles intricate spatial relationships but also aligns reasoning steps with actionable environmental dynamics. To rigorously evaluate performance, we introduce the eSpatial-Benchmark, a comprehensive dataset including real-world embodied scenarios with fine-grained spatial annotations and adaptive task difficulty levels. Experiments demonstrate that our framework significantly outperforms existing MLLM-based methods in accuracy and reasoning coherence, particularly in long-horizon tasks requiring iterative environment interaction. The results reveal the untapped potential of MLLMs for embodied intelligence when equipped with structured, explainable reasoning mechanisms, paving the way for more reliable deployment in real-world spatial applications. The codes and datasets will be released soon.
RoboMIND: Benchmark on Multi-embodiment Intelligence Normative Data for Robot Manipulation
Dec 18, 2024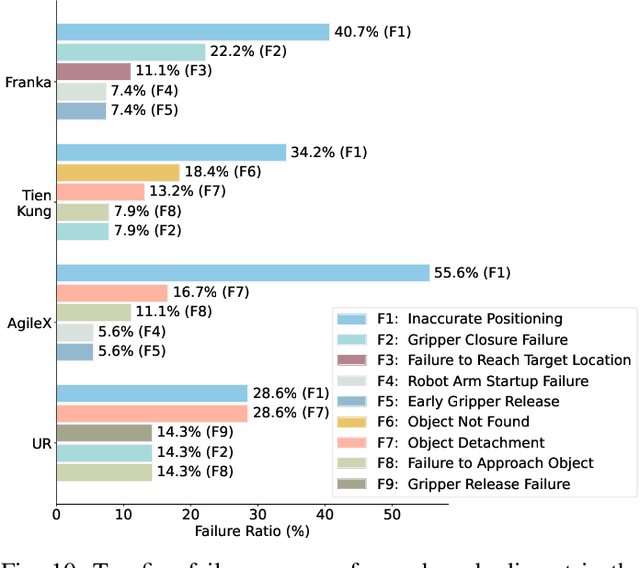
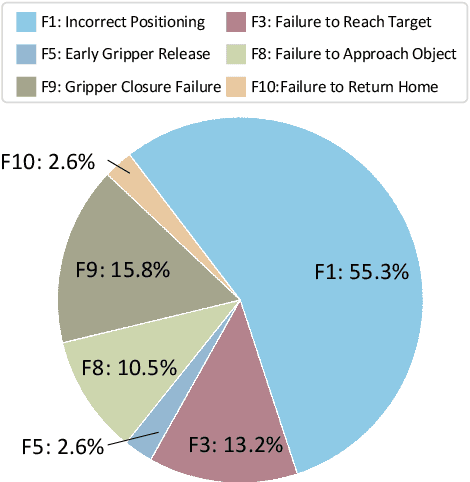
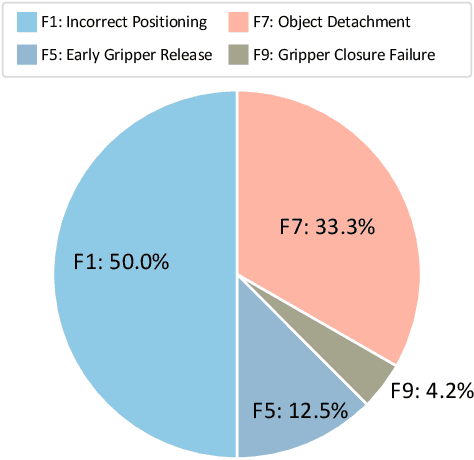
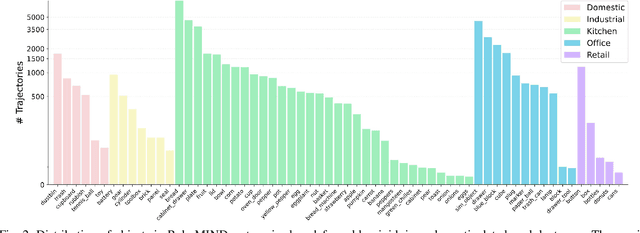
Developing robust and general-purpose robotic manipulation policies is a key goal in the field of robotics. To achieve effective generalization, it is essential to construct comprehensive datasets that encompass a large number of demonstration trajectories and diverse tasks. Unlike vision or language data that can be collected from the Internet, robotic datasets require detailed observations and manipulation actions, necessitating significant investment in hardware-software infrastructure and human labor. While existing works have focused on assembling various individual robot datasets, there remains a lack of a unified data collection standard and insufficient diversity in tasks, scenarios, and robot types. In this paper, we introduce RoboMIND (Multi-embodiment Intelligence Normative Data for Robot manipulation), featuring 55k real-world demonstration trajectories across 279 diverse tasks involving 61 different object classes. RoboMIND is collected through human teleoperation and encompasses comprehensive robotic-related information, including multi-view RGB-D images, proprioceptive robot state information, end effector details, and linguistic task descriptions. To ensure dataset consistency and reliability during policy learning, RoboMIND is built on a unified data collection platform and standardized protocol, covering four distinct robotic embodiments. We provide a thorough quantitative and qualitative analysis of RoboMIND across multiple dimensions, offering detailed insights into the diversity of our datasets. In our experiments, we conduct extensive real-world testing with four state-of-the-art imitation learning methods, demonstrating that training with RoboMIND data results in a high manipulation success rate and strong generalization. Our project is at https://x-humanoid-robomind.github.io/.
