 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePath-Constrained Mixture-of-Experts
Mar 18, 2026Sparse Mixture-of-Experts (MoE) architectures enable efficient scaling by activating only a subset of parameters for each input. However, conventional MoE routing selects each layer's experts independently, creating N^L possible expert paths -- for N experts across L layers. This far exceeds typical training set sizes, leading to statistical inefficiency as the model may not learn meaningful structure over such a vast path space. To constrain it, we propose \pathmoe, which shares router parameters across consecutive layers. Experiments on 0.9B and 16B parameter models demonstrate consistent improvements on perplexity and downstream tasks over independent routing, while eliminating the need for auxiliary load balancing losses. Analysis reveals that tokens following the same path naturally cluster by linguistic function, with \pathmoe{} producing more concentrated groups, better cross-layer consistency, and greater robustness to routing perturbations. These results offer a new perspective for understanding MoE architectures through the lens of expert paths.
SpeakStream: Streaming Text-to-Speech with Interleaved Data
May 25, 2025The latency bottleneck of traditional text-to-speech (TTS) systems fundamentally hinders the potential of streaming large language models (LLMs) in conversational AI. These TTS systems, typically trained and inferenced on complete utterances, introduce unacceptable delays, even with optimized inference speeds, when coupled with streaming LLM outputs. This is particularly problematic for creating responsive conversational agents where low first-token latency is critical. In this paper, we present SpeakStream, a streaming TTS system that generates audio incrementally from streaming text using a decoder-only architecture. SpeakStream is trained using a next-step prediction loss on interleaved text-speech data. During inference, it generates speech incrementally while absorbing streaming input text, making it particularly suitable for cascaded conversational AI agents where an LLM streams text to a TTS system. Our experiments demonstrate that SpeakStream achieves state-of-the-art latency results in terms of first-token latency while maintaining the quality of non-streaming TTS systems.
Visatronic: A Multimodal Decoder-Only Model for Speech Synthesis
Nov 26, 2024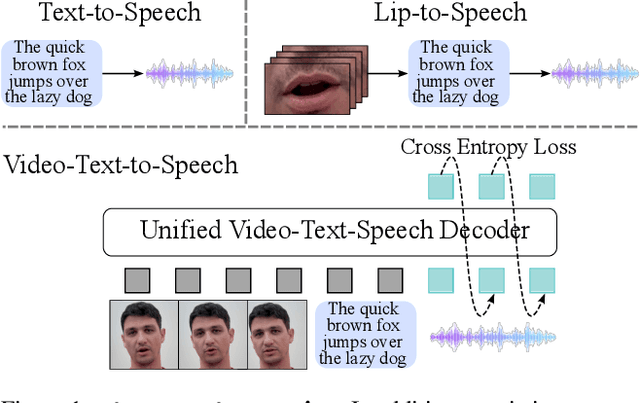



In this paper, we propose a new task -- generating speech from videos of people and their transcripts (VTTS) -- to motivate new techniques for multimodal speech generation. This task generalizes the task of generating speech from cropped lip videos, and is also more complicated than the task of generating generic audio clips (e.g., dog barking) from videos and text. Multilingual versions of the task could lead to new techniques for cross-lingual dubbing. We also present a decoder-only multimodal model for this task, which we call Visatronic. This model embeds vision, text and speech directly into the common subspace of a transformer model and uses an autoregressive loss to learn a generative model of discretized mel-spectrograms conditioned on speaker videos and transcripts of their speech. By embedding all modalities into a common subspace, Visatronic can achieve improved results over models that use only text or video as input. Further, it presents a much simpler approach for multimodal speech generation compared to prevailing approaches which rely on lip-detectors and complicated architectures to fuse modalities while producing better results. Since the model is flexible enough to accommodate different ways of ordering inputs as a sequence, we carefully explore different strategies to better understand the best way to propagate information to the generative steps. To facilitate further research on VTTS, we will release (i) our code, (ii) clean transcriptions for the large-scale VoxCeleb2 dataset, and (iii) a standardized evaluation protocol for VTTS incorporating both objective and subjective metrics.
Exploring Prediction Targets in Masked Pre-Training for Speech Foundation Models
Sep 16, 2024



Speech foundation models, such as HuBERT and its variants, are pre-trained on large amounts of unlabeled speech for various downstream tasks. These models use a masked prediction objective, where the model learns to predict information about masked input segments from the unmasked context. The choice of prediction targets in this framework can influence performance on downstream tasks. For example, targets that encode prosody are beneficial for speaker-related tasks, while targets that encode phonetics are more suited for content-related tasks. Additionally, prediction targets can vary in the level of detail they encode; targets that encode fine-grained acoustic details are beneficial for denoising tasks, while targets that encode higher-level abstractions are more suited for content-related tasks. Despite the importance of prediction targets, the design choices that affect them have not been thoroughly studied. This work explores the design choices and their impact on downstream task performance. Our results indicate that the commonly used design choices for HuBERT can be suboptimal. We propose novel approaches to create more informative prediction targets and demonstrate their effectiveness through improvements across various downstream tasks.
Speaker-IPL: Unsupervised Learning of Speaker Characteristics with i-Vector based Pseudo-Labels
Sep 16, 2024



