 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTG-ASR: Translation-Guided Learning with Parallel Gated Cross Attention for Low-Resource Automatic Speech Recognition
Feb 25, 2026Low-resource automatic speech recognition (ASR) continues to pose significant challenges, primarily due to the limited availability of transcribed data for numerous languages. While a wealth of spoken content is accessible in television dramas and online videos, Taiwanese Hokkien exemplifies this issue, with transcriptions often being scarce and the majority of available subtitles provided only in Mandarin. To address this deficiency, we introduce TG-ASR for Taiwanese Hokkien drama speech recognition, a translation-guided ASR framework that utilizes multilingual translation embeddings to enhance recognition performance in low-resource environments. The framework is centered around the parallel gated cross-attention (PGCA) mechanism, which adaptively integrates embeddings from various auxiliary languages into the ASR decoder. This mechanism facilitates robust cross-linguistic semantic guidance while ensuring stable optimization and minimizing interference between languages. To support ongoing research initiatives, we present YT-THDC, a 30-hour corpus of Taiwanese Hokkien drama speech with aligned Mandarin subtitles and manually verified Taiwanese Hokkien transcriptions. Comprehensive experiments and analyses identify the auxiliary languages that most effectively enhance ASR performance, achieving a 14.77% relative reduction in character error rate and demonstrating the efficacy of translation-guided learning for underrepresented languages in practical applications.
SCENE: Semantic-aware Codec Enhancement with Neural Embeddings
Jan 29, 2026Compression artifacts from standard video codecs often degrade perceptual quality. We propose a lightweight, semantic-aware pre-processing framework that enhances perceptual fidelity by selectively addressing these distortions. Our method integrates semantic embeddings from a vision-language model into an efficient convolutional architecture, prioritizing the preservation of perceptually significant structures. The model is trained end-to-end with a differentiable codec proxy, enabling it to mitigate artifacts from various standard codecs without modifying the existing video pipeline. During inference, the codec proxy is discarded, and SCENE operates as a standalone pre-processor, enabling real-time performance. Experiments on high-resolution benchmarks show improved performance over baselines in both objective (MS-SSIM) and perceptual (VMAF) metrics, with notable gains in preserving detailed textures within salient regions. Our results show that semantic-guided, codec-aware pre-processing is an effective approach for enhancing compressed video streams.
Revealing the Role of Audio Channels in ASR Performance Degradation
Aug 12, 2025
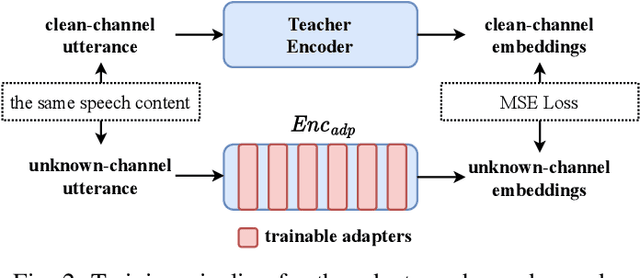


Pre-trained automatic speech recognition (ASR) models have demonstrated strong performance on a variety of tasks. However, their performance can degrade substantially when the input audio comes from different recording channels. While previous studies have demonstrated this phenomenon, it is often attributed to the mismatch between training and testing corpora. This study argues that variations in speech characteristics caused by different recording channels can fundamentally harm ASR performance. To address this limitation, we propose a normalization technique designed to mitigate the impact of channel variation by aligning internal feature representations in the ASR model with those derived from a clean reference channel. This approach significantly improves ASR performance on previously unseen channels and languages, highlighting its ability to generalize across channel and language differences.
A Variational Framework for Improving Naturalness in Generative Spoken Language Models
Jun 17, 2025



The success of large language models in text processing has inspired their adaptation to speech modeling. However, since speech is continuous and complex, it is often discretized for autoregressive modeling. Speech tokens derived from self-supervised models (known as semantic tokens) typically focus on the linguistic aspects of speech but neglect prosodic information. As a result, models trained on these tokens can generate speech with reduced naturalness. Existing approaches try to fix this by adding pitch features to the semantic tokens. However, pitch alone cannot fully represent the range of paralinguistic attributes, and selecting the right features requires careful hand-engineering. To overcome this, we propose an end-to-end variational approach that automatically learns to encode these continuous speech attributes to enhance the semantic tokens. Our approach eliminates the need for manual extraction and selection of paralinguistic features. Moreover, it produces preferred speech continuations according to human raters. Code, samples and models are available at https://github.com/b04901014/vae-gslm.
