 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End 3D Spatiotemporal Perception with Multimodal Fusion and V2X Collaboration
Dec 26, 2025Multi-view cooperative perception and multimodal fusion are essential for reliable 3D spatiotemporal understanding in autonomous driving, especially under occlusions, limited viewpoints, and communication delays in V2X scenarios. This paper proposes XET-V2X, a multi-modal fused end-to-end tracking framework for v2x collaboration that unifies multi-view multimodal sensing within a shared spatiotemporal representation. To efficiently align heterogeneous viewpoints and modalities, XET-V2X introduces a dual-layer spatial cross-attention module based on multi-scale deformable attention. Multi-view image features are first aggregated to enhance semantic consistency, followed by point cloud fusion guided by the updated spatial queries, enabling effective cross-modal interaction while reducing computational overhead. Experiments on the real-world V2X-Seq-SPD dataset and the simulated V2X-Sim-V2V and V2X-Sim-V2I benchmarks demonstrate consistent improvements in detection and tracking performance under varying communication delays. Both quantitative results and qualitative visualizations indicate that XET-V2X achieves robust and temporally stable perception in complex traffic scenarios.
LiDAR-based End-to-end Temporal Perception for Vehicle-Infrastructure Cooperation
Nov 22, 2024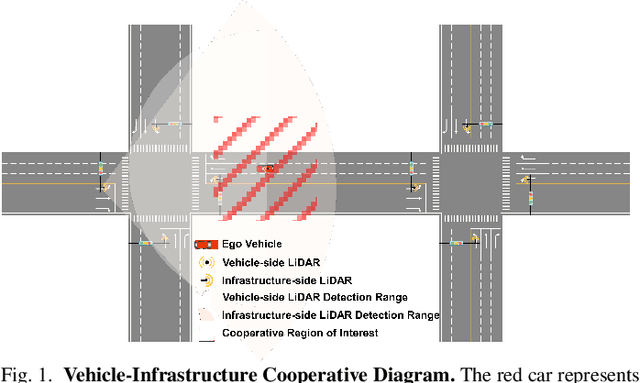
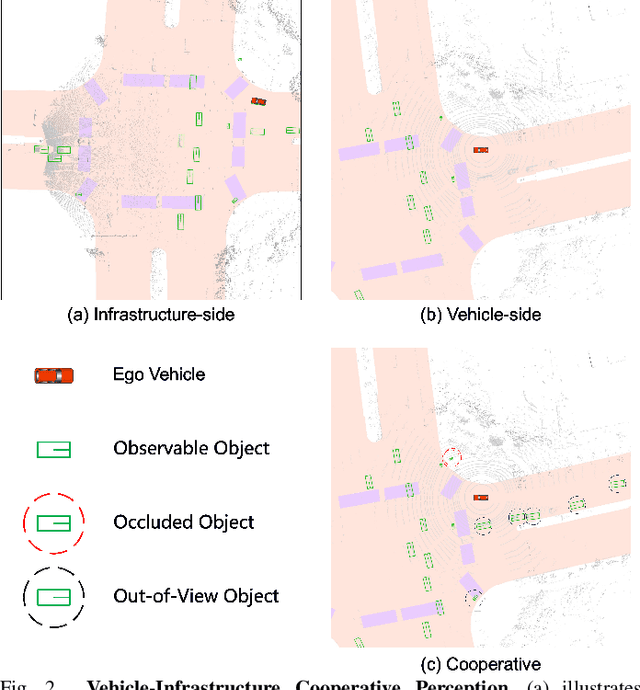
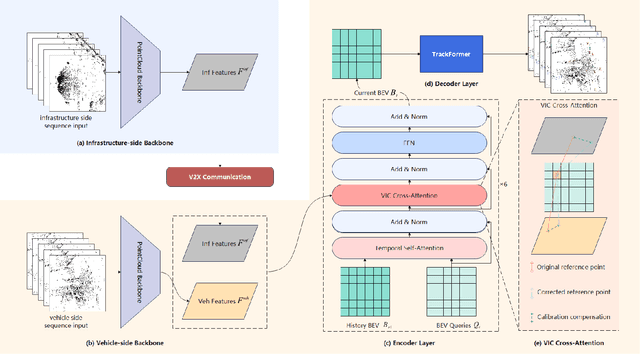
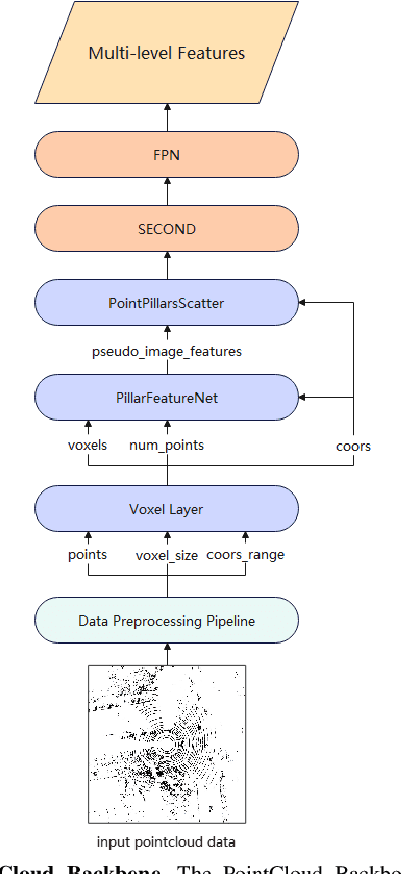
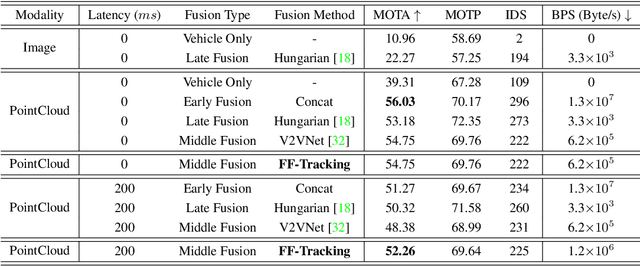
Temporal perception, the ability to detect and track objects over time, is critical in autonomous driving for maintaining a comprehensive understanding of dynamic environments. However, this task is hindered by significant challenges, including incomplete perception caused by occluded objects and observational blind spots, which are common in single-vehicle perception systems. To address these issues, we introduce LET-VIC, a LiDAR-based End-to-End Tracking framework for Vehicle-Infrastructure Cooperation (VIC). LET-VIC leverages Vehicle-to-Everything (V2X) communication to enhance temporal perception by fusing spatial and temporal data from both vehicle and infrastructure