 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Variational Framework for Improving Naturalness in Generative Spoken Language Models
Jun 17, 2025



The success of large language models in text processing has inspired their adaptation to speech modeling. However, since speech is continuous and complex, it is often discretized for autoregressive modeling. Speech tokens derived from self-supervised models (known as semantic tokens) typically focus on the linguistic aspects of speech but neglect prosodic information. As a result, models trained on these tokens can generate speech with reduced naturalness. Existing approaches try to fix this by adding pitch features to the semantic tokens. However, pitch alone cannot fully represent the range of paralinguistic attributes, and selecting the right features requires careful hand-engineering. To overcome this, we propose an end-to-end variational approach that automatically learns to encode these continuous speech attributes to enhance the semantic tokens. Our approach eliminates the need for manual extraction and selection of paralinguistic features. Moreover, it produces preferred speech continuations according to human raters. Code, samples and models are available at https://github.com/b04901014/vae-gslm.
Visatronic: A Multimodal Decoder-Only Model for Speech Synthesis
Nov 26, 2024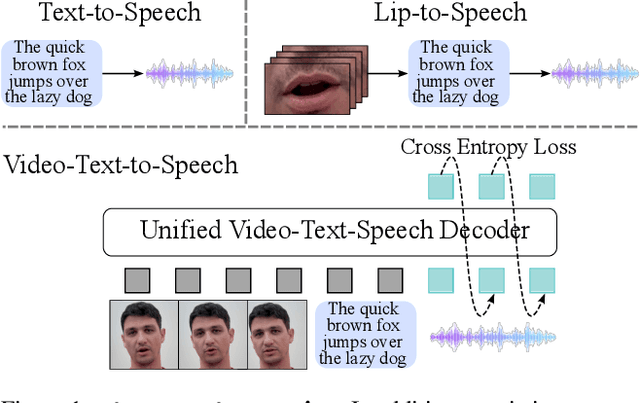



In this paper, we propose a new task -- generating speech from videos of people and their transcripts (VTTS) -- to motivate new techniques for multimodal speech generation. This task generalizes the task of generating speech from cropped lip videos, and is also more complicated than the task of generating generic audio clips (e.g., dog barking) from videos and text. Multilingual versions of the task could lead to new techniques for cross-lingual dubbing. We also present a decoder-only multimodal model for this task, which we call Visatronic. This model embeds vision, text and speech directly into the common subspace of a transformer model and uses an autoregressive loss to learn a generative model of discretized mel-spectrograms conditioned on speaker videos and transcripts of their speech. By embedding all modalities into a common subspace, Visatronic can achieve improved results over models that use only text or video as input. Further, it presents a much simpler approach for multimodal speech generation compared to prevailing approaches which rely on lip-detectors and complicated architectures to fuse modalities while producing better results. Since the model is flexible enough to accommodate different ways of ordering inputs as a sequence, we carefully explore different strategies to better understand the best way to propagate information to the generative steps. To facilitate further research on VTTS, we will release (i) our code, (ii) clean transcriptions for the large-scale VoxCeleb2 dataset, and (iii) a standardized evaluation protocol for VTTS incorporating both objective and subjective metrics.
Learning Spatially-Aware Language and Audio Embedding
Sep 17, 2024



Humans can picture a sound scene given an imprecise natural language description. For example, it is easy to imagine an acoustic environment given a phrase like "the lion roar came from right behind me!". For a machine to have the same degree of comprehension, the machine must know what a lion is (semantic attribute), what the concept of "behind" is (spatial attribute) and how these pieces of linguistic information align with the semantic and spatial attributes of the sound (what a roar sounds like when its coming from behind). State-of-the-art audio foundation models which learn to map between audio scenes and natural textual descriptions, are trained on non-spatial audio and text pairs, and hence lack spatial awareness. In contrast, sound event localization and detection models are limited to recognizing sounds from a fixed number of classes, and they localize the source to absolute position (e.g., 0.2m) rather than a position described using natural language (e.g., "next to me"). To address these gaps, we present ELSA a spatially aware-audio and text embedding model trained using multimodal contrastive learning. ELSA supports non-spatial audio, spatial audio, and open vocabulary text captions describing both the spatial and semantic components of sound. To train ELSA: (a) we spatially augment the audio and captions of three open-source audio datasets totaling 4,738 hours of audio, and (b) we design an encoder to capture the semantics of non-spatial audio, and the semantics and spatial attributes of spatial audio using contrastive learning. ELSA is competitive with state-of-the-art for both semantic retrieval and 3D source localization. In particular, ELSA achieves +2.8% mean audio-to-text and text-to-audio R@1 above the baseline, and outperforms by -11.6{\deg} mean-absolute-error in 3D source localization over the baseline.
Speaker-IPL: Unsupervised Learning of Speaker Characteristics with i-Vector based Pseudo-Labels
Sep 16, 2024



