 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocateEdit-Bench: A Benchmark for Instruction-Based Editing Localization
Feb 05, 2026Recent advancements in image editing have enabled highly controllable and semantically-aware alteration of visual content, posing unprecedented challenges to manipulation localization. However, existing AI-generated forgery localization methods primarily focus on inpainting-based manipulations, making them ineffective against the latest instruction-based editing paradigms. To bridge this critical gap, we propose LocateEdit-Bench, a large-scale dataset comprising $231$K edited images, designed specifically to benchmark localization methods against instruction-driven image editing. Our dataset incorporates four cutting-edge editing models and covers three common edit types. We conduct a detailed analysis of the dataset and develop two multi-metric evaluation protocols to assess existing localization methods. Our work establishes a foundation to keep pace with the evolving landscape of image editing, thereby facilitating the development of effective methods for future forgery localization. Dataset will be open-sourced upon acceptance.
Let Language Constrain Geometry: Vision-Language Models as Semantic and Spatial Critics for 3D Generation
Nov 18, 2025
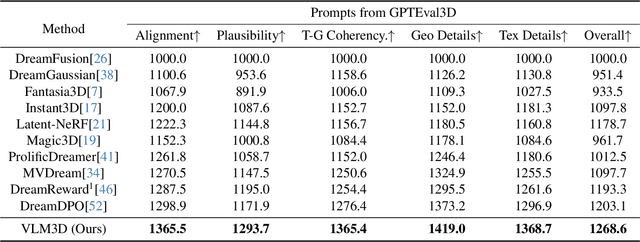
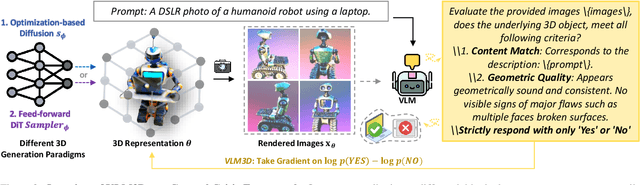
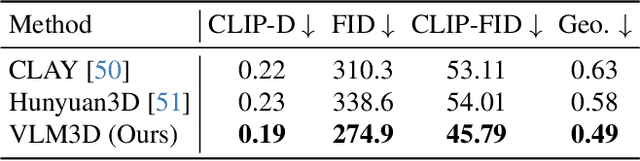
Text-to-3D generation has advanced rapidly, yet state-of-the-art models, encompassing both optimization-based and feed-forward architectures, still face two fundamental limitations. First, they struggle with coarse semantic alignment, often failing to capture fine-grained prompt details. Second, they lack robust 3D spatial understanding, leading to geometric inconsistencies and catastrophic failures in part assembly and spatial relationships. To address these challenges, we propose VLM3D, a general framework that repurposes large vision-language models (VLMs) as powerful, differentiable semantic and spatial critics. Our core contribution is a dual-query critic signal derived from the VLM's Yes or No log-odds, which assesses both semantic fidelity and geometric coherence. We demonstrate the generality of this guidance signal across two distinct paradigms: (1) As a reward objective for optimization-based pipelines, VLM3D significantly outperforms existing methods on standard benchmarks. (2) As a test-time guidance module for feed-forward pipelines, it actively steers the iterative sampling process of SOTA native 3D models to correct severe spatial errors. VLM3D establishes a principled and generalizable path to inject the VLM's rich, language-grounded understanding of both semantics and space into diverse 3D generative pipelines.
CoThink: Token-Efficient Reasoning via Instruct Models Guiding Reasoning Models
May 28, 2025Large language models (LLMs) benefit from increased test-time compute, a phenomenon known as test-time scaling. However, reasoning-optimized models often overthink even simple problems, producing excessively verbose outputs and leading to low token efficiency. By comparing these models with equally sized instruct models, we identify two key causes of this verbosity: (1) reinforcement learning reduces the information density of forward reasoning, and (2) backward chain-of thought training encourages redundant and often unnecessary verification steps. Since LLMs cannot assess the difficulty of a given problem, they tend to apply the same cautious reasoning strategy across all tasks, resulting in inefficient overthinking. To address this, we propose CoThink, an embarrassingly simple pipeline: an instruct model first drafts a high-level solution outline; a reasoning model then works out the solution. We observe that CoThink enables dynamic adjustment of reasoning depth based on input difficulty. Evaluated with three reasoning models DAPO, DeepSeek-R1, and QwQ on three datasets GSM8K, MATH500, and AIME24, CoThink reduces total token generation by 22.3% while maintaining pass@1 accuracy within a 0.42% margin on average. With reference to the instruct model, we formally define reasoning efficiency and observe a potential reasoning efficiency scaling law in LLMs.
