 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforced Reasoning for End-to-End Retrosynthetic Planning
Mar 31, 2026Retrosynthetic planning is a fundamental task in organic chemistry, yet remains challenging due to its combinatorial complexity. To address this, conventional approaches typically rely on hybrid frameworks that combine single-step predictions with external search heuristics, inevitably fracturing the logical coherence between local molecular transformations and global planning objectives. To bridge this gap and embed sophisticated strategic foresight directly into the model's chemical reasoning, we introduce ReTriP, an end-to-end generative framework that reformulates retrosynthesis as a direct Chain-of-Thought reasoning task. We establish a path-coherent molecular representation and employ a progressive training curriculum that transitions from reasoning distillation to reinforcement learning with verifiable rewards, effectively aligning stepwise generation with practical route utility. Empirical evaluation on RetroBench demonstrates that ReTriP achieves state-of-the-art performance, exhibiting superior robustness in long-horizon planning compared to hybrid baselines.
CoThink: Token-Efficient Reasoning via Instruct Models Guiding Reasoning Models
May 28, 2025Large language models (LLMs) benefit from increased test-time compute, a phenomenon known as test-time scaling. However, reasoning-optimized models often overthink even simple problems, producing excessively verbose outputs and leading to low token efficiency. By comparing these models with equally sized instruct models, we identify two key causes of this verbosity: (1) reinforcement learning reduces the information density of forward reasoning, and (2) backward chain-of thought training encourages redundant and often unnecessary verification steps. Since LLMs cannot assess the difficulty of a given problem, they tend to apply the same cautious reasoning strategy across all tasks, resulting in inefficient overthinking. To address this, we propose CoThink, an embarrassingly simple pipeline: an instruct model first drafts a high-level solution outline; a reasoning model then works out the solution. We observe that CoThink enables dynamic adjustment of reasoning depth based on input difficulty. Evaluated with three reasoning models DAPO, DeepSeek-R1, and QwQ on three datasets GSM8K, MATH500, and AIME24, CoThink reduces total token generation by 22.3% while maintaining pass@1 accuracy within a 0.42% margin on average. With reference to the instruct model, we formally define reasoning efficiency and observe a potential reasoning efficiency scaling law in LLMs.
Evaluating LLM Adaptation to Sociodemographic Factors: User Profile vs. Dialogue History
May 27, 2025
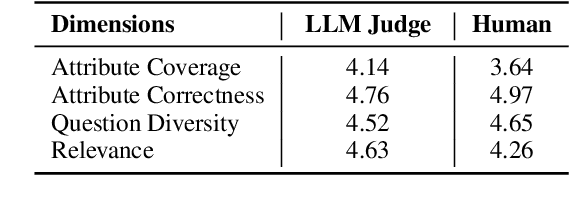

Effective engagement by large language models (LLMs) requires adapting responses to users' sociodemographic characteristics, such as age, occupation, and education level. While many real-world applications leverage dialogue history for contextualization, existing evaluations of LLMs' behavioral adaptation often focus on single-turn prompts. In this paper, we propose a framework to evaluate LLM adaptation when attributes are introduced either (1) explicitly via user profiles in the prompt or (2) implicitly through multi-turn dialogue history. We assess the consistency of model behavior across these modalities. Using a multi-agent pipeline, we construct a synthetic dataset pairing dialogue histories with distinct user profiles and employ questions from the Value Survey Module (VSM 2013) (Hofstede and Hofstede, 2016) to probe value expression. Our findings indicate that most models adjust their expressed values in response to demographic changes, particularly in age and education level, but consistency varies. Models with stronger reasoning capabilities demonstrate greater alignment, indicating the importance of reasoning in robust sociodemographic adaptation.
Exploiting Contextual Knowledge in LLMs through V-usable Information based Layer Enhancement
Apr 22, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities in various tasks, yet they often struggle with context-faithfulness generations that properly reflect contextual knowledge. While existing approaches focus on enhancing the decoding strategies, they ignore the fundamental mechanism of how contextual information is processed within LLMs' internal states. As a result, LLMs remain limited in their ability to fully leverage contextual knowledge. In this paper, we propose Context-aware Layer Enhancement (CaLE), a novel intervention method that enhances the utilization of contextual knowledge within LLMs' internal representations. By employing V-usable information analysis, CaLE strategically amplifies the growth of contextual information at an optimal layer, thereby enriching representations in the final layer. Our experiments demonstrate that CaLE effectively improves context-faithful generation in Question-Answering tasks, particularly in scenarios involving unknown or conflicting contextual knowledge.