Iterative self-training, or iterative pseudo-labeling (IPL)--using an improved model from the current iteration to provide pseudo-labels for the next iteration--has proven to be a powerful approach to enhance the quality of speaker representations. Recent applications of IPL in unsupervised speaker recognition start with representations extracted from very elaborate self-supervised methods (e.g., DINO). However, training such strong self-supervised models is not straightforward (they require hyper-parameters tuning and may not generalize to out-of-domain data) and, moreover, may not be needed at all. To this end, we show the simple, well-studied, and established i-vector generative model is enough to bootstrap the IPL process for unsupervised learning of speaker representations. We also systematically study the impact of other components on the IPL process, which includes the initial model, the encoder, augmentations, the number of clusters, and the clustering algorithm. Remarkably, we find that even with a simple and significantly weaker initial model like i-vector, IPL can still achieve speaker verification performance that rivals state-of-the-art methods.
Towards Automatic Assessment of Self-Supervised Speech Models using Rank
Sep 16, 2024


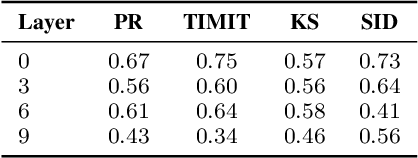
This study explores using embedding rank as an unsupervised evaluation metric for general-purpose speech encoders trained via self-supervised learning (SSL). Traditionally, assessing the performance of these encoders is resource-intensive and requires labeled data from the downstream tasks. Inspired by the vision domain, where embedding rank has shown promise for evaluating image encoders without tuning on labeled downstream data, this work examines its applicability in the speech domain, considering the temporal nature of the signals. The findings indicate rank correlates with downstream performance within encoder layers across various downstream tasks and for in- and out-of-domain scenarios. However, rank does not reliably predict the best-performing layer for specific downstream tasks, as lower-ranked layers can outperform higher-ranked ones. Despite this limitation, the results suggest that embedding rank can be a valuable tool for monitoring training progress in SSL speech models, offering a less resource-demanding alternative to traditional evaluation methods.
Theory, Analysis, and Best Practices for Sigmoid Self-Attention
Sep 06, 2024



Attention is a key part of the transformer architecture. It is a sequence-to-sequence mapping that transforms each sequence element into a weighted sum of values. The weights are typically obtained as the softmax of dot products between keys and queries. Recent work has explored alternatives to softmax attention in transformers, such as ReLU and sigmoid activations. In this work, we revisit sigmoid attention and conduct an in-depth theoretical and empirical analysis. Theoretically, we prove that transformers with sigmoid attention are universal function approximators and benefit from improved regularity compared to softmax attention. Through detailed empirical analysis, we identify stabilization of large initial attention norms during the early stages of training as a crucial factor for the successful training of models with sigmoid attention, outperforming prior attempts. We also introduce FLASHSIGMOID, a hardware-aware and memory-efficient implementation of sigmoid attention yielding a 17% inference kernel speed-up over FLASHATTENTION2 on H100 GPUs. Experiments across language, vision, and speech show that properly normalized sigmoid attention matches the strong performance of softmax attention on a wide range of domains and scales, which previous attempts at sigmoid attention were unable to fully achieve. Our work unifies prior art and establishes best practices for sigmoid attention as a drop-in softmax replacement in transformers.
Generating Gender Alternatives in Machine Translation
Jul 29, 2024



Machine translation (MT) systems often translate terms with ambiguous gender (e.g., English term "the nurse") into the gendered form that is most prevalent in the systems' training data (e.g., "enfermera", the Spanish term for a female nurse). This often reflects and perpetuates harmful stereotypes present in society. With MT user interfaces in mind that allow for resolving gender ambiguity in a frictionless manner, we study the problem of generating all grammatically correct gendered translation alternatives. We open source train and test datasets for five language pairs and establish benchmarks for this task. Our key technical contribution is a novel semi-supervised solution for generating alternatives that integrates seamlessly with standard MT models and maintains high performance without requiring additional components or increasing inference overhead.
dMel: Speech Tokenization made Simple
Jul 22, 2024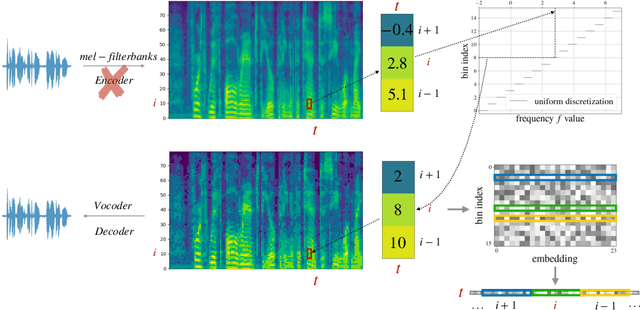

