 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenVision 3: A Family of Unified Visual Encoder for Both Understanding and Generation
Jan 21, 2026This paper presents a family of advanced vision encoder, named OpenVision 3, that learns a single, unified visual representation that can serve both image understanding and image generation. Our core architecture is simple: we feed VAE-compressed image latents to a ViT encoder and train its output to support two complementary roles. First, the encoder output is passed to the ViT-VAE decoder to reconstruct the original image, encouraging the representation to capture generative structure. Second, the same representation is optimized with contrastive learning and image-captioning objectives, strengthening semantic features. By jointly optimizing reconstruction- and semantics-driven signals in a shared latent space, the encoder learns representations that synergize and generalize well across both regimes. We validate this unified design through extensive downstream evaluations with the encoder frozen. For multimodal understanding, we plug the encoder into the LLaVA-1.5 framework: it performs comparably with a standard CLIP vision encoder (e.g., 62.4 vs 62.2 on SeedBench, and 83.7 vs 82.9 on POPE). For generation, we test it under the RAE framework: ours substantially surpasses the standard CLIP-based encoder (e.g., gFID: 1.89 vs 2.54 on ImageNet). We hope this work can spur future research on unified modeling.
A Unified Neural Codec Language Model for Selective Editable Text to Speech Generation
Jan 18, 2026Neural codec language models achieve impressive zero-shot Text-to-Speech (TTS) by fully imitating the acoustic characteristics of a short speech prompt, including timbre, prosody, and paralinguistic information. However, such holistic imitation limits their ability to isolate and control individual attributes. In this paper, we present a unified codec language model SpeechEdit that extends zero-shot TTS with a selective control mechanism. By default, SpeechEdit reproduces the complete acoustic profile inferred from the speech prompt, but it selectively overrides only the attributes specified by explicit control instructions. To enable controllable modeling, SpeechEdit is trained on our newly constructed LibriEdit dataset, which provides delta (difference-aware) training pairs derived from LibriHeavy. Experimental results show that our approach maintains naturalness and robustness while offering flexible and localized control over desired attributes. Audio samples are available at https://speech-editing.github.io/speech-editing/.
Next Tokens Denoising for Speech Synthesis
Jul 30, 2025While diffusion and autoregressive (AR) models have significantly advanced generative modeling, they each present distinct limitations. AR models, which rely on causal attention, cannot exploit future context and suffer from slow generation speeds. Conversely, diffusion models struggle with key-value (KV) caching. To overcome these challenges, we introduce Dragon-FM, a novel text-to-speech (TTS) design that unifies AR and flow-matching. This model processes 48 kHz audio codec tokens in chunks at a compact 12.5 tokens per second rate. This design enables AR modeling across chunks, ensuring global coherence, while parallel flow-matching within chunks facilitates fast iterative denoising. Consequently, the proposed model can utilize KV-cache across chunks and incorporate future context within each chunk. Furthermore, it bridges continuous and discrete feature modeling, demonstrating that continuous AR flow-matching can predict discrete tokens with finite scalar quantizers. This efficient codec and fast chunk-autoregressive architecture also makes the proposed model particularly effective for generating extended content. Experiment for demos of our work} on podcast datasets demonstrate its capability to efficiently generate high-quality zero-shot podcasts.
StreamMel: Real-Time Zero-shot Text-to-Speech via Interleaved Continuous Autoregressive Modeling
Jun 14, 2025Recent advances in zero-shot text-to-speech (TTS) synthesis have achieved high-quality speech generation for unseen speakers, but most systems remain unsuitable for real-time applications because of their offline design. Current streaming TTS paradigms often rely on multi-stage pipelines and discrete representations, leading to increased computational cost and suboptimal system performance. In this work, we propose StreamMel, a pioneering single-stage streaming TTS framework that models continuous mel-spectrograms. By interleaving text tokens with acoustic frames, StreamMel enables low-latency, autoregressive synthesis while preserving high speaker similarity and naturalness. Experiments on LibriSpeech demonstrate that StreamMel outperforms existing streaming TTS baselines in both quality and latency. It even achieves performance comparable to offline systems while supporting efficient real-time generation, showcasing broad prospects for integration with real-time speech large language models. Audio samples are available at: https://aka.ms/StreamMel.
Zero-Shot Streaming Text to Speech Synthesis with Transducer and Auto-Regressive Modeling
May 26, 2025Zero-shot streaming text-to-speech is an important research topic in human-computer interaction. Existing methods primarily use a lookahead mechanism, relying on future text to achieve natural streaming speech synthesis, which introduces high processing latency. To address this issue, we propose SMLLE, a streaming framework for generating high-quality speech frame-by-frame. SMLLE employs a Transducer to convert text into semantic tokens in real time while simultaneously obtaining duration alignment information. The combined outputs are then fed into a fully autoregressive (AR) streaming model to reconstruct mel-spectrograms. To further stabilize the generation process, we design a Delete < Bos > Mechanism that allows the AR model to access future text introducing as minimal delay as possible. Experimental results suggest that the SMLLE outperforms current streaming TTS methods and achieves comparable performance over sentence-level TTS systems. Samples are available on https://anonymous.4open.science/w/demo_page-48B7/.