sensors. First, it spatially integrates Bird's Eye View (BEV) features from vehicle-side and infrastructure-side LiDAR data, creating a comprehensive view that mitigates occlusions and compensates for blind spots. Second, LET-VIC incorporates temporal context across frames, allowing the model to leverage historical data for enhanced tracking stability and accuracy. To further improve robustness, LET-VIC includes a Calibration Error Compensation (CEC) module to address sensor misalignments and ensure precise feature alignment. Experiments on the V2X-Seq-SPD dataset demonstrate that LET-VIC significantly outperforms baseline models, achieving at least a 13.7% improvement in mAP and a 13.1% improvement in AMOTA without considering communication delays. This work offers a practical solution and a new research direction for advancing temporal perception in autonomous driving through vehicle-infrastructure cooperation.
End-to-End Autonomous Driving through V2X Cooperation
Mar 31, 2024



Cooperatively utilizing both ego-vehicle and infrastructure sensor data via V2X communication has emerged as a promising approach for advanced autonomous driving. However, current research mainly focuses on improving individual modules, rather than taking end-to-end learning to optimize final planning performance, resulting in underutilized data potential. In this paper, we introduce UniV2X, a pioneering cooperative autonomous driving framework that seamlessly integrates all key driving modules across diverse views into a unified network. We propose a sparse-dense hybrid data transmission and fusion mechanism for effective vehicle-infrastructure cooperation, offering three advantages: 1) Effective for simultaneously enhancing agent perception, online mapping, and occupancy prediction, ultimately improving planning performance. 2) Transmission-friendly for practical and limited communication conditions. 3) Reliable data fusion with interpretability of this hybrid data. We implement UniV2X, as well as reproducing several benchmark methods, on the challenging DAIR-V2X, the real-world cooperative driving dataset. Experimental results demonstrate the effectiveness of UniV2X in significantly enhancing planning performance, as well as all intermediate output performance. Code is at https://github.com/AIR-THU/UniV2X.
