 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLooped World Models
Jun 16, 2026Current world models face a fundamental tension: faithful long-horizon simulation demands deep computation, but deeper models are expensive to deploy and prone to compounding errors. We resolve this by introducing Looped World Models (LoopWM), which are the first looped architectures for world modelling. Our method iteratively refines latent environment states through a parameter-shared transformer block. This yield up to 100x parameter efficiency over conventional approaches with adaptive computation that automatically scales depth to match the complexity of each prediction step. Orthogonal to scaling model size and training data, LoopWM establishes iterative latent depth as a new scaling axis for world simulation, which might significantly push the community forward.
Agentic Cognitive Profiling: Realigning Automated Alzheimer's Disease Detection with Clinical Construct Validity
Mar 18, 2026Automated Alzheimer's Disease (AD) screening has predominantly followed the inductive paradigm of pattern recognition, which directly maps the input signal to the outcome label. This paradigm sacrifices construct validity of clinical protocol for statistical shortcuts. This paper proposes Agentic Cognitive Profiling (ACP), an agentic framework that realigns automated screening with clinical protocol logic across multiple cognitive domains. Rather than learning opaque mappings from transcripts to labels, the framework decomposes standardized assessments into atomic cognitive tasks and orchestrates specialized LLM agents to extract verifiable scoring primitives. Central to our design is decoupling semantic understanding from measurement by delegating all quantification to deterministic function calling, thereby mitigating hallucination and restoring construct validity. Unlike popular datasets that typically comprise around a hundred participants under a single task, we evaluate on a clinically-annotated corpus of 402 participants across eight structured cognitive tasks spanning multiple cognitive domains. The framework achieves 90.5% score match rate in task examination and 85.3% accuracy in AD prediction, surpassing popular baselines while generating interpretable cognitive profiles grounded in behavioral evidence. This work demonstrates that construct validity and predictive performance need not be traded off, charting a path toward AD screening systems that explain rather than merely predict.
StreamMel: Real-Time Zero-shot Text-to-Speech via Interleaved Continuous Autoregressive Modeling
Jun 14, 2025Recent advances in zero-shot text-to-speech (TTS) synthesis have achieved high-quality speech generation for unseen speakers, but most systems remain unsuitable for real-time applications because of their offline design. Current streaming TTS paradigms often rely on multi-stage pipelines and discrete representations, leading to increased computational cost and suboptimal system performance. In this work, we propose StreamMel, a pioneering single-stage streaming TTS framework that models continuous mel-spectrograms. By interleaving text tokens with acoustic frames, StreamMel enables low-latency, autoregressive synthesis while preserving high speaker similarity and naturalness. Experiments on LibriSpeech demonstrate that StreamMel outperforms existing streaming TTS baselines in both quality and latency. It even achieves performance comparable to offline systems while supporting efficient real-time generation, showcasing broad prospects for integration with real-time speech large language models. Audio samples are available at: https://aka.ms/StreamMel.
Towards One-bit ASR: Extremely Low-bit Conformer Quantization Using Co-training and Stochastic Precision
May 27, 2025Model compression has become an emerging need as the sizes of modern speech systems rapidly increase. In this paper, we study model weight quantization, which directly reduces the memory footprint to accommodate computationally resource-constrained applications. We propose novel approaches to perform extremely low-bit (i.e., 2-bit and 1-bit) quantization of Conformer automatic speech recognition systems using multiple precision model co-training, stochastic precision, and tensor-wise learnable scaling factors to alleviate quantization incurred performance loss. The proposed methods can achieve performance-lossless 2-bit and 1-bit quantization of Conformer ASR systems trained with the 300-hr Switchboard and 960-hr LibriSpeech corpus. Maximum overall performance-lossless compression ratios of 16.2 and 16.6 times are achieved without a statistically significant increase in the word error rate (WER) over the full precision baseline systems, respectively.
Zero-Shot Streaming Text to Speech Synthesis with Transducer and Auto-Regressive Modeling
May 26, 2025Zero-shot streaming text-to-speech is an important research topic in human-computer interaction. Existing methods primarily use a lookahead mechanism, relying on future text to achieve natural streaming speech synthesis, which introduces high processing latency. To address this issue, we propose SMLLE, a streaming framework for generating high-quality speech frame-by-frame. SMLLE employs a Transducer to convert text into semantic tokens in real time while simultaneously obtaining duration alignment information. The combined outputs are then fed into a fully autoregressive (AR) streaming model to reconstruct mel-spectrograms. To further stabilize the generation process, we design a Delete < Bos > Mechanism that allows the AR model to access future text introducing as minimal delay as possible. Experimental results suggest that the SMLLE outperforms current streaming TTS methods and achieves comparable performance over sentence-level TTS systems. Samples are available on https://anonymous.4open.science/w/demo_page-48B7/.
Dynamic Uncertainty Learning with Noisy Correspondence for Text-Based Person Search
May 10, 2025Text-to-image person search aims to identify an individual based on a text description. To reduce data collection costs, large-scale text-image datasets are created from co-occurrence pairs found online. However, this can introduce noise, particularly mismatched pairs, which degrade retrieval performance. Existing methods often focus on negative samples, amplifying this noise. To address these issues, we propose the Dynamic Uncertainty and Relational Alignment (DURA) framework, which includes the Key Feature Selector (KFS) and a new loss function, Dynamic Softmax Hinge Loss (DSH-Loss). KFS captures and models noise uncertainty, improving retrieval reliability. The bidirectional evidence from cross-modal similarity is modeled as a Dirichlet distribution, enhancing adaptability to noisy data. DSH adjusts the difficulty of negative samples to improve robustness in noisy environments. Our experiments on three datasets show that the method offers strong noise resistance and improves retrieval performance in both low- and high-noise scenarios.