Iterative self-training, or iterative pseudo-labeling (IPL)--using an improved model from the current iteration to provide pseudo-labels for the next iteration--has proven to be a powerful approach to enhance the quality of speaker representations. Recent applications of IPL in unsupervised speaker recognition start with representations extracted from very elaborate self-supervised methods (e.g., DINO). However, training such strong self-supervised models is not straightforward (they require hyper-parameters tuning and may not generalize to out-of-domain data) and, moreover, may not be needed at all. To this end, we show the simple, well-studied, and established i-vector generative model is enough to bootstrap the IPL process for unsupervised learning of speaker representations. We also systematically study the impact of other components on the IPL process, which includes the initial model, the encoder, augmentations, the number of clusters, and the clustering algorithm. Remarkably, we find that even with a simple and significantly weaker initial model like i-vector, IPL can still achieve speaker verification performance that rivals state-of-the-art methods.
Exploring Prediction Targets in Masked Pre-Training for Speech Foundation Models
Sep 16, 2024



Speech foundation models, such as HuBERT and its variants, are pre-trained on large amounts of unlabeled speech for various downstream tasks. These models use a masked prediction objective, where the model learns to predict information about masked input segments from the unmasked context. The choice of prediction targets in this framework can influence performance on downstream tasks. For example, targets that encode prosody are beneficial for speaker-related tasks, while targets that encode phonetics are more suited for content-related tasks. Additionally, prediction targets can vary in the level of detail they encode; targets that encode fine-grained acoustic details are beneficial for denoising tasks, while targets that encode higher-level abstractions are more suited for content-related tasks. Despite the importance of prediction targets, the design choices that affect them have not been thoroughly studied. This work explores the design choices and their impact on downstream task performance. Our results indicate that the commonly used design choices for HuBERT can be suboptimal. We propose novel approaches to create more informative prediction targets and demonstrate their effectiveness through improvements across various downstream tasks.
Towards Automatic Assessment of Self-Supervised Speech Models using Rank
Sep 16, 2024


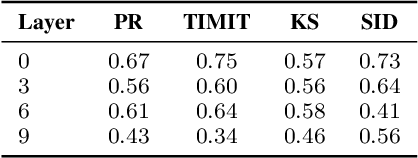
This study explores using embedding rank as an unsupervised evaluation metric for general-purpose speech encoders trained via self-supervised learning (SSL). Traditionally, assessing the performance of these encoders is resource-intensive and requires labeled data from the downstream tasks. Inspired by the vision domain, where embedding rank has shown promise for evaluating image encoders without tuning on labeled downstream data, this work examines its applicability in the speech domain, considering the temporal nature of the signals. The findings indicate rank correlates with downstream performance within encoder layers across various downstream tasks and for in- and out-of-domain scenarios. However, rank does not reliably predict the best-performing layer for specific downstream tasks, as lower-ranked layers can outperform higher-ranked ones. Despite this limitation, the results suggest that embedding rank can be a valuable tool for monitoring training progress in SSL speech models, offering a less resource-demanding alternative to traditional evaluation methods.
dMel: Speech Tokenization made Simple
Jul 22, 2024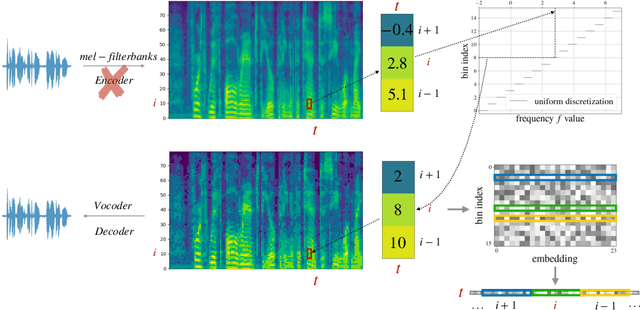