V2X-Seq: A Large-Scale Sequential Dataset for Vehicle-Infrastructure Cooperative Perception and Forecasting
May 10, 2023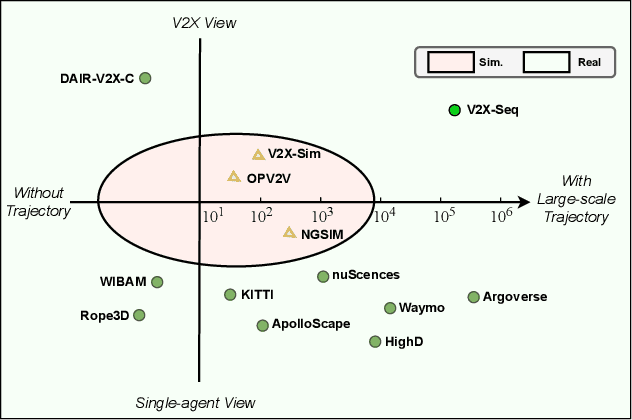
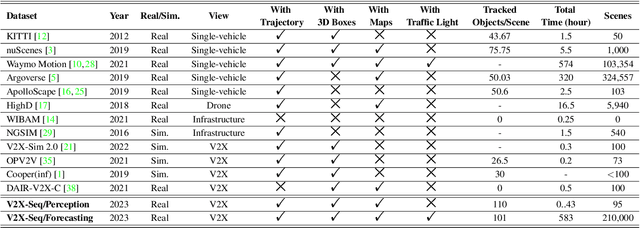
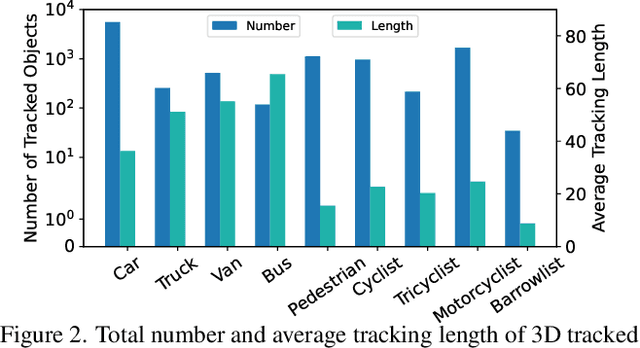
Utilizing infrastructure and vehicle-side information to track and forecast the behaviors of surrounding traffic participants can significantly improve decision-making and safety in autonomous driving. However, the lack of real-world sequential datasets limits research in this area. To address this issue, we introduce V2X-Seq, the first large-scale sequential V2X dataset, which includes data frames, trajectories, vector maps, and traffic lights captured from natural scenery. V2X-Seq comprises two parts: the sequential perception dataset, which includes more than 15,000 frames captured from 95 scenarios, and the trajectory forecasting dataset, which contains about 80,000 infrastructure-view scenarios, 80,000 vehicle-view scenarios, and 50,000 cooperative-view scenarios captured from 28 intersections' areas, covering 672 hours of data. Based on V2X-Seq, we introduce three new tasks for vehicle-infrastructure cooperative (VIC) autonomous driving: VIC3D Tracking, Online-VIC Forecasting, and Offline-VIC Forecasting. We also provide benchmarks for the introduced tasks. Find data, code, and more up-to-date information at \href{https://github.com/AIR-THU/DAIR-V2X-Seq}{https://github.com/AIR-THU/DAIR-V2X-Seq}.
