 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClustering and Mining Accented Speech for Inclusive and Fair Speech Recognition
Aug 05, 2024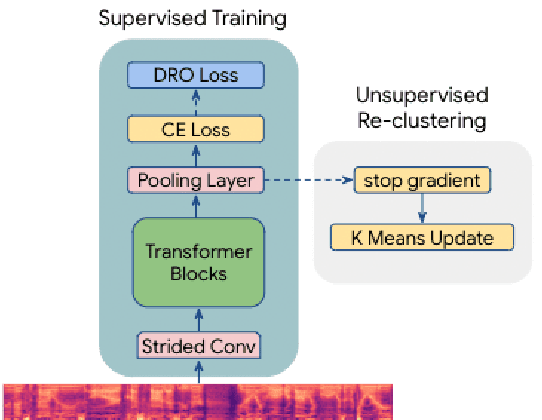
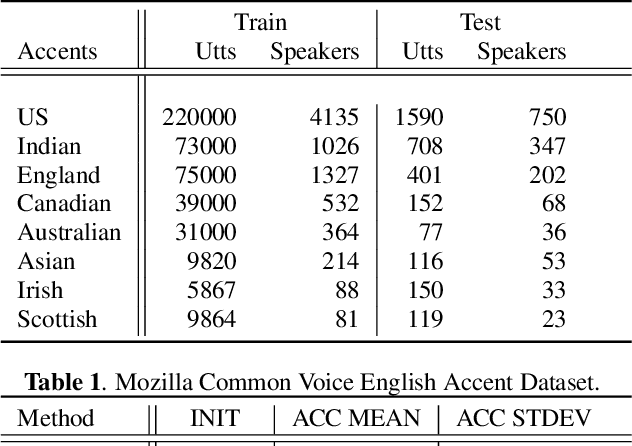
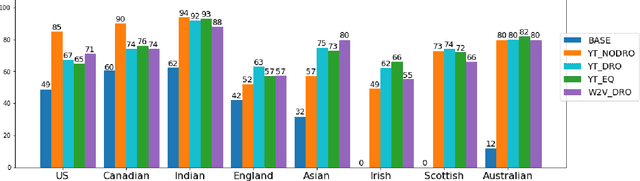

Modern automatic speech recognition (ASR) systems are typically trained on more than tens of thousands hours of speech data, which is one of the main factors for their great success. However, the distribution of such data is typically biased towards common accents or typical speech patterns. As a result, those systems often poorly perform on atypical accented speech. In this paper, we present accent clustering and mining schemes for fair speech recognition systems which can perform equally well on under-represented accented speech. For accent recognition, we applied three schemes to overcome limited size of supervised accent data: supervised or unsupervised pre-training, distributionally robust optimization (DRO) and unsupervised clustering. Three schemes can significantly improve the accent recognition model especially for unbalanced and small accented speech. Fine-tuning ASR on the mined Indian accent speech using the proposed supervised or unsupervised clustering schemes showed 10.0% and 5.3% relative improvements compared to fine-tuning on the randomly sampled speech, respectively.
Contrastive Siamese Network for Semi-supervised Speech Recognition
May 27, 2022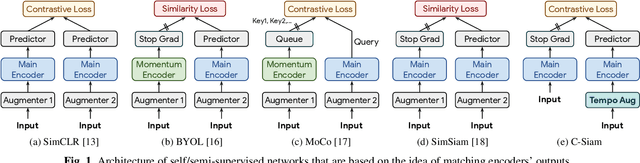