LAPIS: A novel dataset for personalized image aesthetic assessment
Apr 10, 2025We present the Leuven Art Personalized Image Set (LAPIS), a novel dataset for personalized image aesthetic assessment (PIAA). It is the first dataset with images of artworks that is suitable for PIAA. LAPIS consists of 11,723 images and was meticulously curated in collaboration with art historians. Each image has an aesthetics score and a set of image attributes known to relate to aesthetic appreciation. Besides rich image attributes, LAPIS offers rich personal attributes of each annotator. We implemented two existing state-of-the-art PIAA models and assessed their performance on LAPIS. We assess the contribution of personal attributes and image attributes through ablation studies and find that performance deteriorates when certain personal and image attributes are removed. An analysis of failure cases reveals that both existing models make similar incorrect predictions, highlighting the need for improvements in artistic image aesthetic assessment. The LAPIS project page can be found at: https://github.com/Anne-SofieMaerten/LAPIS
On the Role of Individual Differences in Current Approaches to Computational Image Aesthetics
Feb 27, 2025Image aesthetic assessment (IAA) evaluates image aesthetics, a task complicated by image diversity and user subjectivity. Current approaches address this in two stages: Generic IAA (GIAA) models estimate mean aesthetic scores, while Personal IAA (PIAA) models adapt GIAA using transfer learning to incorporate user subjectivity. However, a theoretical understanding of transfer learning between GIAA and PIAA, particularly concerning the impact of group composition, group size, aesthetic differences between groups and individuals, and demographic correlations, is lacking. This work establishes a theoretical foundation for IAA, proposing a unified model that encodes individual characteristics in a distributional format for both individual and group assessments. We show that transferring from GIAA to PIAA involves extrapolation, while the reverse involves interpolation, which is generally more effective for machine learning. Experiments with varying group compositions, including sub-sampling by group size and disjoint demographics, reveal significant performance variation even for GIAA, indicating that mean scores do not fully eliminate individual subjectivity. Performance variations and Gini index analysis reveal education as the primary factor influencing aesthetic differences, followed by photography and art experience, with stronger individual subjectivity observed in artworks than in photos. Our model uniquely supports both GIAA and PIAA, enhancing generalization across demographics.
Speaker-IPL: Unsupervised Learning of Speaker Characteristics with i-Vector based Pseudo-Labels
Sep 16, 2024



Iterative self-training, or iterative pseudo-labeling (IPL)--using an improved model from the current iteration to provide pseudo-labels for the next iteration--has proven to be a powerful approach to enhance the quality of speaker representations. Recent applications of IPL in unsupervised speaker recognition start with representations extracted from very elaborate self-supervised methods (e.g., DINO). However, training such strong self-supervised models is not straightforward (they require hyper-parameters tuning and may not generalize to out-of-domain data) and, moreover, may not be needed at all. To this end, we show the simple, well-studied, and established i-vector generative model is enough to bootstrap the IPL process for unsupervised learning of speaker representations. We also systematically study the impact of other components on the IPL process, which includes the initial model, the encoder, augmentations, the number of clusters, and the clustering algorithm. Remarkably, we find that even with a simple and significantly weaker initial model like i-vector, IPL can still achieve speaker verification performance that rivals state-of-the-art methods.
Exploring Prediction Targets in Masked Pre-Training for Speech Foundation Models
Sep 16, 2024



Speech foundation models, such as HuBERT and its variants, are pre-trained on large amounts of unlabeled speech for various downstream tasks. These models use a masked prediction objective, where the model learns to predict information about masked input segments from the unmasked context. The choice of prediction targets in this framework can influence performance on downstream tasks. For example, targets that encode prosody are beneficial for speaker-related tasks, while targets that encode phonetics are more suited for content-related tasks. Additionally, prediction targets can vary in the level of detail they encode; targets that encode fine-grained acoustic details are beneficial for denoising tasks, while targets that encode higher-level abstractions are more suited for content-related tasks. Despite the importance of prediction targets, the design choices that affect them have not been thoroughly studied. This work explores the design choices and their impact on downstream task performance. Our results indicate that the commonly used design choices for HuBERT can be suboptimal. We propose novel approaches to create more informative prediction targets and demonstrate their effectiveness through improvements across various downstream tasks.
