 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIsochrony-Controlled Speech-to-Text Translation: A study on translating from Sino-Tibetan to Indo-European Languages
Nov 11, 2024



End-to-end speech translation (ST), which translates source language speech directly into target language text, has garnered significant attention in recent years. Many ST applications require strict length control to ensure that the translation duration matches the length of the source audio, including both speech and pause segments. Previous methods often controlled the number of words or characters generated by the Machine Translation model to approximate the source sentence's length without considering the isochrony of pauses and speech segments, as duration can vary between languages. To address this, we present improvements to the duration alignment component of our sequence-to-sequence ST model. Our method controls translation length by predicting the duration of speech and pauses in conjunction with the translation process. This is achieved by providing timing information to the decoder, ensuring it tracks the remaining duration for speech and pauses while generating the translation. The evaluation on the Zh-En test set of CoVoST 2, demonstrates that the proposed Isochrony-Controlled ST achieves 0.92 speech overlap and 8.9 BLEU, which has only a 1.4 BLEU drop compared to the ST baseline.
Investigating Neural Audio Codecs for Speech Language Model-Based Speech Generation
Sep 06, 2024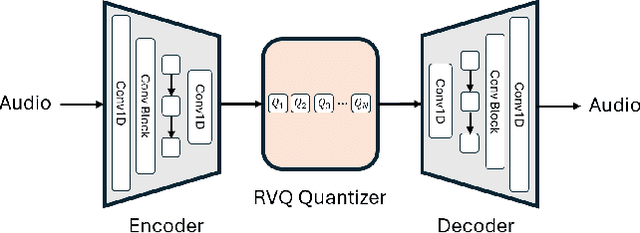

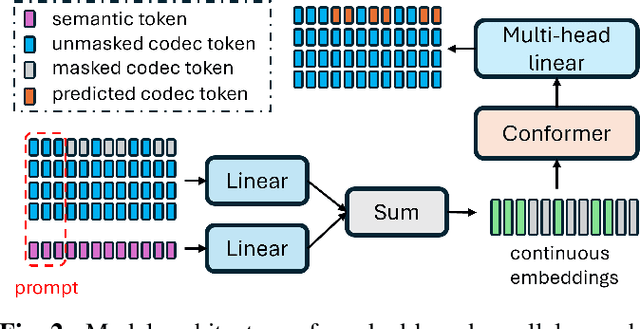
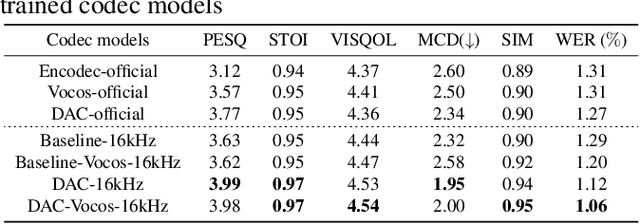
Neural audio codec tokens serve as the fundamental building blocks for speech language model (SLM)-based speech generation. However, there is no systematic understanding on how the codec system affects the speech generation performance of the SLM. In this work, we examine codec tokens within SLM framework for speech generation to provide insights for effective codec design. We retrain existing high-performing neural codec models on the same data set and loss functions to compare their performance in a uniform setting. We integrate codec tokens into two SLM systems: masked-based parallel speech generation system and an auto-regressive (AR) plus non-auto-regressive (NAR) model-based system. Our findings indicate that better speech reconstruction in codec systems does not guarantee improved speech generation in SLM. A high-quality codec decoder is crucial for natural speech production in SLM, while speech intelligibility depends more on quantization mechanism.
TransVIP: Speech to Speech Translation System with Voice and Isochrony Preservation
May 28, 2024There is a rising interest and trend in research towards directly translating speech from one language to another, known as end-to-end speech-to-speech translation. However, most end-to-end models struggle to outperform cascade models, i.e., a pipeline framework by concatenating speech recognition, machine translation and text-to-speech models. The primary challenges stem from the inherent complexities involved in direct translation tasks and the scarcity of data. In this study, we introduce a novel model framework TransVIP that leverages diverse datasets in a cascade fashion yet facilitates end-to-end inference through joint probability. Furthermore, we propose two separated encoders to preserve the speaker's voice characteristics and isochrony from the source speech during the translation process, making it highly suitable for scenarios such as video dubbing. Our experiments on the French-English language pair demonstrate that our model outperforms the current state-of-the-art speech-to-speech translation model.
CoVoMix: Advancing Zero-Shot Speech Generation for Human-like Multi-talker Conversations
Apr 10, 2024