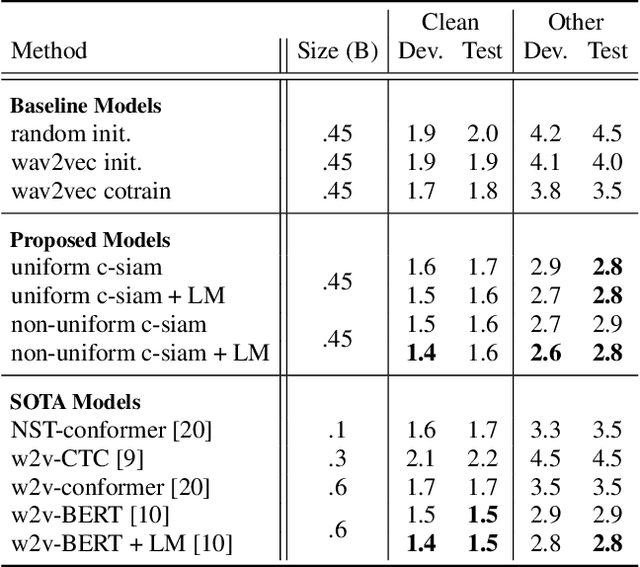
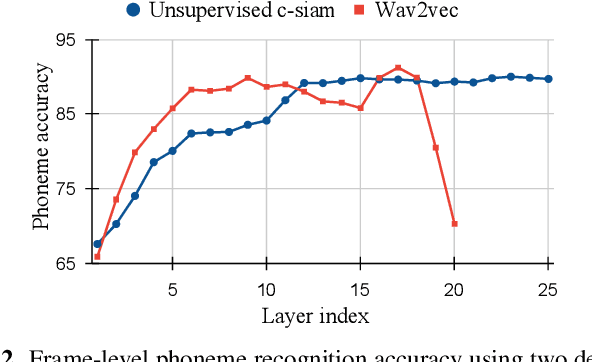
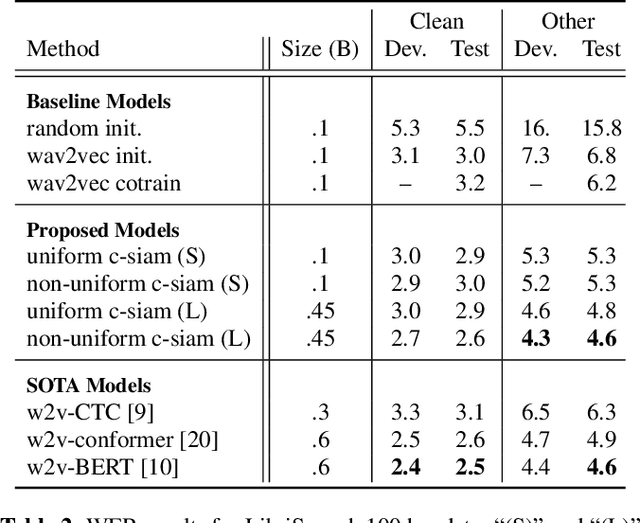
This paper introduces contrastive siamese (c-siam) network, an architecture for leveraging unlabeled acoustic data in speech recognition. c-siam is the first network that extracts high-level linguistic information from speech by matching outputs of two identical transformer encoders. It contains augmented and target branches which are trained by: (1) masking inputs and matching outputs with a contrastive loss, (2) incorporating a stop gradient operation on the target branch, (3) using an extra learnable transformation on the augmented branch, (4) introducing new temporal augment functions to prevent the shortcut learning problem. We use the Libri-light 60k unsupervised data and the LibriSpeech 100hrs/960hrs supervised data to compare c-siam and other best-performing systems. Our experiments show that c-siam provides 20% relative word error rate improvement over wav2vec baselines. A c-siam network with 450M parameters achieves competitive results compared to the state-of-the-art networks with 600M parameters.
Analyzing Large Receptive Field Convolutional Networks for Distant Speech Recognition
Oct 15, 2019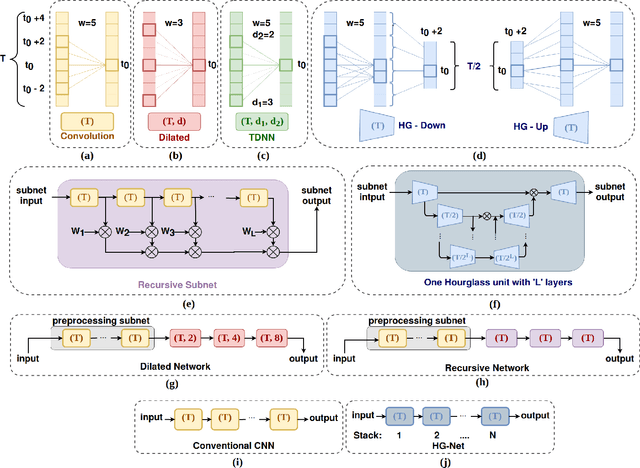
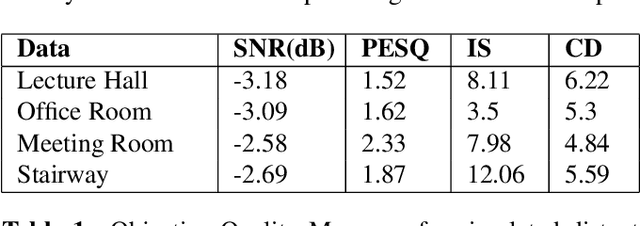
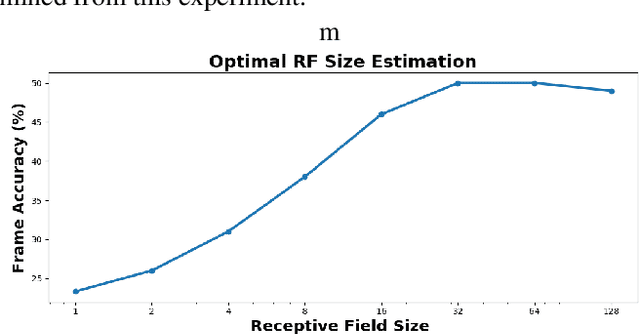
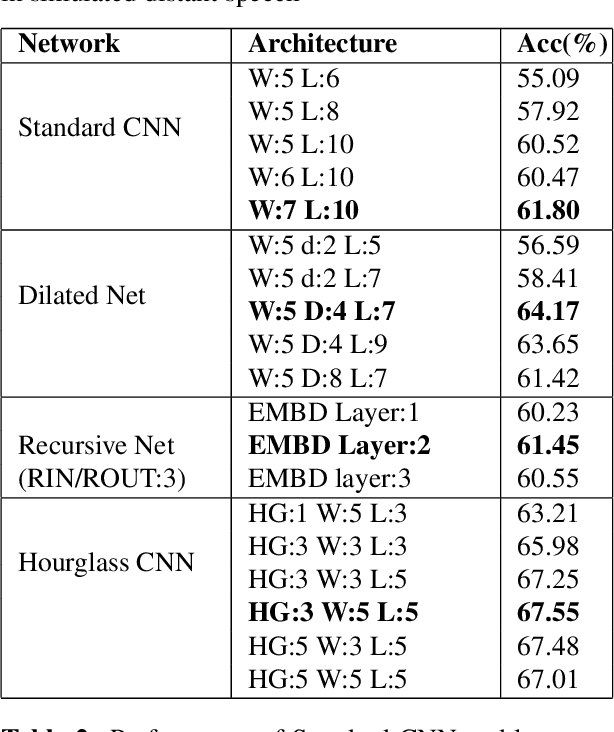
Despite significant efforts over the last few years to build a robust automatic speech recognition (ASR) system for different acoustic settings, the performance of the current state-of-the-art technologies significantly degrades in noisy reverberant environments. Convolutional Neural Networks (CNNs) have been successfully used to achieve substantial improvements in many speech processing applications including distant speech recognition (DSR). However, standard CNN architectures were not efficient in capturing long-term speech dynamics, which are essential in the design of a robust DSR system. In the present study, we address this issue by investigating variants of large receptive field CNNs (LRF-CNNs) which include deeply recursive networks, dilated convolutional neural networks, and stacked hourglass networks. To compare the efficacy of the aforementioned architectures with the standard CNN for Wall Street Journal (WSJ) corpus, we use a hybrid DNN-HMM based speech recognition system. We extend the study to evaluate the system performances for distant speech simulated using realistic room impulse responses (RIRs). Our experiments show that with fixed number of parameters across all architectures, the large receptive field networks show consistent improvements over the standard CNNs for distant speech. Amongst the explored LRF-CNNs, stacked hourglass network has shown improvements with a 8.9% relative reduction in word error rate (WER) and 10.7% relative improvement in frame accuracy compared to the standard CNNs for distant simulated speech signals.