Multi-Modality Expansion and Retention for LLMs through Parameter Merging and Decoupling
May 21, 2025Fine-tuning Large Language Models (LLMs) with multimodal encoders on modality-specific data expands the modalities that LLMs can handle, leading to the formation of Multimodal LLMs (MLLMs). However, this paradigm heavily relies on resource-intensive and inflexible fine-tuning from scratch with new multimodal data. In this paper, we propose MMER (Multi-modality Expansion and Retention), a training-free approach that integrates existing MLLMs for effective multimodal expansion while retaining their original performance. Specifically, MMER reuses MLLMs' multimodal encoders while merging their LLM parameters. By comparing original and merged LLM parameters, MMER generates binary masks to approximately separate LLM parameters for each modality. These decoupled parameters can independently process modality-specific inputs, reducing parameter conflicts and preserving original MLLMs' fidelity. MMER can also mitigate catastrophic forgetting by applying a similar process to MLLMs fine-tuned on new tasks. Extensive experiments show significant improvements over baselines, proving that MMER effectively expands LLMs' multimodal capabilities while retaining 99% of the original performance, and also markedly mitigates catastrophic forgetting.
Toward Embodied AGI: A Review of Embodied AI and the Road Ahead
May 20, 2025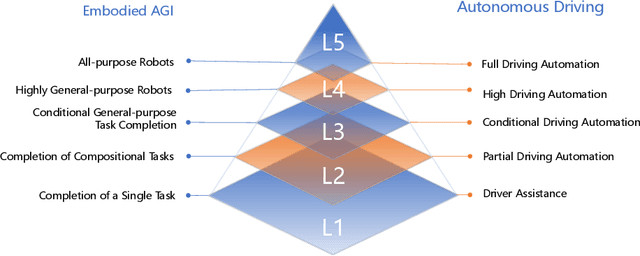


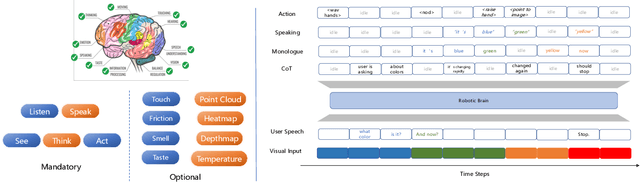
Artificial General Intelligence (AGI) is often envisioned as inherently embodied. With recent advances in robotics and foundational AI models, we stand at the threshold of a new era-one marked by increasingly generalized embodied AI systems. This paper contributes to the discourse by introducing a systematic taxonomy of Embodied AGI spanning five levels (L1-L5). We review existing research and challenges at the foundational stages (L1-L2) and outline the key components required to achieve higher-level capabilities (L3-L5). Building on these insights and existing technologies, we propose a conceptual framework for an L3+ robotic brain, offering both a technical outlook and a foundation for future exploration.
Exploiting Contextual Knowledge in LLMs through V-usable Information based Layer Enhancement
Apr 22, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities in various tasks, yet they often struggle with context-faithfulness generations that properly reflect contextual knowledge. While existing approaches focus on enhancing the decoding strategies, they ignore the fundamental mechanism of how contextual information is processed within LLMs' internal states. As a result, LLMs remain limited in their ability to fully leverage contextual knowledge. In this paper, we propose Context-aware Layer Enhancement (CaLE), a novel intervention method that enhances the utilization of contextual knowledge within LLMs' internal representations. By employing V-usable information analysis, CaLE strategically amplifies the growth of contextual information at an optimal layer, thereby enriching representations in the final layer. Our experiments demonstrate that CaLE effectively improves context-faithful generation in Question-Answering tasks, particularly in scenarios involving unknown or conflicting contextual knowledge.
If an LLM Were a Character, Would It Know Its Own Story? Evaluating Lifelong Learning in LLMs
Mar 30, 2025Large language models (LLMs) can carry out human-like dialogue, but unlike humans, they are stateless due to the superposition property. However, during multi-turn, multi-agent interactions, LLMs begin to exhibit consistent, character-like behaviors, hinting at a form of emergent lifelong learning. Despite this, existing benchmarks often fail to capture these dynamics, primarily focusing on static, open-ended evaluations. To address this gap, we introduce LIFESTATE-BENCH, a benchmark designed to assess lifelong learning in LLMs. It features two episodic datasets: Hamlet and a synthetic script collection, rich in narrative structure and character interactions. Our fact checking evaluation probes models' self-awareness, episodic memory retrieval, and relationship tracking, across both parametric and non-parametric approaches. Experiments on models like Llama3.1-8B, GPT-4-turbo, and DeepSeek R1, we demonstrate that nonparametric methods significantly outperform parametric ones in managing stateful learning. However, all models exhibit challenges with catastrophic forgetting as interactions extend, highlighting the need for further advancements in lifelong learning.