If an LLM Were a Character, Would It Know Its Own Story? Evaluating Lifelong Learning in LLMs
Mar 30, 2025Large language models (LLMs) can carry out human-like dialogue, but unlike humans, they are stateless due to the superposition property. However, during multi-turn, multi-agent interactions, LLMs begin to exhibit consistent, character-like behaviors, hinting at a form of emergent lifelong learning. Despite this, existing benchmarks often fail to capture these dynamics, primarily focusing on static, open-ended evaluations. To address this gap, we introduce LIFESTATE-BENCH, a benchmark designed to assess lifelong learning in LLMs. It features two episodic datasets: Hamlet and a synthetic script collection, rich in narrative structure and character interactions. Our fact checking evaluation probes models' self-awareness, episodic memory retrieval, and relationship tracking, across both parametric and non-parametric approaches. Experiments on models like Llama3.1-8B, GPT-4-turbo, and DeepSeek R1, we demonstrate that nonparametric methods significantly outperform parametric ones in managing stateful learning. However, all models exhibit challenges with catastrophic forgetting as interactions extend, highlighting the need for further advancements in lifelong learning.
Position-Aware Depth Decay Decoding ($D^3$): Boosting Large Language Model Inference Efficiency
Mar 11, 2025



Due to the large number of parameters, the inference phase of Large Language Models (LLMs) is resource-intensive. Unlike traditional model compression, which needs retraining, recent dynamic computation methods show that not all components are required for inference, enabling a training-free pipeline. In this paper, we focus on the dynamic depth of LLM generation. A token-position aware layer skipping framework is proposed to save 1.5x times operations efficiently while maintaining performance. We first observed that tokens predicted later have lower perplexity and thus require less computation. Then, we propose a training-free algorithm called Position-Aware Depth Decay Decoding ($D^3$), which leverages a power-law decay function, $\left\lfloor L \times (\alpha^i) \right\rfloor$, to determine the number of layers to retain when generating token $T_i$. Remarkably, without any retraining, the $D^3$ achieves success across a wide range of generation tasks for the first time. Experiments on large language models (\ie the Llama) with $7 \sim 70$ billion parameters show that $D^3$ can achieve an average 1.5x speedup compared with the full-inference pipeline while maintaining comparable performance with nearly no performance drop ($<1\%$) on the GSM8K and BBH benchmarks.
USPilot: An Embodied Robotic Assistant Ultrasound System with Large Language Model Enhanced Graph Planner
Feb 18, 2025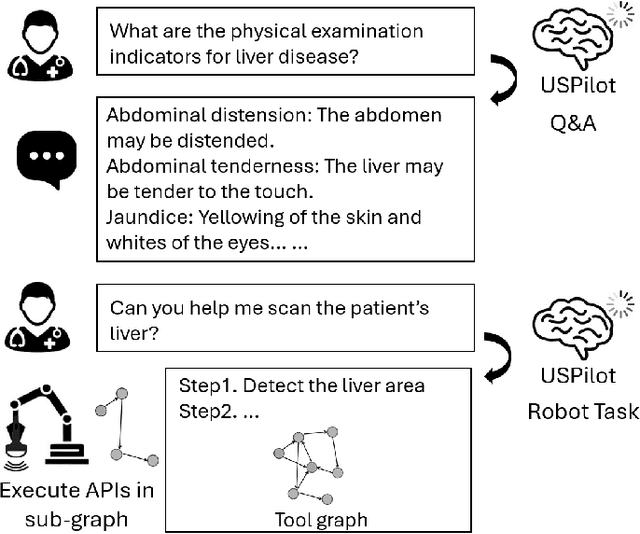
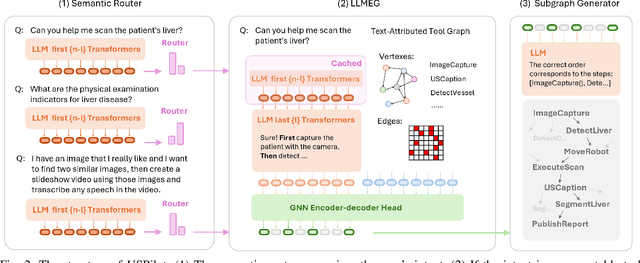

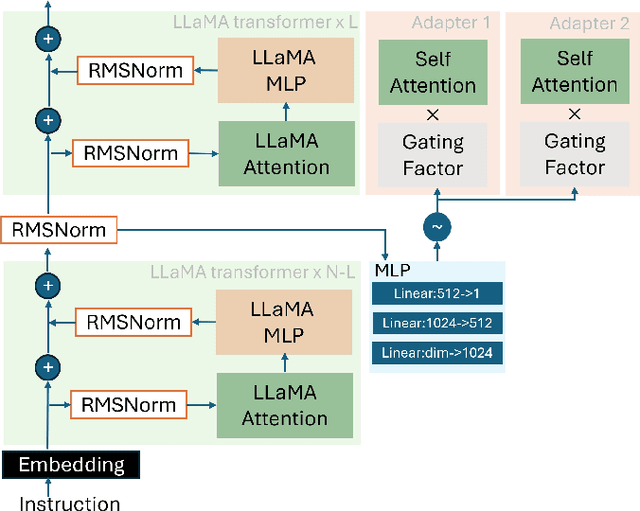
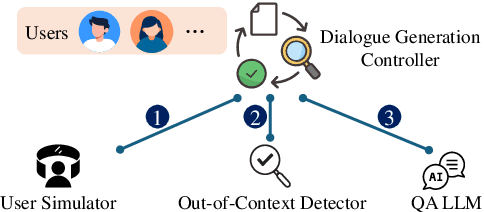
In the era of Large Language Models (LLMs), embodied artificial intelligence presents transformative opportunities for robotic manipulation tasks. Ultrasound imaging, a widely used and cost-effective medical diagnostic procedure, faces challenges due to the global shortage of professional sonographers. To address this issue, we propose USPilot, an embodied robotic assistant ultrasound system powered by an LLM-based framework to enable autonomous ultrasound acquisition. USPilot is designed to function as a virtual sonographer, capable of responding to patients' ultrasound-related queries and performing ultrasound scans