Domain Expansion in DNN-based Acoustic Models for Robust Speech Recognition
Oct 01, 2019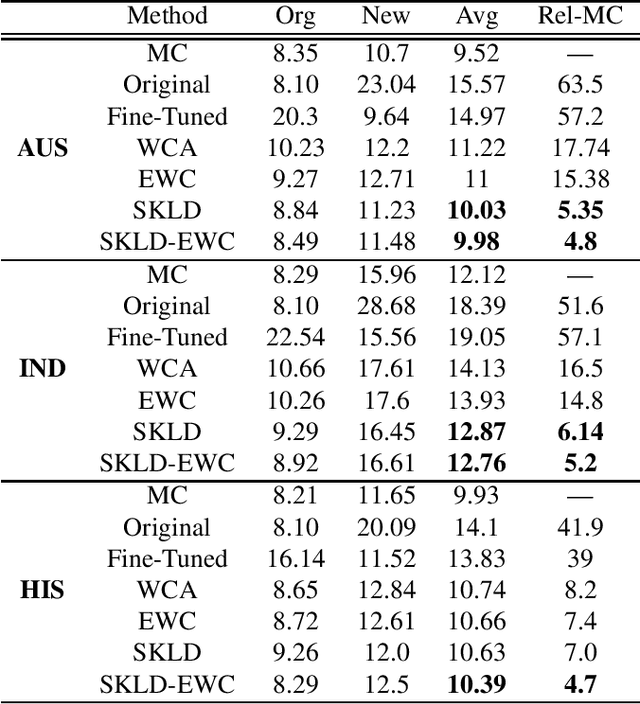

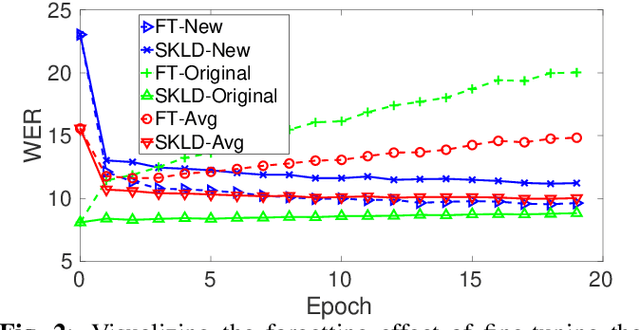
Training acoustic models with sequentially incoming data -- while both leveraging new data and avoiding the forgetting effect-- is an essential obstacle to achieving human intelligence level in speech recognition. An obvious approach to leverage data from a new domain (e.g., new accented speech) is to first generate a comprehensive dataset of all domains, by combining all available data, and then use this dataset to retrain the acoustic models. However, as the amount of training data grows, storing and retraining on such a large-scale dataset becomes practically impossible. To deal with this problem, in this study, we study several domain expansion techniques which exploit only the data of the new domain to build a stronger model for all domains. These techniques are aimed at learning the new domain with a minimal forgetting effect (i.e., they maintain original model performance). These techniques modify the adaptation procedure by imposing new constraints including (1) weight constraint adaptation (WCA): keeping the model parameters close to the original model parameters; (2) elastic weight consolidation (EWC): slowing down training for parameters that are important for previously established domains; (3) soft KL-divergence (SKLD): restricting the KL-divergence between the original and the adapted model output distributions; and (4) hybrid SKLD-EWC: incorporating both SKLD and EWC constraints. We evaluate these techniques in an accent adaptation task in which we adapt a deep neural network (DNN) acoustic model trained with native English to three different English accents: Australian, Hispanic, and Indian. The experimental results show that SKLD significantly outperforms EWC, and EWC works better than WCA. The hybrid SKLD-EWC technique results in the best overall performance.
Probabilistic Permutation Invariant Training for Speech Separation
Aug 04, 2019
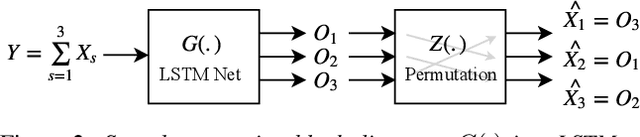
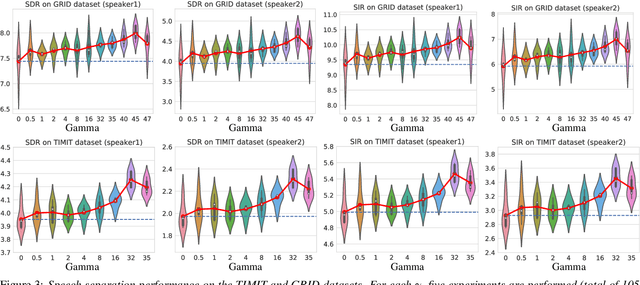
Single-microphone, speaker-independent speech separation is normally performed through two steps: (i) separating the specific speech sources, and (ii) determining the best output-label assignment to find the separation error. The second step is the main obstacle in training neural networks for speech separation. Recently proposed Permutation Invariant Training (PIT) addresses this problem by determining the output-label assignment which minimizes the separation error. In this study, we show that a major drawback of this technique is the overconfident choice of the output-label assignment, especially in the initial steps of training when the network generates unreliable outputs. To solve this problem, we propose Probabilistic PIT (Prob-PIT) which considers the output-label permutation as a discrete latent random variable with a uniform prior distribution. Prob-PIT defines a log-likelihood function based on the prior distributions and the separation errors of all permutations; it trains the speech separation networks by maximizing the log-likelihood function. Prob-PIT can be easily implemented by replacing the minimum function of PIT with a soft-minimum function. We evaluate our approach for speech separation on both TIMIT and CHiME datasets. The results show that the proposed method significantly outperforms PIT in terms of Signal to Distortion Ratio and Signal to Interference Ratio.