Pseudo-Autoregressive Neural Codec Language Models for Efficient Zero-Shot Text-to-Speech Synthesis
Apr 14, 2025
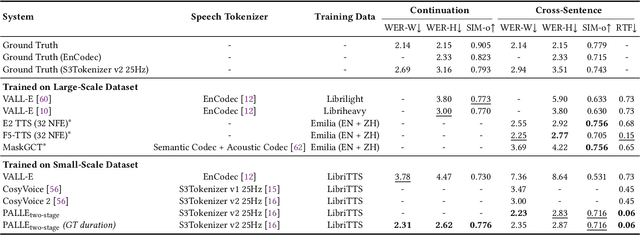

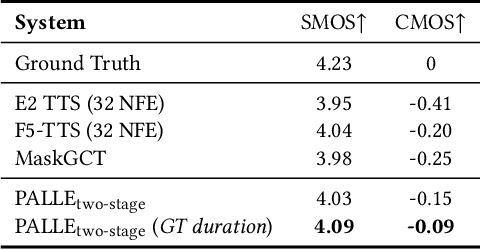
Recent zero-shot text-to-speech (TTS) systems face a common dilemma: autoregressive (AR) models suffer from slow generation and lack duration controllability, while non-autoregressive (NAR) models lack temporal modeling and typically require complex designs. In this paper, we introduce a novel pseudo-autoregressive (PAR) codec language modeling approach that unifies AR and NAR modeling. Combining explicit temporal modeling from AR with parallel generation from NAR, PAR generates dynamic-length spans at fixed time steps. Building on PAR, we propose PALLE, a two-stage TTS system that leverages PAR for initial generation followed by NAR refinement. In the first stage, PAR progressively generates speech tokens along the time dimension, with each step predicting all positions in parallel but only retaining the left-most span. In the second stage, low-confidence tokens are iteratively refined in parallel, leveraging the global contextual information. Experiments demonstrate that PALLE, trained on LibriTTS, outperforms state-of-the-art systems trained on large-scale data, including F5-TTS, E2-TTS, and MaskGCT, on the LibriSpeech test-clean set in terms of speech quality, speaker similarity, and intelligibility, while achieving up to ten times faster inference speed. Audio samples are available at https://anonymous-palle.github.io.
$C^2$AV-TSE: Context and Confidence-aware Audio Visual Target Speaker Extraction
Apr 01, 2025Audio-Visual Target Speaker Extraction (AV-TSE) aims to mimic the human ability to enhance auditory perception using visual cues. Although numerous models have been proposed recently, most of them estimate target signals by primarily relying on local dependencies within acoustic features, underutilizing the human-like capacity to infer unclear parts of speech through contextual information. This limitation results in not only suboptimal performance but also inconsistent extraction quality across the utterance, with some segments exhibiting poor quality or inadequate suppression of interfering speakers. To close this gap, we propose a model-agnostic strategy called the Mask-And-Recover (MAR). It integrates both inter- and intra-modality contextual correlations to enable global inference within extraction modules. Additionally, to better target challenging parts within each sample, we introduce a Fine-grained Confidence Score (FCS) model to assess extraction quality and guide extraction modules to emphasize improvement on low-quality segments. To validate the effectiveness of our proposed model-agnostic training paradigm, six popular AV-TSE backbones were adopted for evaluation on the VoxCeleb2 dataset, demonstrating consistent performance improvements across various metrics.
Next Token Prediction Towards Multimodal Intelligence: A Comprehensive Survey
Dec 30, 2024



Building on the foundations of language modeling in natural language processing, Next Token Prediction (NTP) has evolved into a versatile training objective for machine learning tasks across various modalities, achieving considerable success. As Large Language Models (LLMs) have advanced to unify understanding and generation tasks within the textual modality, recent research has shown that tasks from different modalities can also be effectively encapsulated within the NTP framework, transforming the multimodal information into tokens and predict the next one given the context. This survey introduces a comprehensive taxonomy that unifies both understanding and generation within multimodal learning through the lens of NTP. The proposed taxonomy covers five key aspects: Multimodal tokenization, MMNTP model architectures, unified task representation, datasets \& evaluation, and open challenges. This new taxonomy aims to aid researchers in their exploration of multimodal intelligence. An associated GitHub repository collecting the latest papers and repos is available at https://github.com/LMM101/Awesome-Multimodal-Next-Token-Prediction
Interleaved Speech-Text Language Models are Simple Streaming Text to Speech Synthesizers
Dec 23, 2024This paper introduces Interleaved Speech-Text Language Model (IST-LM) for streaming zero-shot Text-to-Speech (TTS). Unlike many previous approaches, IST-LM is directly trained on interleaved sequences of text and speech tokens with a fixed ratio, eliminating the need for additional efforts in duration prediction and grapheme-to-phoneme alignment. The ratio of text chunk size to speech chunk size is crucial for the performance of IST-LM. To explore this, we conducted a comprehensive series of statistical analyses on the training data and performed correlation analysis with the final performance, uncovering several key factors: 1) the distance between speech tokens and their corresponding text tokens, 2) the number of future text tokens accessible to each speech token, and 3) the frequency of speech tokens precedes their corresponding text tokens. Experimental results demonstrate how to achieve an optimal streaming TTS system without complicated engineering optimization, which has a limited gap with the non-streaming system. IST-LM is conceptually simple and empirically powerful, paving the way for streaming TTS with minimal overhead while largely maintaining performance, showcasing broad prospects coupled with real-time text stream from LLMs.