based on user intent. By fine-tuning the LLM, USPilot demonstrates a deep understanding of ultrasound-specific questions and tasks. Furthermore, USPilot incorporates an LLM-enhanced Graph Neural Network (GNN) to manage ultrasound robotic APIs and serve as a task planner. Experimental results show that the LLM-enhanced GNN achieves unprecedented accuracy in task planning on public datasets. Additionally, the system demonstrates significant potential in autonomously understanding and executing ultrasound procedures. These advancements bring us closer to achieving autonomous and potentially unmanned robotic ultrasound systems, addressing critical resource gaps in medical imaging.
IROAM: Improving Roadside Monocular 3D Object Detection Learning from Autonomous Vehicle Data Domain
Jan 30, 2025



In autonomous driving, The perception capabilities of the ego-vehicle can be improved with roadside sensors, which can provide a holistic view of the environment. However, existing monocular detection methods designed for vehicle cameras are not suitable for roadside cameras due to viewpoint domain gaps. To bridge this gap and Improve ROAdside Monocular 3D object detection, we propose IROAM, a semantic-geometry decoupled contrastive learning framework, which takes vehicle-side and roadside data as input simultaneously. IROAM has two significant modules. In-Domain Query Interaction module utilizes a transformer to learn content and depth information for each domain and outputs object queries. Cross-Domain Query Enhancement To learn better feature representations from two domains, Cross-Domain Query Enhancement decouples queries into semantic and geometry parts and only the former is used for contrastive learning. Experiments demonstrate the effectiveness of IROAM in improving roadside detector's performance. The results validate that IROAM has the capabilities to learn cross-domain information.
OCSU: Optical Chemical Structure Understanding for Molecule-centric Scientific Discovery
Jan 26, 2025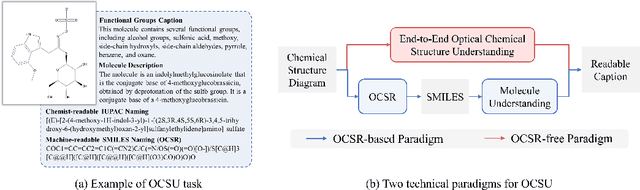


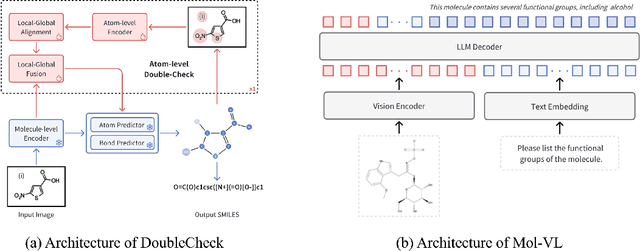
Understanding the chemical structure from a graphical representation of a molecule is a challenging image caption task that would greatly benefit molecule-centric scientific discovery. Variations in molecular images and caption subtasks pose a significant challenge in both image representation learning and task modeling. Yet, existing methods only focus on a specific caption task that translates a molecular image into its graph structure, i.e., OCSR. In this paper, we propose the Optical Chemical Structure Understanding (OCSU) task, which extends OCSR to molecular image caption from motif level to molecule level and abstract level. We present two approaches for that, including an OCSR-based method and an end-to-end OCSR-free method. The proposed Double-Check achieves SOTA OCSR performance on real-world patent and journal article scenarios via attentive feature enhancement for local ambiguous atoms. Cascading with SMILES-based molecule understanding methods, it can leverage the power of existing task-specific models for OCSU. While Mol-VL is an end-to-end optimized VLM-based model. An OCSU dataset, Vis-CheBI20, is built based on the widely used CheBI20 dataset for training and evaluation. Extensive experimental results on Vis-CheBI20 demonstrate the effectiveness of the proposed approaches. Improving OCSR capability can lead to a better OCSU performance for OCSR-based approach, and the SOTA performance of Mol-VL demonstrates the great potential of end-to-end approach.
