 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeECHO: Towards Emotionally Appropriate and Contextually Aware Interactive Head Generation
Mar 18, 2026In natural face-to-face interaction, participants seamlessly alternate between speaking and listening, producing facial behaviors (FBs) that are finely informed by long-range context and naturally exhibit contextual appropriateness and emotional rationality. Interactive Head Generation (IHG) aims to synthesize lifelike avatar head video emulating such capabilities. Existing IHG methods typically condition on dual-track signals (i.e., human user's behaviors and pre-defined audio for avatar) within a short temporal window, jointly driving generation of avatar's audio-aligned lip articulation and non-verbal FBs. However, two main challenges persist in these methods: (i) the reliance on short-clip behavioral cues without long-range contextual modeling leads them to produce facial behaviors lacking contextual appropriateness; and (ii) the entangled, role-agnostic fusion of dual-track signals empirically introduces cross-signal interference, potentially compromising lip-region synchronization during speaking. To this end, we propose ECHO, a novel IHG framework comprising two key components: a Long-range Contextual Understanding (LCU) component that facilitates contextual understanding of both behavior-grounded dynamics and linguistic-driven affective semantics to promote contextual appropriateness and emotional rationality of synthesized avatar FBs; and a block-wise Spatial-aware Decoupled Cross-attention Modulation (SDCM) module, that preserves self-audio-driven lip articulation while adaptively integrating user contextual behavioral cues for non-lip facial regions, complemented by our designed two-stage training paradigm, to jointly enhance lip synchronization and visual fidelity. Extensive experiments demonstrate the effectiveness of proposed components and ECHO's superior IHG performance.
Reflecting Twice before Speaking with Empathy: Self-Reflective Alternating Inference for Empathy-Aware End-to-End Spoken Dialogue
Jan 26, 2026End-to-end Spoken Language Models (SLMs) hold great potential for paralinguistic perception, and numerous studies have aimed to enhance their capabilities, particularly for empathetic dialogue. However, current approaches largely depend on rigid supervised signals, such as ground-truth response in supervised fine-tuning or preference scores in reinforcement learning. Such reliance is fundamentally limited for modeling complex empathy, as there is no single "correct" response and a simple numerical score cannot fully capture the nuances of emotional expression or the appropriateness of empathetic behavior. To address these limitations, we sequentially introduce EmpathyEval, a descriptive natural-language-based evaluation model for assessing empathetic quality in spoken dialogues. Building upon EmpathyEval, we propose ReEmpathy, an end-to-end SLM that enhances empathetic dialogue through a novel Empathetic Self-Reflective Alternating Inference mechanism, which interleaves spoken response generation with free-form, empathy-related reflective reasoning. Extensive experiments demonstrate that ReEmpathy substantially improves empathy-sensitive spoken dialogue by enabling reflective reasoning, offering a promising approach toward more emotionally intelligent and empathy-aware human-computer interactions.
Learning Personalised Human Internal Cognition from External Expressive Behaviours for Real Personality Recognition
Jul 31, 2025



Automatic real personality recognition (RPR) aims to evaluate human real personality traits from their expressive behaviours. However, most existing solutions generally act as external observers to infer observers' personality impressions based on target individuals' expressive behaviours, which significantly deviate from their real personalities and consistently lead to inferior recognition performance. Inspired by the association between real personality and human internal cognition underlying the generation of expressive behaviours, we propose a novel RPR approach that efficiently simulates personalised internal cognition from easy-accessible external short audio-visual behaviours expressed by the target individual. The simulated personalised cognition, represented as a set of network weights that enforce the personalised network to reproduce the individual-specific facial reactions, is further encoded as a novel graph containing two-dimensional node and edge feature matrices, with a novel 2D Graph Neural Network (2D-GNN) proposed for inferring real personality traits from it. To simulate real personality-related cognition, an end-to-end strategy is designed to jointly train our cognition simulation, 2D graph construction, and personality recognition modules.
StreamMel: Real-Time Zero-shot Text-to-Speech via Interleaved Continuous Autoregressive Modeling
Jun 14, 2025Recent advances in zero-shot text-to-speech (TTS) synthesis have achieved high-quality speech generation for unseen speakers, but most systems remain unsuitable for real-time applications because of their offline design. Current streaming TTS paradigms often rely on multi-stage pipelines and discrete representations, leading to increased computational cost and suboptimal system performance. In this work, we propose StreamMel, a pioneering single-stage streaming TTS framework that models continuous mel-spectrograms. By interleaving text tokens with acoustic frames, StreamMel enables low-latency, autoregressive synthesis while preserving high speaker similarity and naturalness. Experiments on LibriSpeech demonstrate that StreamMel outperforms existing streaming TTS baselines in both quality and latency. It even achieves performance comparable to offline systems while supporting efficient real-time generation, showcasing broad prospects for integration with real-time speech large language models. Audio samples are available at: https://aka.ms/StreamMel.
RA-CLAP: Relation-Augmented Emotional Speaking Style Contrastive Language-Audio Pretraining For Speech Retrieval
May 26, 2025The Contrastive Language-Audio Pretraining (CLAP) model has demonstrated excellent performance in general audio description-related tasks, such as audio retrieval. However, in the emerging field of emotional speaking style description (ESSD), cross-modal contrastive pretraining remains largely unexplored. In this paper, we propose a novel speech retrieval task called emotional speaking style retrieval (ESSR), and ESS-CLAP, an emotional speaking style CLAP model tailored for learning relationship between speech and natural language descriptions. In addition, we further propose relation-augmented CLAP (RA-CLAP) to address the limitation of traditional methods that assume a strict binary relationship between caption and audio. The model leverages self-distillation to learn the potential local matching relationships between speech and descriptions, thereby enhancing generalization ability. The experimental results validate the effectiveness of RA-CLAP, providing valuable reference in ESSD.
Discrete Audio Representations for Automated Audio Captioning
May 21, 2025