Jointly Aligning and Predicting Continuous Emotion Annotations
Jul 18, 2019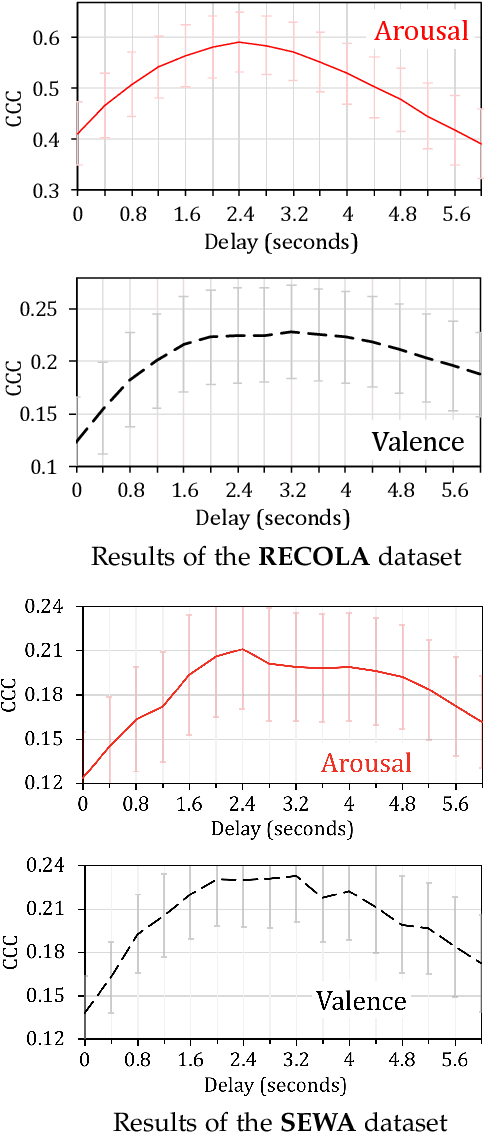
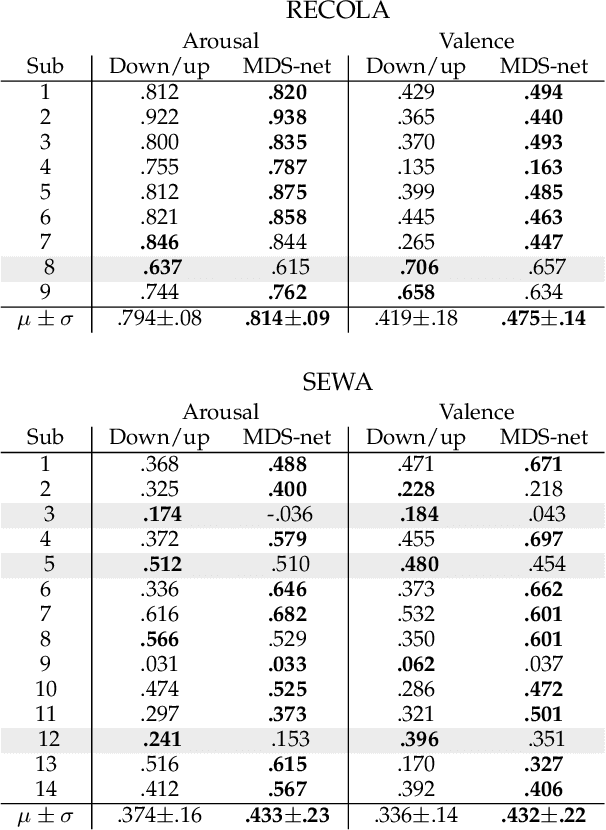
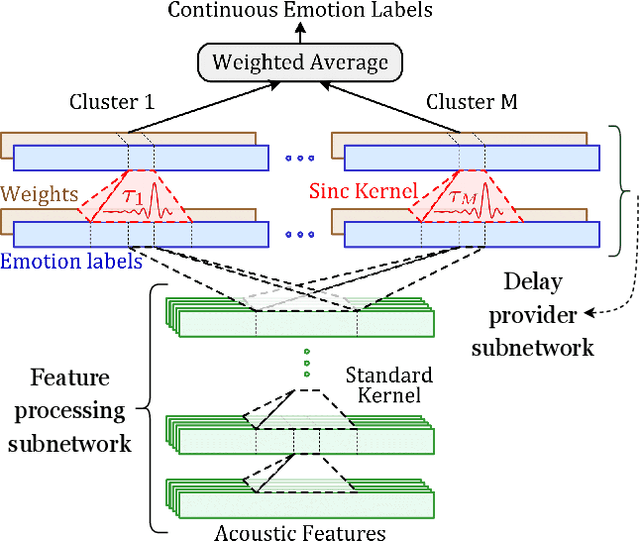
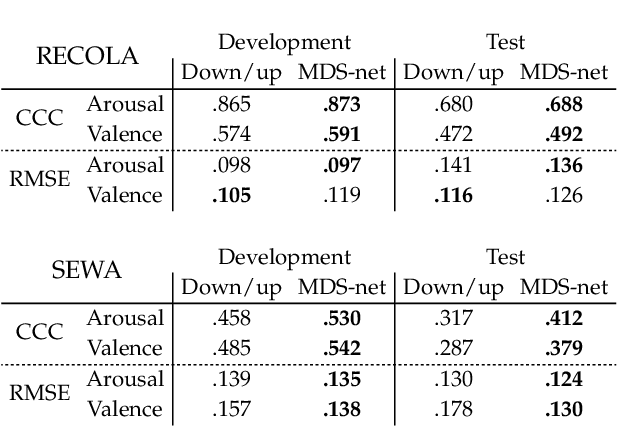
Time-continuous dimensional descriptions of emotions (e.g., arousal, valence) allow researchers to characterize short-time changes and to capture long-term trends in emotion expression. However, continuous emotion labels are generally not synchronized with the input speech signal due to delays caused by reaction-time, which is inherent in human evaluations. To deal with this challenge, we introduce a new convolutional neural network (multi-delay sinc network) that is able to simultaneously align and predict labels in an end-to-end manner. The proposed network is a stack of convolutional layers followed by an aligner network that aligns the speech signal and emotion labels. This network is implemented using a new convolutional layer that we introduce, the delayed sinc layer. It is a time-shifted low-pass (sinc) filter that uses a gradient-based algorithm to learn a single delay. Multiple delayed sinc layers can be used to compensate for a non-stationary delay that is a function of the acoustic space. We test the efficacy of this system on two common emotion datasets, RECOLA and SEWA, and show that this approach obtains state-of-the-art speech-only results by learning time-varying delays while predicting dimensional descriptors of emotions.