Recent advancements in zero-shot text-to-speech (TTS) modeling have led to significant strides in generating high-fidelity and diverse speech. However, dialogue generation, along with achieving human-like naturalness in speech, continues to be a challenge in the field. In this paper, we introduce CoVoMix: Conversational Voice Mixture Generation, a novel model for zero-shot, human-like, multi-speaker, multi-round dialogue speech generation. CoVoMix is capable of first converting dialogue text into multiple streams of discrete tokens, with each token stream representing semantic information for individual talkers. These token streams are then fed into a flow-matching based acoustic model to generate mixed mel-spectrograms. Finally, the speech waveforms are produced using a HiFi-GAN model. Furthermore, we devise a comprehensive set of metrics for measuring the effectiveness of dialogue modeling and generation. Our experimental results show that CoVoMix can generate dialogues that are not only human-like in their naturalness and coherence but also involve multiple talkers engaging in multiple rounds of conversation. These dialogues, generated within a single channel, are characterized by seamless speech transitions, including overlapping speech, and appropriate paralinguistic behaviors such as laughter. Audio samples are available at https://aka.ms/covomix.
Profile-Error-Tolerant Target-Speaker Voice Activity Detection
Sep 21, 2023Target-Speaker Voice Activity Detection (TS-VAD) utilizes a set of speaker profiles alongside an input audio signal to perform speaker diarization. While its superiority over conventional methods has been demonstrated, the method can suffer from errors in speaker profiles, as those profiles are typically obtained by running a traditional clustering-based diarization method over the input signal. This paper proposes an extension to TS-VAD, called Profile-Error-Tolerant TS-VAD (PET-TSVAD), which is robust to such speaker profile errors. This is achieved by employing transformer-based TS-VAD that can handle a variable number of speakers and further introducing a set of additional pseudo-speaker profiles to handle speakers undetected during the first pass diarization. During training, we use speaker profiles estimated by multiple different clustering algorithms to reduce the mismatch between the training and testing conditions regarding speaker profiles. Experimental results show that PET-TSVAD consistently outperforms the existing TS-VAD method on both the VoxConverse and DIHARD-I datasets.
Single-channel speech separation using Soft-minimum Permutation Invariant Training
Nov 16, 2021

