 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgedMel: Speech Tokenization made Simple
Paper and Code
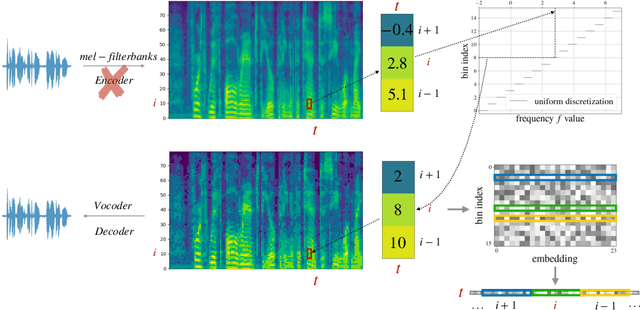

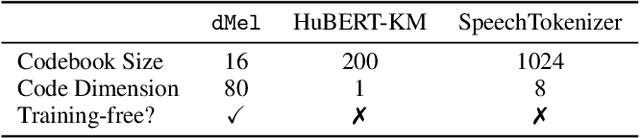
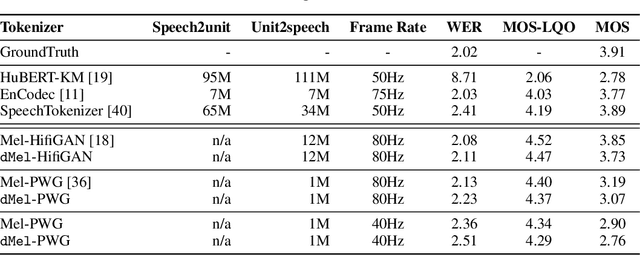
Large language models have revolutionized natural language processing by leveraging self-supervised pretraining on vast textual data. Inspired by this success, researchers have investigated complicated speech tokenization methods to discretize continuous speech signals so that language modeling techniques can be applied to speech data. However, existing approaches either model semantic tokens, potentially losing acoustic information, or model acoustic tokens, risking the loss of semantic information. Having multiple token types also complicates the architecture and requires additional pretraining. Here we show that discretizing mel-filterbank channels into discrete intensity bins produces a simple representation (dMel), that performs better than other existing speech tokenization methods. Using a transformer decoder-only architecture for speech-text modeling, we comprehensively evaluate different speech tokenization methods on speech recognition (ASR), speech synthesis (TTS). Our results demonstrate the effectiveness of dMel in achieving high performance on both tasks within a unified framework, paving the way for efficient and effective joint modeling of speech and text.