Convolutional Neural Network-based Speech Enhancement for Cochlear Implant Recipients
Jul 03, 2019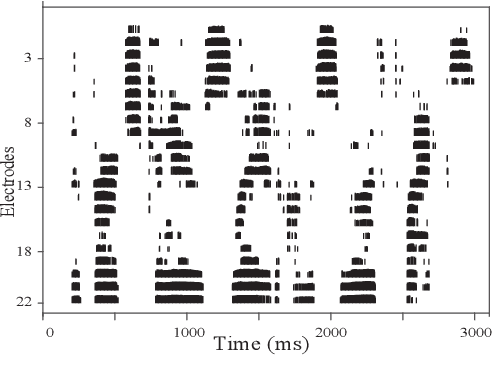
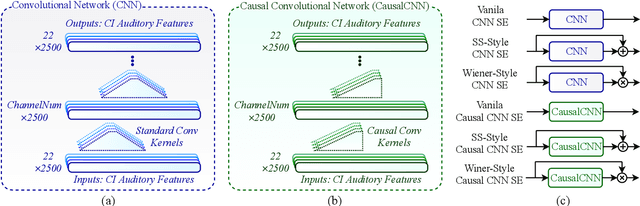
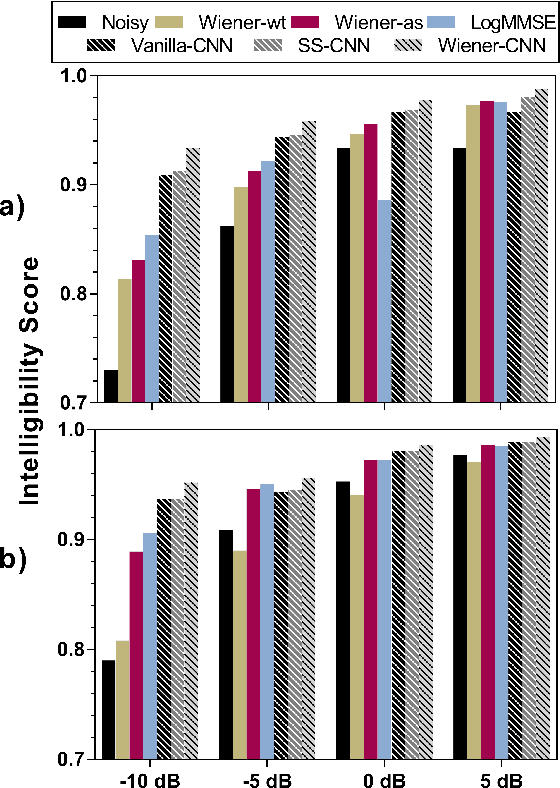
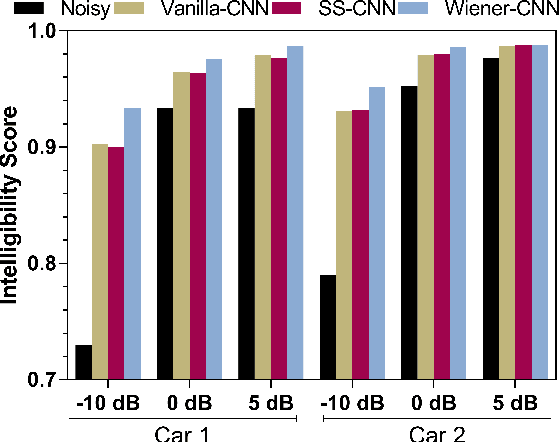
Attempts to develop speech enhancement algorithms with improved speech intelligibility for cochlear implant (CI) users have met with limited success. To improve speech enhancement methods for CI users, we propose to perform speech enhancement in a cochlear filter-bank feature space, a feature-set specifically designed for CI users based on CI auditory stimuli. We leverage a convolutional neural network (CNN) to extract both stationary and non-stationary components of environmental acoustics and speech. We propose three CNN architectures: (1) vanilla CNN that directly generates the enhanced signal; (2) spectral-subtraction-style CNN (SS-CNN) that first predicts noise and then generates the enhanced signal by subtracting noise from the noisy signal; (3) Wiener-style CNN (Wiener-CNN) that generates an optimal mask for suppressing noise. An important problem of the proposed networks is that they introduce considerable delays, which limits their real-time application for CI users. To address this, this study also considers causal variations of these networks. Our experiments show that the proposed networks (both causal and non-causal forms) achieve significant improvement