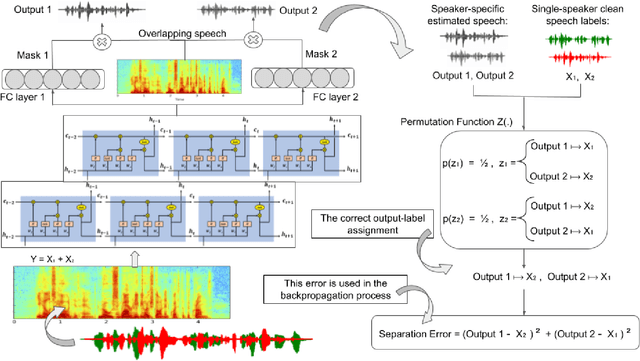

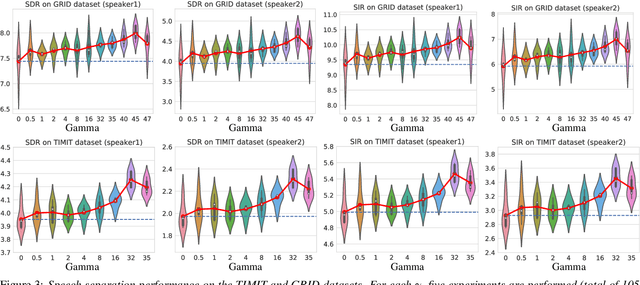
The goal of speech separation is to extract multiple speech sources from a single microphone recording. Recently, with the advancement of deep learning and availability of large datasets, speech separation has been formulated as a supervised learning problem. These approaches aim to learn discriminative patterns of speech, speakers, and background noise using a supervised learning algorithm, typically a deep neural network. A long-lasting problem in supervised speech separation is finding the correct label for each separated speech signal, referred to as label permutation ambiguity. Permutation ambiguity refers to the problem of determining the output-label assignment between the separated sources and the available single-speaker speech labels. Finding the best output-label assignment is required for calculation of separation error, which is later used for updating parameters of the model. Recently, Permutation Invariant Training (PIT) has been shown to be a promising solution in handling the label ambiguity problem. However, the overconfident choice of the output-label assignment by PIT results in a sub-optimal trained model. In this work, we propose a probabilistic optimization framework to address the inefficiency of PIT in finding the best output-label assignment. Our proposed method entitled trainable Soft-minimum PIT is then employed on the same Long-Short Term Memory (LSTM) architecture used in Permutation Invariant Training (PIT) speech separation method. The results of our experiments show that the proposed method outperforms conventional PIT speech separation significantly (p-value $ < 0.01$) by +1dB in Signal to Distortion Ratio (SDR) and +1.5dB in Signal to Interference Ratio (SIR).
Speaker conditioning of acoustic models using affine transformation for multi-speaker speech recognition
Oct 30, 2021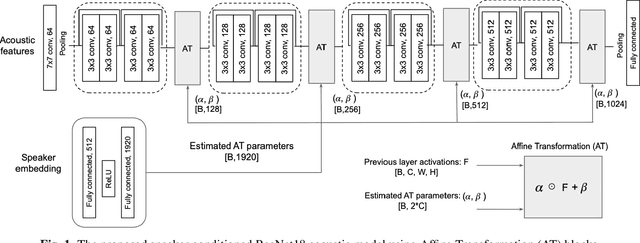

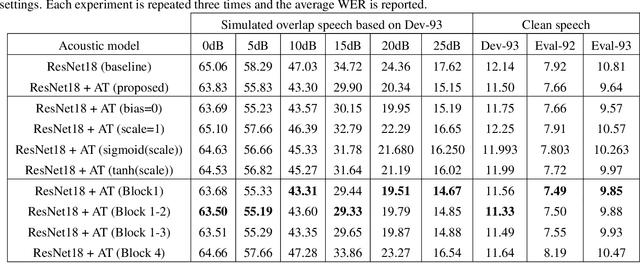
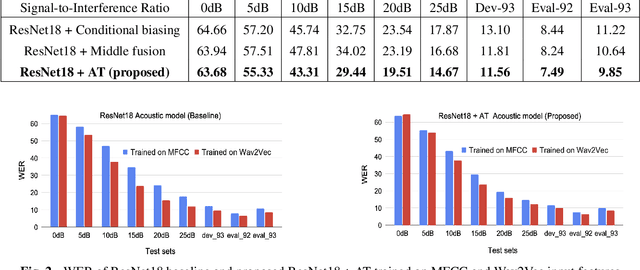
This study addresses the problem of single-channel Automatic Speech Recognition of a target speaker within an overlap speech scenario. In the proposed method, the hidden representations in the acoustic model are modulated by speaker auxiliary information to recognize only the desired speaker. Affine transformation layers are inserted into the acoustic model network to integrate speaker information with the acoustic features. The speaker conditioning process allows the acoustic model to perform computation in the context of target-speaker auxiliary information. The proposed speaker conditioning method is a general approach and can be applied to any acoustic model architecture. Here, we employ speaker conditioning on a ResNet acoustic model. Experiments on the WSJ corpus show that the proposed speaker conditioning method is an effective solution to fuse speaker auxiliary information with acoustic features for multi-speaker speech recognition, achieving +9% and +20% relative WER reduction for clean and overlap speech scenarios, respectively, compared to the original ResNet acoustic model baseline.
Real-time Speaker counting in a cocktail party scenario using Attention-guided Convolutional Neural Network
Oct 30, 2021
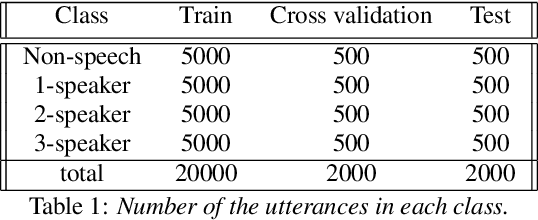
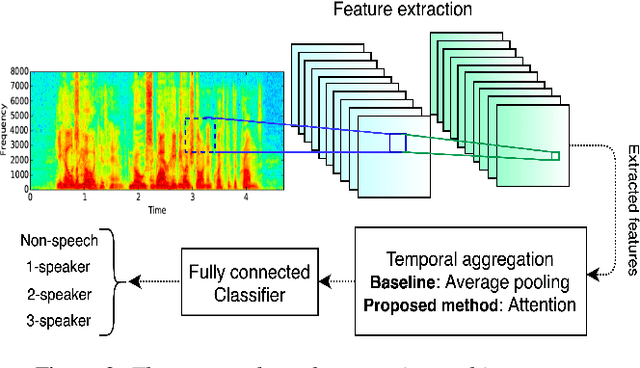