OpenVision: A Fully-Open, Cost-Effective Family of Advanced Vision Encoders for Multimodal Learning
May 07, 2025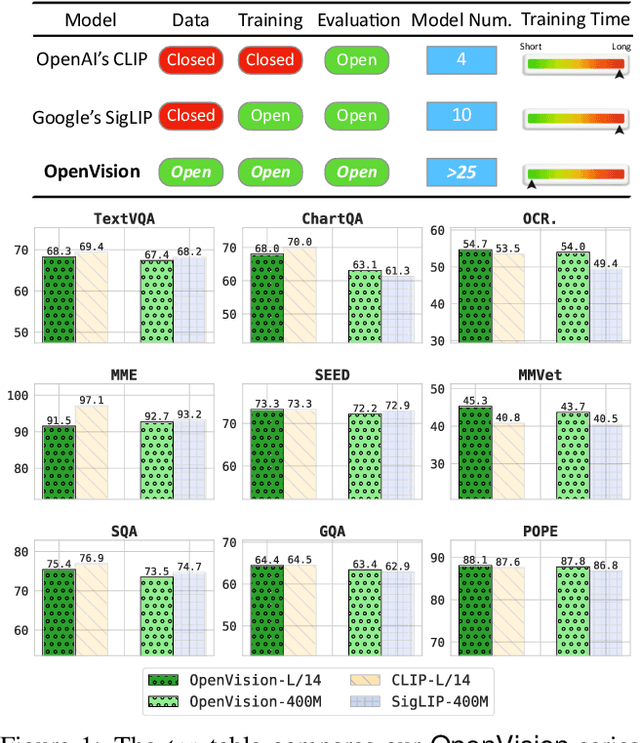
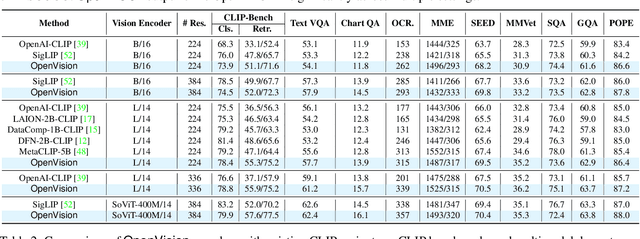
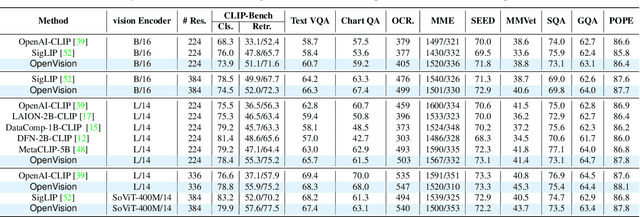
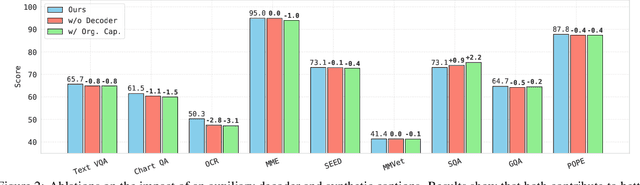
OpenAI's CLIP, released in early 2021, have long been the go-to choice of vision encoder for building multimodal foundation models. Although recent alternatives such as SigLIP have begun to challenge this status quo, to our knowledge none are fully open: their training data remains proprietary and/or their training recipes are not released. This paper fills this gap with OpenVision, a fully-open, cost-effective family of vision encoders that match or surpass the performance of OpenAI's CLIP when integrated into multimodal frameworks like LLaVA. OpenVision builds on existing works -- e.g., CLIPS for training framework and Recap-DataComp-1B for training data -- while revealing multiple key insights in enhancing encoder quality and showcasing practical benefits in advancing multimodal models. By releasing vision encoders spanning from 5.9M to 632.1M parameters, OpenVision offers practitioners a flexible trade-off between capacity and efficiency in building multimodal models: larger models deliver enhanced multimodal performance, while smaller versions enable lightweight, edge-ready multimodal deployments.