over existing baseline systems. We also found that causal Wiener-CNN outperforms other networks, and leads to the best overall envelope coefficient measure (ECM). The proposed algorithms represent a viable option for implementation on the CCi-MOBILE research platform as a pre-processor for CI users in naturalistic environments.
Trainable Time Warping: Aligning Time-Series in the Continuous-Time Domain
Mar 21, 2019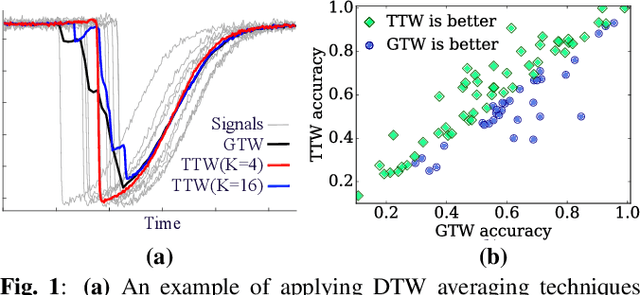
DTW calculates the similarity or alignment between two signals, subject to temporal warping. However, its computational complexity grows exponentially with the number of time-series. Although there have been algorithms developed that are linear in the number of time-series, they are generally quadratic in time-series length. The exception is generalized time warping (GTW), which has linear computational cost. Yet, it can only identify simple time warping functions. There is a need for a new fast, high-quality multisequence alignment algorithm. We introduce trainable time warping (TTW), whose complexity is linear in both the number and the length of time-series. TTW performs alignment in the continuous-time domain using a sinc convolutional kernel and a gradient-based optimization technique. We compare TTW and GTW on 85 UCR datasets in time-series averaging and classification. TTW outperforms GTW on 67.1% of the datasets for the averaging tasks, and 61.2% of the datasets for the classification tasks.