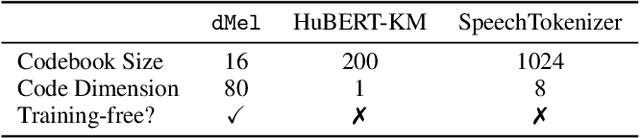
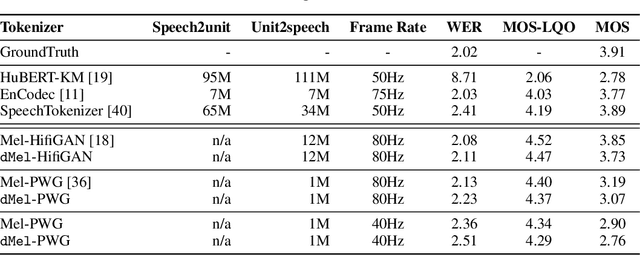
Large language models have revolutionized natural language processing by leveraging self-supervised pretraining on vast textual data. Inspired by this success, researchers have investigated complicated speech tokenization methods to discretize continuous speech signals so that language modeling techniques can be applied to speech data. However, existing approaches either model semantic tokens, potentially losing acoustic information, or model acoustic tokens, risking the loss of semantic information. Having multiple token types also complicates the architecture and requires additional pretraining. Here we show that discretizing mel-filterbank channels into discrete intensity bins produces a simple representation (dMel), that performs better than other existing speech tokenization methods. Using a transformer decoder-only architecture for speech-text modeling, we comprehensively evaluate different speech tokenization methods on speech recognition (ASR), speech synthesis (TTS). Our results demonstrate the effectiveness of dMel in achieving high performance on both tasks within a unified framework, paving the way for efficient and effective joint modeling of speech and text.
Denoising LM: Pushing the Limits of Error Correction Models for Speech Recognition
May 24, 2024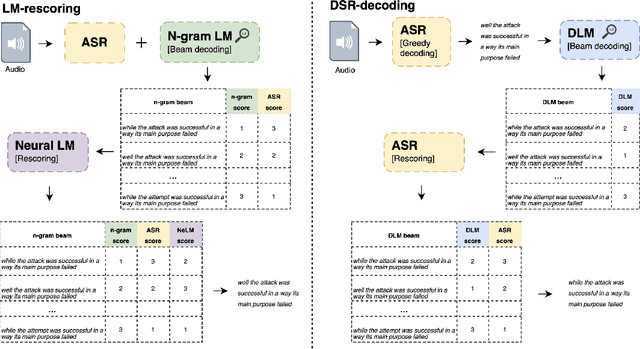
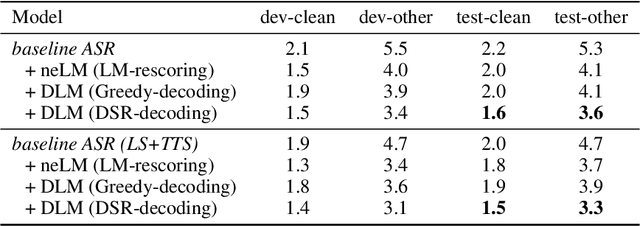

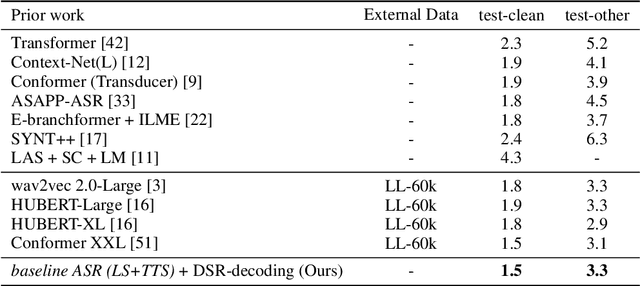
Language models (LMs) have long been used to improve results of automatic speech recognition (ASR) systems, but they are unaware of the errors that ASR systems make. Error correction models are designed to fix ASR errors, however, they showed little improvement over traditional LMs mainly due to the lack of supervised training data. In this paper, we present Denoising LM (DLM), which is a $\textit{scaled}$ error correction model trained with vast amounts of synthetic data, significantly exceeding prior attempts meanwhile achieving new state-of-the-art ASR performance. We use text-to-speech (TTS) systems to synthesize audio, which is fed into an ASR system to produce noisy hypotheses, which are then paired with the original texts to train the DLM. DLM has several $\textit{key ingredients}$: (i) up-scaled model and data; (ii) usage of multi-speaker TTS systems; (iii) combination of multiple noise augmentation strategies; and (iv) new decoding techniques. With a Transformer-CTC ASR, DLM achieves 1.5% word error rate (WER) on $\textit{test-clean}$ and 3.3% WER on $\textit{test-other}$ on Librispeech, which to our knowledge are the best reported numbers in the setting where no external audio data are used and even match self-supervised methods which use external audio data. Furthermore, a single DLM is applicable to different ASRs, and greatly surpassing the performance of conventional LM based beam-search rescoring. These results indicate that properly investigated error correction models have the potential to replace conventional LMs, holding the key to a new level of accuracy in ASR systems.