Most current speech technology systems are designed to operate well even in the presence of multiple active speakers. However, most solutions assume that the number of co-current speakers is known. Unfortunately, this information might not always be available in real-world applications. In this study, we propose a real-time, single-channel attention-guided Convolutional Neural Network (CNN) to estimate the number of active speakers in overlapping speech. The proposed system extracts higher-level information from the speech spectral content using a CNN model. Next, the attention mechanism summarizes the extracted information into a compact feature vector without losing critical information. Finally, the active speakers are classified using a fully connected network. Experiments on simulated overlapping speech using WSJ corpus show that the attention solution is shown to improve the performance by almost 3% absolute over conventional temporal average pooling. The proposed Attention-guided CNN achieves 76.15% for both Weighted Accuracy and average Recall, and 75.80% Precision on speech segments as short as 20 frames (i.e., 200 ms). All the classification metrics exceed 92% for the attention-guided model in offline scenarios where the input signal is more than 100 frames long (i.e., 1s).
Probabilistic Permutation Invariant Training for Speech Separation
Aug 04, 2019
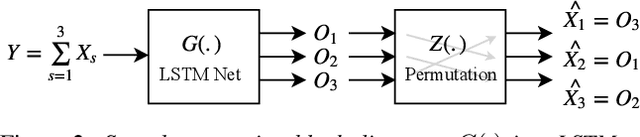
Single-microphone, speaker-independent speech separation is normally performed through two steps: (i) separating the specific speech sources, and (ii) determining the best output-label assignment to find the separation error. The second step is the main obstacle in training neural networks for speech separation. Recently proposed Permutation Invariant Training (PIT) addresses this problem by determining the output-label assignment which minimizes the separation error. In this study, we show that a major drawback of this technique is the overconfident choice of the output-label assignment, especially in the initial steps of training when the network generates unreliable outputs. To solve this problem, we propose Probabilistic PIT (Prob-PIT) which considers the output-label permutation as a discrete latent random variable with a uniform prior distribution. Prob-PIT defines a log-likelihood function based on the prior distributions and the separation errors of all permutations; it trains the speech separation networks by maximizing the log-likelihood function. Prob-PIT can be easily implemented by replacing the minimum function of PIT with a soft-minimum function. We evaluate our approach for speech separation on both TIMIT and CHiME datasets. The results show that the proposed method significantly outperforms PIT in terms of Signal to Distortion Ratio and Signal to Interference Ratio.