Exploring the Impact of Data Quantity on ASR in Extremely Low-resource Languages
Sep 13, 2024This study investigates the efficacy of data augmentation techniques for low-resource automatic speech recognition (ASR), focusing on two endangered Austronesian languages, Amis and Seediq. Recognizing the potential of self-supervised learning (SSL) in low-resource settings, we explore the impact of data volume on the continued pre-training of SSL models. We propose a novel data-selection scheme leveraging a multilingual corpus to augment the limited target language data. This scheme utilizes a language classifier to extract utterance embeddings and employs one-class classifiers to identify utterances phonetically and phonologically proximate to the target languages. Utterances are ranked and selected based on their decision scores, ensuring the inclusion of highly relevant data in the SSL-ASR pipeline. Our experimental results demonstrate the effectiveness of this approach, yielding substantial improvements in ASR performance for both Amis and Seediq. These findings underscore the feasibility and promise of data augmentation through cross-lingual transfer learning for low-resource language ASR.
VoxHakka: A Dialectally Diverse Multi-speaker Text-to-Speech System for Taiwanese Hakka
Sep 03, 2024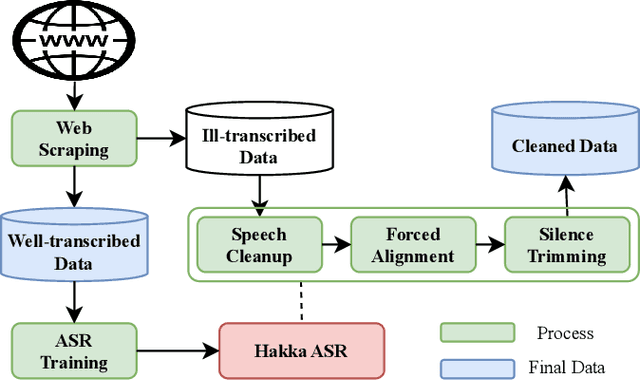
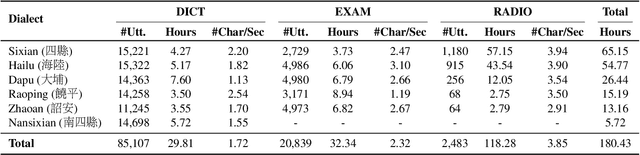
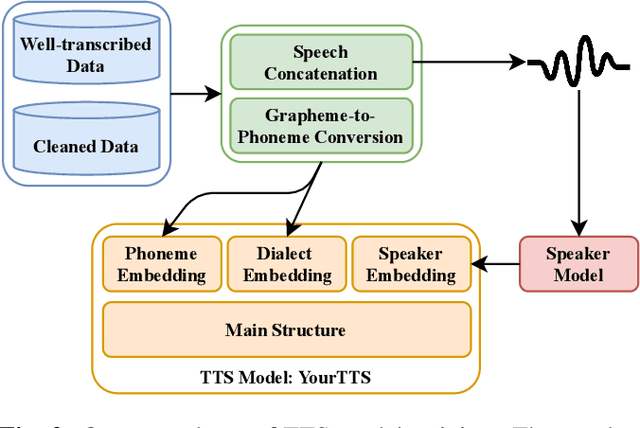
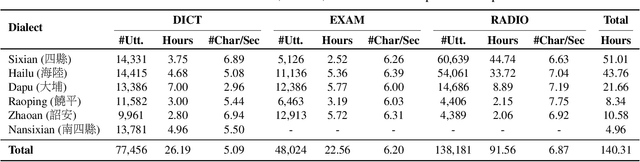
This paper introduces VoxHakka, a text-to-speech (TTS) system designed for Taiwanese Hakka, a critically under-resourced language spoken in Taiwan. Leveraging the YourTTS framework, VoxHakka achieves high naturalness and accuracy and low real-time factor in speech synthesis while supporting six distinct Hakka dialects. This is achieved by training the model with dialect-specific data, allowing for the generation of speaker-aware Hakka speech. To address the scarcity of publicly available Hakka speech corpora, we employed a cost-effective approach utilizing a web scraping pipeline coupled with automatic speech recognition (ASR)-based data cleaning techniques. This process ensured the acquisition of a high-quality, multi-speaker, multi-dialect dataset suitable for TTS training. Subjective listening tests conducted using comparative mean opinion scores (CMOS) demonstrate that VoxHakka significantly outperforms existing publicly available Hakka TTS systems in terms of pronunciation accuracy, tone correctness, and overall naturalness. This work represents a significant advancement in Hakka language technology and provides a valuable resource for language preservation and revitalization efforts.