Neural Networks for Latent Budget Analysis of Compositional Data
Sep 10, 2021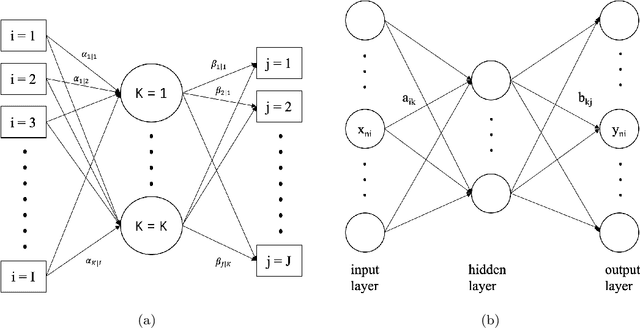
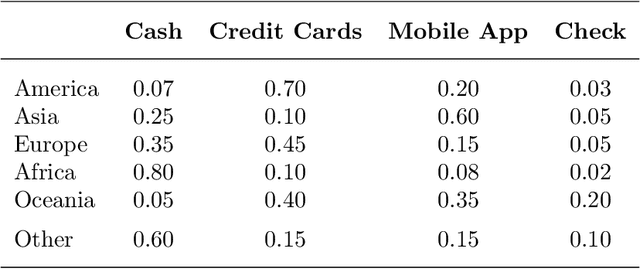
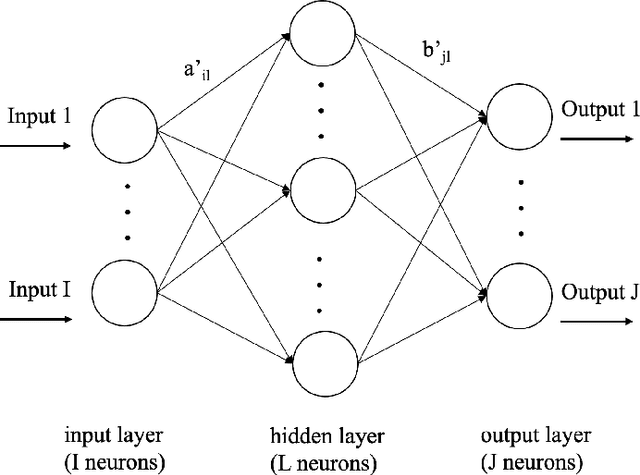
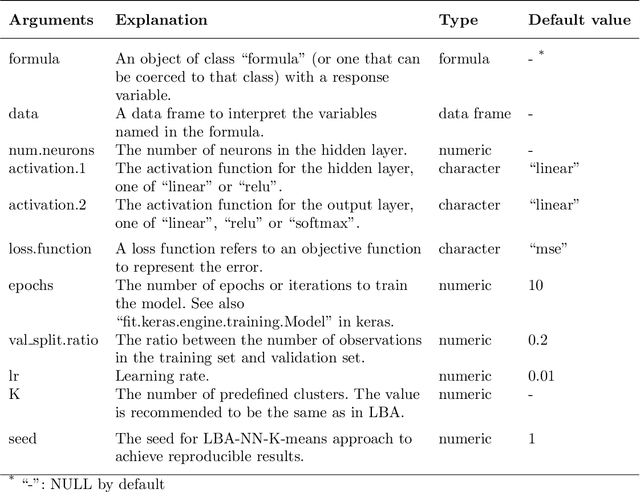
Compositional data are non-negative data collected in a rectangular matrix with a constant row sum. Due to the non-negativity the focus is on conditional proportions that add up to 1 for each row. A row of conditional proportions is called an observed budget. Latent budget analysis (LBA) assumes a mixture of latent budgets that explains the observed budgets. LBA is usually fitted to a contingency table, where the rows are levels of one or more explanatory variables and the columns the levels of a response variable. In prospective studies, there is only knowledge about the explanatory variables of individuals and interest goes out to predicting the response variable. Thus, a form of LBA is needed that has the functionality of prediction. Previous studies proposed a constrained neural network (NN) extension of LBA that was hampered by an unsatisfying prediction ability. Here we propose LBA-NN, a feed forward NN model that yields a similar interpretation to LBA but equips LBA with a better ability of prediction. A stable and plausible interpretation of LBA-NN is obtained through the use of importance plots and table, that show the relative importance of all explanatory variables on the response variable. An LBA-NN-K- means approach that applies K-means clustering on the importance table is used to produce K clusters that are comparable to K latent budgets in LBA. Here we provide different experiments where LBA-NN is implemented and compared with LBA. In our analysis, LBA-NN outperforms LBA in prediction in terms of accuracy, specificity, recall and mean square error. We provide open-source software at GitHub.