LiDAR-based End-to-end Temporal Perception for Vehicle-Infrastructure Cooperation
Nov 22, 2024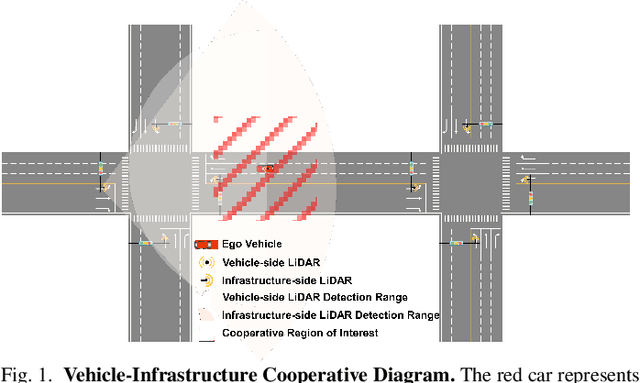
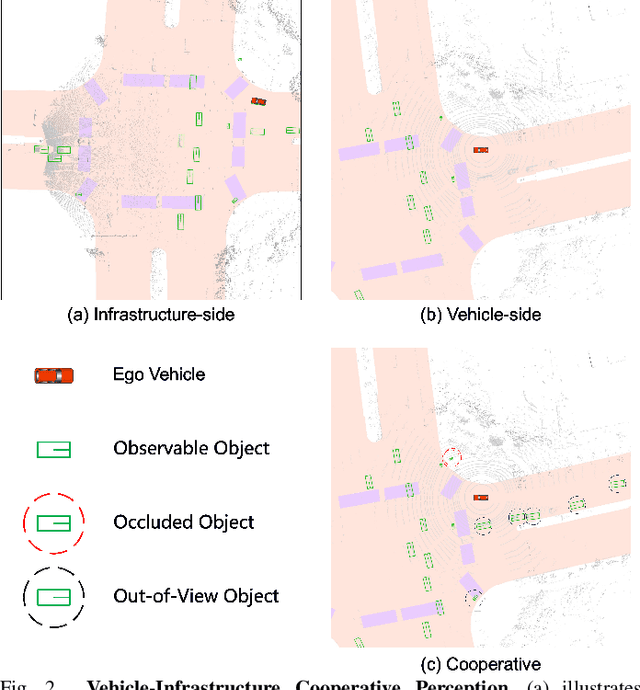
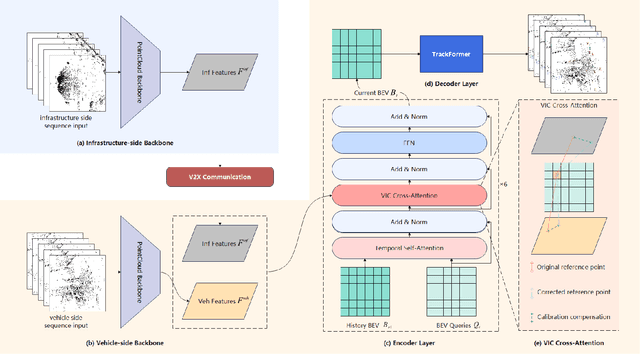
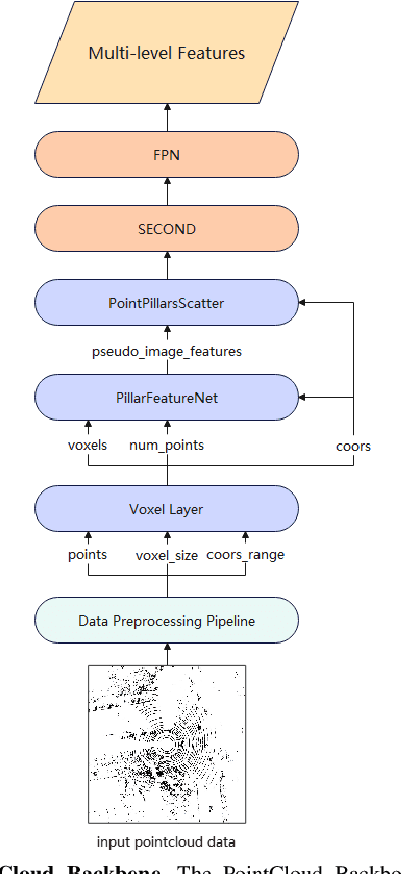
Temporal perception, the ability to detect and track objects over time, is critical in autonomous driving for maintaining a comprehensive understanding of dynamic environments. However, this task is hindered by significant challenges, including incomplete perception caused by occluded objects and observational blind spots, which are common in single-vehicle perception systems. To address these issues, we introduce LET-VIC, a LiDAR-based End-to-End Tracking framework for Vehicle-Infrastructure Cooperation (VIC). LET-VIC leverages Vehicle-to-Everything (V2X) communication to enhance temporal perception by fusing spatial and temporal data from both vehicle and infrastructure sensors. First, it spatially integrates Bird's Eye View (BEV) features from vehicle-side and infrastructure-side LiDAR data, creating a comprehensive view that mitigates occlusions and compensates for blind spots. Second, LET-VIC incorporates temporal context across frames, allowing the model to leverage historical data for enhanced tracking stability and accuracy. To further improve robustness, LET-VIC includes a Calibration Error Compensation (CEC) module to address sensor misalignments and ensure precise feature alignment. Experiments on the V2X-Seq-SPD dataset demonstrate that LET-VIC significantly outperforms baseline models, achieving at least a 13.7% improvement in mAP and a 13.1% improvement in AMOTA without considering communication delays. This work offers a practical solution and a new research direction for advancing temporal perception in autonomous driving through vehicle-infrastructure cooperation.
Flow-Based Feature Fusion for Vehicle-Infrastructure Cooperative 3D Object Detection
Nov 03, 2023