Pseudo-Autoregressive Neural Codec Language Models for Efficient Zero-Shot Text-to-Speech Synthesis
Apr 14, 2025
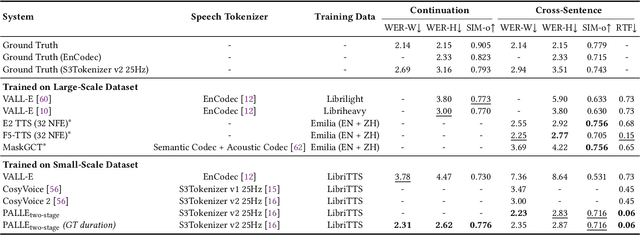

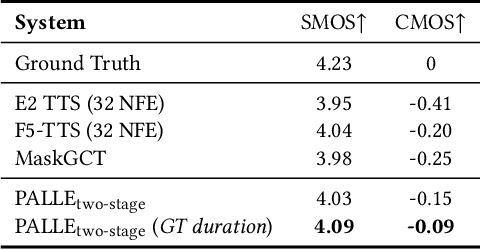
Recent zero-shot text-to-speech (TTS) systems face a common dilemma: autoregressive (AR) models suffer from slow generation and lack duration controllability, while non-autoregressive (NAR) models lack temporal modeling and typically require complex designs. In this paper, we introduce a novel pseudo-autoregressive (PAR) codec language modeling approach that unifies AR and NAR modeling. Combining explicit temporal modeling from AR with parallel generation from NAR, PAR generates dynamic-length spans at fixed time steps. Building on PAR, we propose PALLE, a two-stage TTS system that leverages PAR for initial generation followed by NAR refinement. In the first stage, PAR progressively generates speech tokens along the time dimension, with each step predicting all positions in parallel but only retaining the left-most span. In the second stage, low-confidence tokens are iteratively refined in parallel, leveraging the global contextual information. Experiments demonstrate that PALLE, trained on LibriTTS, outperforms state-of-the-art systems trained on large-scale data, including F5-TTS, E2-TTS, and MaskGCT, on the LibriSpeech test-clean set in terms of speech quality, speaker similarity, and intelligibility, while achieving up to ten times faster inference speed. Audio samples are available at https://anonymous-palle.github.io.
Continuous Speech Tokens Makes LLMs Robust Multi-Modality Learners
Dec 06, 2024



Recent advances in GPT-4o like multi-modality models have demonstrated remarkable progress for direct speech-to-speech conversation, with real-time speech interaction experience and strong speech understanding ability. However, current research focuses on discrete speech tokens to align with discrete text tokens for language modelling, which depends on an audio codec with residual connections or independent group tokens, such a codec usually leverages large scale and diverse datasets training to ensure that the discrete speech codes have good representation for varied domain, noise, style data reconstruction as well as a well-designed codec quantizer and encoder-decoder architecture for discrete token language modelling. This paper introduces Flow-Omni, a continuous speech token based GPT-4o like model, capable of real-time speech interaction and low streaming latency. Specifically, first, instead of cross-entropy loss only, we combine flow matching loss with a pretrained autoregressive LLM and a small MLP network to predict the probability distribution of the continuous-valued speech tokens from speech prompt. second, we incorporated the continuous speech tokens to Flow-Omni multi-modality training, thereby achieving robust speech-to-speech performance with discrete text tokens and continuous speech tokens together. Experiments demonstrate that, compared to discrete text and speech multi-modality training and its variants, the continuous speech tokens mitigate robustness issues by avoiding the inherent flaws of discrete speech code's representation loss for LLM.
CLIPS: An Enhanced CLIP Framework for Learning with Synthetic Captions
Nov 25, 2024



Previous works show that noisy, web-crawled image-text pairs may limit vision-language pretraining like CLIP and propose learning with synthetic captions as a promising alternative. Our work continues this effort, introducing two simple yet effective designs to better leverage richly described synthetic captions. Firstly, by observing a strong inverse effect in learning with synthetic captions -- the short synthetic captions can generally lead to MUCH higher performance than full-length ones -- we therefore fed only partial synthetic captions to the text encoder. Secondly, we incorporate an autoregressive captioner to mimic the recaptioning process -- by conditioning on the paired image input and web-crawled text description, the captioner learns to predict the full-length synthetic caption generated by advanced MLLMs. Experiments show that our framework significantly improves zero-shot performance in cross-modal retrieval tasks, setting new SOTA results on MSCOCO and Flickr30K. Moreover, such trained vision encoders can enhance the visual capability of LLaVA, showing strong improvements on a range of MLLM benchmarks. Our project page is https://ucsc-vlaa.github.io/CLIPS/.
Isochrony-Controlled Speech-to-Text Translation: A study on translating from Sino-Tibetan to Indo-European Languages
Nov 11, 2024



End-to-end speech translation (ST), which translates source language speech directly into target language text, has garnered significant attention in recent years. Many ST applications require strict length control to ensure that the translation duration matches the length of the source audio, including both speech and pause segments. Previous methods often controlled the number of words or characters generated by the Machine Translation model to approximate the source sentence's length without considering the isochrony of pauses and speech segments, as duration can vary between languages. To address this, we present improvements to the duration alignment component of our sequence-to-sequence ST model. Our method controls translation length by predicting the duration of speech and pauses in conjunction with the translation process. This is achieved by providing timing information to the decoder, ensuring it tracks the remaining duration for speech and pauses while generating the translation. The evaluation on the Zh-En test set of CoVoST 2, demonstrates that the proposed Isochrony-Controlled ST achieves 0.92 speech overlap and 8.9 BLEU, which has only a 1.4 BLEU drop compared to the ST baseline.