Capturing Long-term Temporal Dependencies with Convolutional Networks for Continuous Emotion Recognition
Aug 23, 2017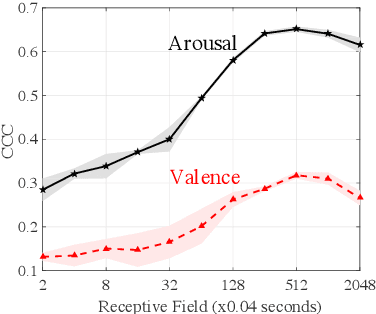
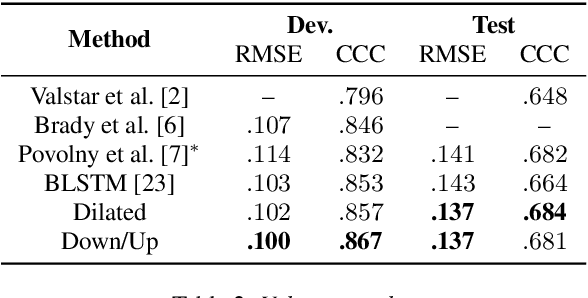
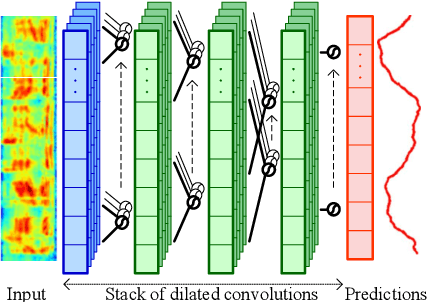
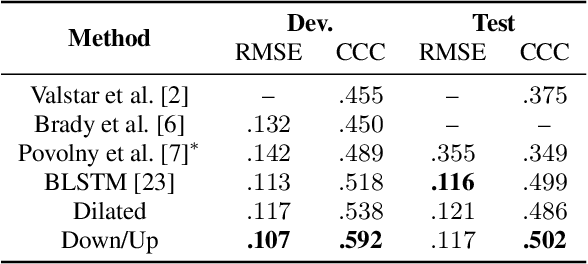
The goal of continuous emotion recognition is to assign an emotion value to every frame in a sequence of acoustic features. We show that incorporating long-term temporal dependencies is critical for continuous emotion recognition tasks. To this end, we first investigate architectures that use dilated convolutions. We show that even though such architectures outperform previously reported systems, the output signals produced from such architectures undergo erratic changes between consecutive time steps. This is inconsistent with the slow moving ground-truth emotion labels that are obtained from human annotators. To deal with this problem, we model a downsampled version of the input signal and then generate the output signal through upsampling. Not only does the resulting downsampling/upsampling network achieve good performance, it also generates smooth output trajectories. Our method yields the best known audio-only performance on the RECOLA dataset.
Progressive Neural Networks for Transfer Learning in Emotion Recognition
Jun 10, 2017

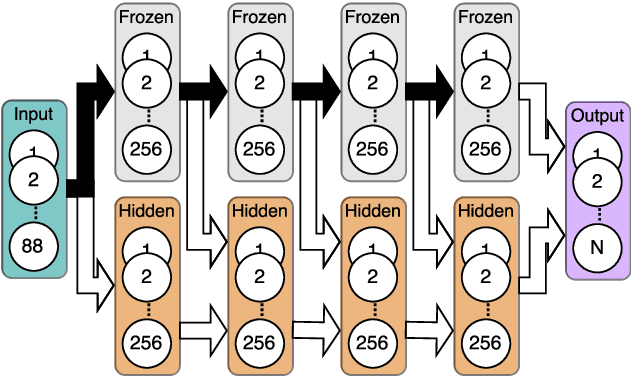
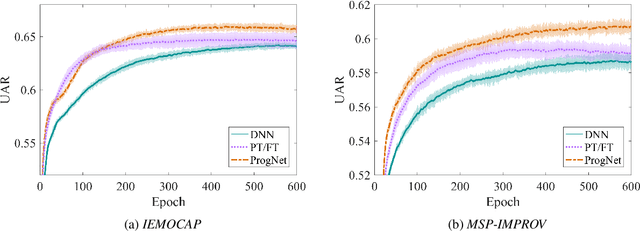
Many paralinguistic tasks are closely related and thus representations learned in one domain can be leveraged for another. In this paper, we investigate how knowledge can be transferred between three paralinguistic tasks: speaker, emotion, and gender recognition. Further, we extend this problem to cross-dataset tasks, asking how knowledge captured in one emotion dataset can be transferred to another. We focus on progressive neural networks and compare these networks to the conventional deep learning method of pre-training and fine-tuning. Progressive neural networks provide a way to transfer knowledge and avoid the forgetting effect present when pre-training neural networks on different tasks. Our experiments demonstrate that: (1) emotion recognition can benefit from using representations originally learned for different paralinguistic tasks and (2) transfer learning can effectively leverage additional datasets to improve the performance of emotion recognition systems.