Discrete audio representations, termed audio tokens, are broadly categorized into semantic and acoustic tokens, typically generated through unsupervised tokenization of continuous audio representations. However, their applicability to automated audio captioning (AAC) remains underexplored. This paper systematically investigates the viability of audio token-driven models for AAC through comparative analyses of various tokenization methods. Our findings reveal that audio tokenization leads to performance degradation in AAC models compared to those that directly utilize continuous audio representations. To address this issue, we introduce a supervised audio tokenizer trained with an audio tagging objective. Unlike unsupervised tokenizers, which lack explicit semantic understanding, the proposed tokenizer effectively captures audio event information. Experiments conducted on the Clotho dataset demonstrate that the proposed audio tokens outperform conventional audio tokens in the AAC task.
CS-Dialogue: A 104-Hour Dataset of Spontaneous Mandarin-English Code-Switching Dialogues for Speech Recognition
Feb 26, 2025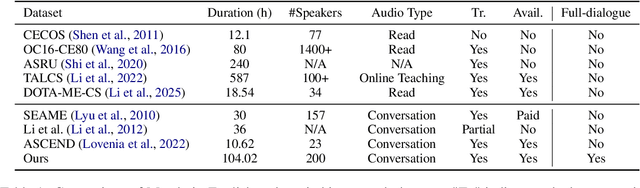



Code-switching (CS), the alternation between two or more languages within a single conversation, presents significant challenges for automatic speech recognition (ASR) systems. Existing Mandarin-English code-switching datasets often suffer from limitations in size, spontaneity, and the lack of full-length dialogue recordings with transcriptions, hindering the development of robust ASR models for real-world conversational scenarios. This paper introduces CS-Dialogue, a novel large-scale Mandarin-English code-switching speech dataset comprising 104 hours of spontaneous conversations from 200 speakers. Unlike previous datasets, CS-Dialogue provides full-length dialogue recordings with complete transcriptions, capturing naturalistic code-switching patterns in continuous speech. We describe the data collection and annotation processes, present detailed statistics of the dataset, and establish benchmark ASR performance using state-of-the-art models. Our experiments, using Transformer, Conformer, and Branchformer, demonstrate the challenges of code-switching ASR, and show that existing pre-trained models such as Whisper still have the space to improve. The CS-Dialogue dataset will be made freely available for all academic purposes.
MusicEval: A Generative Music Corpus with Expert Ratings for Automatic Text-to-Music Evaluation
Jan 18, 2025



The technology for generating music from textual descriptions has seen rapid advancements. However, evaluating text-to-music (TTM) systems remains a significant challenge, primarily due to the difficulty of balancing performance and cost with existing objective and subjective evaluation methods. In this paper, we propose an automatic assessment task for TTM models to align with human perception. To address the TTM evaluation challenges posed by the professional requirements of music evaluation and the complexity of the relationship between text and music, we collect MusicEval, the first generative music assessment dataset. This dataset contains 2,748 music clips generated by 31 advanced and widely used models in response to 384 text prompts, along with 13,740 ratings from 14 music experts. Furthermore, we design a CLAP-based assessment model built on this dataset, and our experimental results validate the feasibility of the proposed task, providing a valuable reference for future development in TTM evaluation. The dataset is available at https://www.aishelltech.com/AISHELL_7A.
Enhancing Multimodal Emotion Recognition through Multi-Granularity Cross-Modal Alignment
Dec 30, 2024Multimodal emotion recognition (MER), leveraging speech and text, has emerged as a pivotal domain within human-computer interaction, demanding sophisticated methods for effective multimodal integration. The challenge of aligning features across these modalities is significant, with most existing approaches adopting a singular alignment strategy. Such a narrow focus not only limits model performance but also fails to address the complexity and ambiguity inherent in emotional expressions. In response, this paper introduces a Multi-Granularity Cross-Modal Alignment (MGCMA) framework, distinguished by its comprehensive approach encompassing distribution-based, instance-based, and token-based alignment modules. This framework enables a multi-level perception of emotional information across modalities. Our experiments on IEMOCAP demonstrate that our proposed method outperforms current state-of-the-art techniques.
Multi-modal Speech Emotion Recognition via Feature Distribution Adaptation Network
Nov 02, 2024



In this paper, we propose a novel deep inductive transfer learning framework, named feature distribution adaptation network, to tackle the challenging multi-modal speech emotion recognition problem. Our method aims to use deep transfer learning strategies to align visual and audio feature distributions to obtain consistent representation of emotion, thereby improving the performance of speech emotion recognition. In our model, the pre-trained ResNet-34 is utilized for feature extraction for facial expression images and acoustic Mel spectrograms, respectively. Then, the cross-attention mechanism is introduced to model the intrinsic similarity relationships of multi-modal features. Finally, the multi-modal feature distribution adaptation is performed efficiently with feed-forward network, which is extended using the local maximum mean discrepancy loss. Experiments are carried out on two benchmark datasets, and the results demonstrate that our model can achieve excellent performance compared with existing ones.