SeniorTalk: A Chinese Conversation Dataset with Rich Annotations for Super-Aged Seniors
Mar 20, 2025While voice technologies increasingly serve aging populations, current systems exhibit significant performance gaps due to inadequate training data capturing elderly-specific vocal characteristics like presbyphonia and dialectal variations. The limited data available on super-aged individuals in existing elderly speech datasets, coupled with overly simple recording styles and annotation dimensions, exacerbates this issue. To address the critical scarcity of speech data from individuals aged 75 and above, we introduce SeniorTalk, a carefully annotated Chinese spoken dialogue dataset. This dataset contains 55.53 hours of speech from 101 natural conversations involving 202 participants, ensuring a strategic balance across gender, region, and age. Through detailed annotation across multiple dimensions, it can support a wide range of speech tasks. We perform extensive experiments on speaker verification, speaker diarization, speech recognition, and speech editing tasks, offering crucial insights for the development of speech technologies targeting this age group.
Position-Aware Depth Decay Decoding ($D^3$): Boosting Large Language Model Inference Efficiency
Mar 11, 2025Due to the large number of parameters, the inference phase of Large Language Models (LLMs) is resource-intensive. Unlike traditional model compression, which needs retraining, recent dynamic computation methods show that not all components are required for inference, enabling a training-free pipeline. In this paper, we focus on the dynamic depth of LLM generation. A token-position aware layer skipping framework is proposed to save 1.5x times operations efficiently while maintaining performance. We first observed that tokens predicted later have lower perplexity and thus require less computation. Then, we propose a training-free algorithm called Position-Aware Depth Decay Decoding ($D^3$), which leverages a power-law decay function, $\left\lfloor L \times (\alpha^i) \right\rfloor$, to determine the number of layers to retain when generating token $T_i$. Remarkably, without any retraining, the $D^3$ achieves success across a wide range of generation tasks for the first time. Experiments on large language models (\ie the Llama) with $7 \sim 70$ billion parameters show that $D^3$ can achieve an average 1.5x speedup compared with the full-inference pipeline while maintaining comparable performance with nearly no performance drop ($<1\%$) on the GSM8K and BBH benchmarks.
Capability Localization: Capabilities Can be Localized rather than Individual Knowledge
Feb 28, 2025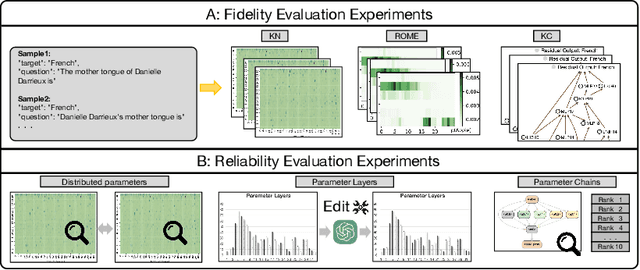
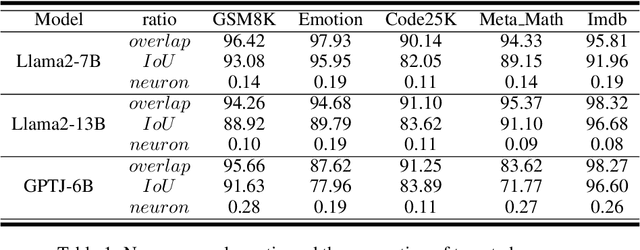
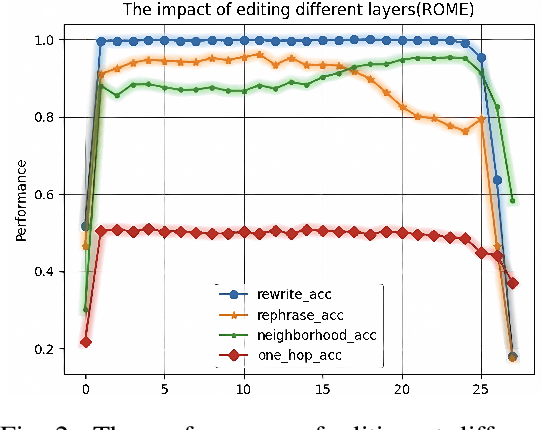
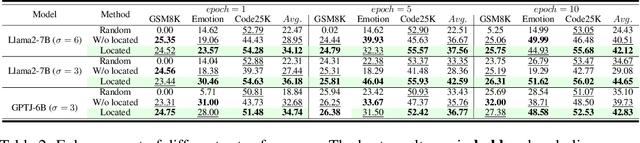
Large scale language models have achieved superior performance in tasks related to natural language processing, however, it is still unclear how model parameters affect performance improvement. Previous studies assumed that individual knowledge is stored in local parameters, and the storage form of individual knowledge is dispersed parameters, parameter layers, or parameter chains, which are not unified. We found through fidelity and reliability evaluation experiments that individual knowledge cannot be localized. Afterwards, we constructed a dataset for decoupling experiments and discovered the potential for localizing data commonalities. To further reveal this phenomenon, this paper proposes a Commonality Neuron Localization (CNL) method, which successfully locates commonality neurons and achieves a neuron overlap rate of 96.42% on the GSM8K dataset. Finally, we have demonstrated through cross data experiments that commonality neurons are a collection of capability neurons that possess the capability to enhance performance. Our code is available at https://github.com/nlpkeg/Capability-Neuron-Localization.