SpikeLM: Towards General Spike-Driven Language Modeling via Elastic Bi-Spiking Mechanisms
Jun 05, 2024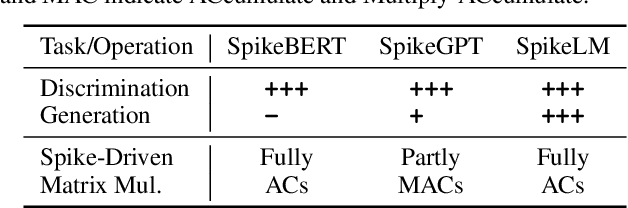
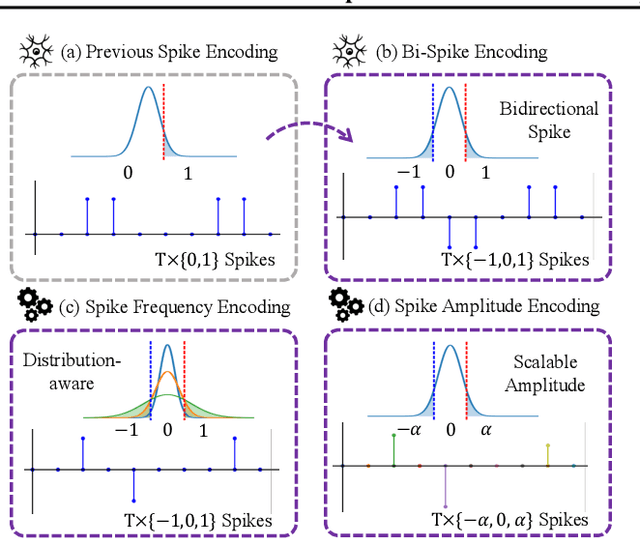
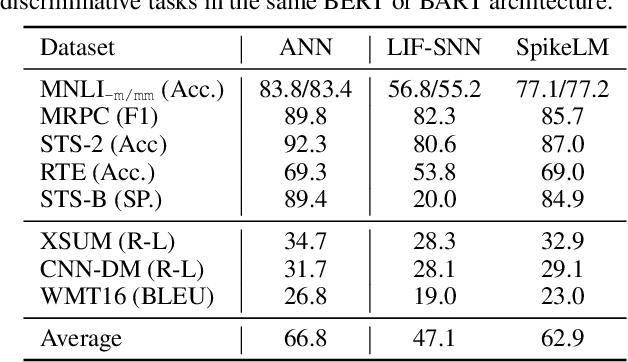
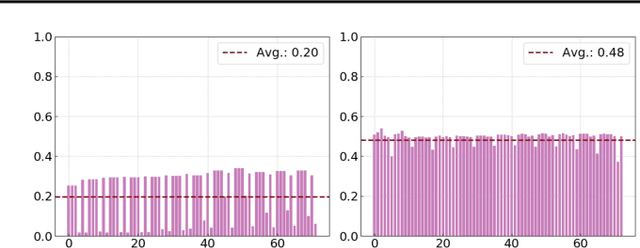
Towards energy-efficient artificial intelligence similar to the human brain, the bio-inspired spiking neural networks (SNNs) have advantages of biological plausibility, event-driven sparsity, and binary activation. Recently, large-scale language models exhibit promising generalization capability, making it a valuable issue to explore more general spike-driven models. However, the binary spikes in existing SNNs fail to encode adequate semantic information, placing technological challenges for generalization. This work proposes the first fully spiking mechanism for general language tasks, including both discriminative and generative ones. Different from previous spikes with {0,1} levels, we propose a more general spike formulation with bi-directional, elastic amplitude, and elastic frequency encoding, while still maintaining the addition nature of SNNs. In a single time step, the spike is enhanced by direction and amplitude information; in spike frequency, a strategy to control spike firing rate is well designed. We plug this elastic bi-spiking mechanism in language modeling, named SpikeLM. It is the first time to handle general language tasks with fully spike-driven models, which achieve much higher accuracy than previously possible. SpikeLM also greatly bridges the performance gap between SNNs and ANNs in language modeling. Our code is available at https://github.com/Xingrun-Xing/SpikeLM.