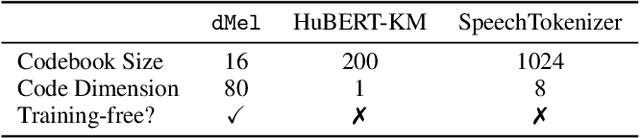
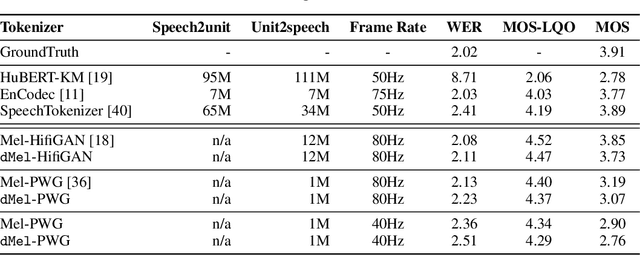
Large language models have revolutionized natural language processing by leveraging self-supervised pretraining on vast textual data. Inspired by this success, researchers have investigated complicated speech tokenization methods to discretize continuous speech signals so that language modeling techniques can be applied to speech data. However, existing approaches either model semantic tokens, potentially losing acoustic information, or model acoustic tokens, risking the loss of semantic information. Having multiple token types also complicates the architecture and requires additional pretraining. Here we show that discretizing mel-filterbank channels into discrete intensity bins produces a simple representation (dMel), that performs better than other existing speech tokenization methods. Using a transformer decoder-only architecture for speech-text modeling, we comprehensively evaluate different speech tokenization methods on speech recognition (ASR), speech synthesis (TTS). Our results demonstrate the effectiveness of dMel in achieving high performance on both tasks within a unified framework, paving the way for efficient and effective joint modeling of speech and text.
Can you Remove the Downstream Model for Speaker Recognition with Self-Supervised Speech Features?
Feb 01, 2024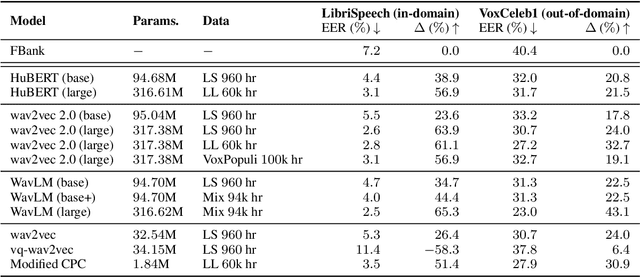
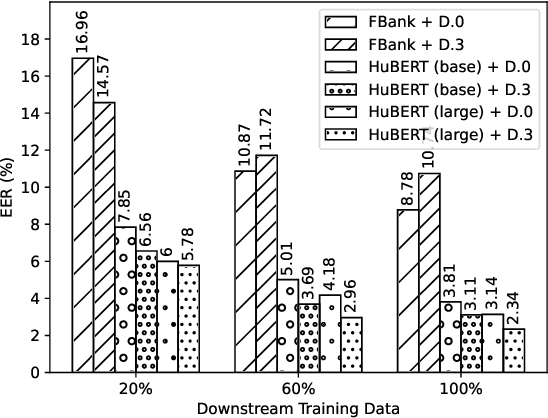

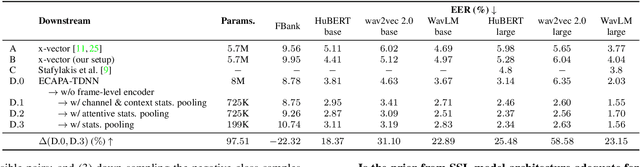
Self-supervised features are typically used in place of filter-banks in speaker verification models. However, these models were originally designed to ingest filter-banks as inputs, and thus, training them on top of self-supervised features assumes that both feature types require the same amount of learning for the task. In this work, we observe that pre-trained self-supervised speech features inherently include information required for downstream speaker verification task, and therefore, we can simplify the downstream model without sacrificing performance. To this end, we revisit the design of the downstream model for speaker verification using self-supervised features. We show that we can simplify the model to use 97.51% fewer parameters while achieving a 29.93% average improvement in performance on SUPERB. Consequently, we show that the simplified downstream model is more data efficient compared to baseline--it achieves better performance with only 60% of the training data.
ESPnet-SPK: full pipeline speaker embedding toolkit with reproducible recipes, self-supervised front-ends, and off-the-shelf models
Jan 30, 2024



This paper introduces ESPnet-SPK, a toolkit designed with several objectives for training speaker embedding extractors. First, we provide an open-source platform for researchers in the speaker recognition community to effortlessly build models. We provide several models, ranging from x-vector to recent SKA-TDNN. Through the modularized architecture design, variants can be developed easily. We also aspire to bridge developed models with other domains, facilitating the broad research community to effortlessly incorporate state-of-the-art embedding extractors. Pre-trained embedding extractors can be accessed in an off-the-shelf manner and we demonstrate the toolkit's versatility by showcasing its integration with two tasks. Another goal is to integrate with diverse self-supervised learning features. We release a reproducible recipe that achieves an equal error rate of 0.39% on the Vox1-O evaluation protocol using WavLM-Large with ECAPA-TDNN.
Spatial LibriSpeech: An Augmented Dataset for Spatial Audio Learning
Aug 18, 2023



We present Spatial LibriSpeech, a spatial audio dataset with over 650 hours of 19-channel audio, first-order ambisonics, and optional distractor noise. Spatial LibriSpeech is designed for machine learning model training, and it includes labels for source position, speaking direction, room acoustics and geometry. Spatial LibriSpeech is generated by augmenting LibriSpeech samples with 200k+ simulated acoustic conditions across 8k+ synthetic rooms. To demonstrate the utility of our dataset, we train models on four spatial audio tasks, resulting in a median absolute error of 6.60{\deg} on 3D source localization, 0.43m on distance, 90.66ms on T30, and 2.74dB on DRR estimation. We show that the same models generalize well to widely-used evaluation datasets, e.g., obtaining a median absolute error of 12.43{\deg} on 3D source localization on TUT Sound Events 2018, and 157.32ms on T30 estimation on ACE Challenge.