Cooperatively utilizing both ego-vehicle and infrastructure sensor data can significantly enhance autonomous driving perception abilities. However, the uncertain temporal asynchrony and limited communication conditions can lead to fusion misalignment and constrain the exploitation of infrastructure data. To address these issues in vehicle-infrastructure cooperative 3D (VIC3D) object detection, we propose the Feature Flow Net (FFNet), a novel cooperative detection framework. FFNet is a flow-based feature fusion framework that uses a feature flow prediction module to predict future features and compensate for asynchrony. Instead of transmitting feature maps extracted from still-images, FFNet transmits feature flow, leveraging the temporal coherence of sequential infrastructure frames. Furthermore, we introduce a self-supervised training approach that enables FFNet to generate feature flow with feature prediction ability from raw infrastructure sequences. Experimental results demonstrate that our proposed method outperforms existing cooperative detection methods while only requiring about 1/100 of the transmission cost of raw data and covers all latency in one model on the DAIR-V2X dataset. The code is available at \href{https://github.com/haibao-yu/FFNet-VIC3D}{https://github.com/haibao-yu/FFNet-VIC3D}.
Vehicle-Infrastructure Cooperative 3D Object Detection via Feature Flow Prediction
Mar 19, 2023



Cooperatively utilizing both ego-vehicle and infrastructure sensor data can significantly enhance autonomous driving perception abilities. However, temporal asynchrony and limited wireless communication in traffic environments can lead to fusion misalignment and impact detection performance. This paper proposes Feature Flow Net (FFNet), a novel cooperative detection framework that uses a feature flow prediction module to address these issues in vehicle-infrastructure cooperative 3D object detection. Rather than transmitting feature maps extracted from still-images, FFNet transmits feature flow, which leverages the temporal coherence of sequential infrastructure frames to predict future features and compensate for asynchrony. Additionally, we introduce a self-supervised approach to enable FFNet to generate feature flow with feature prediction ability. Experimental results demonstrate that our proposed method outperforms existing cooperative detection methods while requiring no more than 1/10 transmission cost of raw data on the DAIR-V2X dataset when temporal asynchrony exceeds 200$ms$. The code is available at \href{https://github.com/haibao-yu/FFNet-VIC3D}{https://github.com/haibao-yu/FFNet-VIC3D}.