 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Properties of Continuous Diffusion Spoken Language Models
Apr 27, 2026Speech-only spoken language models (SLMs) lag behind text and text-speech models in performance, with recent discrete autoregressive (AR) SLMs indicating significant computational and data demands to match text models. Since discretizing continuous speech for AR creates bottlenecks, we explore whether continuous diffusion (CD) SLM is more viable. To quantify the SLMs linguistic quality, we introduce the phoneme Jensen-Shannon divergence (pJSD) metric. Our analysis reveals CD SLMs, mirroring AR behavior, exhibit scaling laws for validation loss and pJSD, and show optimal token-to-parameter ratios decreasing as compute scales. However, for the latter, loss becomes insensitive to choice of data and model sizes, showing potential for fast inference. Scaling CD SLMs to 16B parameters with tens of millions of hours of conversational data enables generation of emotive, prosodic, multi-speaker, multilingual speech, though achieving long-form coherence remains a significant challenge.
Embarrassingly Simple Self-Distillation Improves Code Generation
Apr 01, 2026Can a large language model (LLM) improve at code generation using only its own raw outputs, without a verifier, a teacher model, or reinforcement learning? We answer in the affirmative with simple self-distillation (SSD): sample solutions from the model with certain temperature and truncation configurations, then fine-tune on those samples with standard supervised fine-tuning. SSD improves Qwen3-30B-Instruct from 42.4% to 55.3% pass@1 on LiveCodeBench v6, with gains concentrating on harder problems, and it generalizes across Qwen and Llama models at 4B, 8B, and 30B scale, including both instruct and thinking variants. To understand why such a simple method can work, we trace these gains to a precision-exploration conflict in LLM decoding and show that SSD reshapes token distributions in a context-dependent way, suppressing distractor tails where precision matters while preserving useful diversity where exploration matters. Taken together, SSD offers a complementary post-training direction for improving LLM code generation.
Path-Constrained Mixture-of-Experts
Mar 18, 2026Sparse Mixture-of-Experts (MoE) architectures enable efficient scaling by activating only a subset of parameters for each input. However, conventional MoE routing selects each layer's experts independently, creating N^L possible expert paths -- for N experts across L layers. This far exceeds typical training set sizes, leading to statistical inefficiency as the model may not learn meaningful structure over such a vast path space. To constrain it, we propose \pathmoe, which shares router parameters across consecutive layers. Experiments on 0.9B and 16B parameter models demonstrate consistent improvements on perplexity and downstream tasks over independent routing, while eliminating the need for auxiliary load balancing losses. Analysis reveals that tokens following the same path naturally cluster by linguistic function, with \pathmoe{} producing more concentrated groups, better cross-layer consistency, and greater robustness to routing perturbations. These results offer a new perspective for understanding MoE architectures through the lens of expert paths.
LaDiR: Latent Diffusion Enhances LLMs for Text Reasoning
Oct 06, 2025



Large Language Models (LLMs) demonstrate their reasoning ability through chain-of-thought (CoT) generation. However, LLM's autoregressive decoding may limit the ability to revisit and refine earlier tokens in a holistic manner, which can also lead to inefficient exploration for diverse solutions. In this paper, we propose LaDiR (Latent Diffusion Reasoner), a novel reasoning framework that unifies the expressiveness of continuous latent representation with the iterative refinement capabilities of latent diffusion models for an existing LLM. We first construct a structured latent reasoning space using a Variational Autoencoder (VAE) that encodes text reasoning steps into blocks of thought tokens, preserving semantic information and interpretability while offering compact but expressive representations. Subsequently, we utilize a latent diffusion model that learns to denoise a block of latent thought tokens with a blockwise bidirectional attention mask, enabling longer horizon and iterative refinement with adaptive test-time compute. This design allows efficient parallel generation of diverse reasoning trajectories, allowing the model to plan and revise the reasoning process holistically. We conduct evaluations on a suite of mathematical reasoning and planning benchmarks. Empirical results show that LaDiR consistently improves accuracy, diversity, and interpretability over existing autoregressive, diffusion-based, and latent reasoning methods, revealing a new paradigm for text reasoning with latent diffusion.
DiffuCoder: Understanding and Improving Masked Diffusion Models for Code Generation
Jun 26, 2025Diffusion large language models (dLLMs) are compelling alternatives to autoregressive (AR) models because their denoising models operate over the entire sequence. The global planning and iterative refinement features of dLLMs are particularly useful for code generation. However, current training and inference mechanisms for dLLMs in coding are still under-explored. To demystify the decoding behavior of dLLMs and unlock their potential for coding, we systematically investigate their denoising processes and reinforcement learning (RL) methods. We train a 7B dLLM, \textbf{DiffuCoder}, on 130B tokens of code. Using this model as a testbed, we analyze its decoding behavior, revealing how it differs from that of AR models: (1) dLLMs can decide how causal their generation should be without relying on semi-AR decoding, and (2) increasing the sampling temperature diversifies not only token choices but also their generation order. This diversity creates a rich search space for RL rollouts. For RL training, to reduce the variance of token log-likelihood estimates and maintain training efficiency, we propose \textbf{coupled-GRPO}, a novel sampling scheme that constructs complementary mask noise for completions used in training. In our experiments, coupled-GRPO significantly improves DiffuCoder's performance on code generation benchmarks (+4.4\% on EvalPlus) and reduces reliance on AR bias during decoding. Our work provides deeper insight into the machinery of dLLM generation and offers an effective, diffusion-native RL training framework. https://github.com/apple/ml-diffucoder.
SpeakStream: Streaming Text-to-Speech with Interleaved Data
May 25, 2025The latency bottleneck of traditional text-to-speech (TTS) systems fundamentally hinders the potential of streaming large language models (LLMs) in conversational AI. These TTS systems, typically trained and inferenced on complete utterances, introduce unacceptable delays, even with optimized inference speeds, when coupled with streaming LLM outputs. This is particularly problematic for creating responsive conversational agents where low first-token latency is critical. In this paper, we present SpeakStream, a streaming TTS system that generates audio incrementally from streaming text using a decoder-only architecture. SpeakStream is trained using a next-step prediction loss on interleaved text-speech data. During inference, it generates speech incrementally while absorbing streaming input text, making it particularly suitable for cascaded conversational AI agents where an LLM streams text to a TTS system. Our experiments demonstrate that SpeakStream achieves state-of-the-art latency results in terms of first-token latency while maintaining the quality of non-streaming TTS systems.
Target Concrete Score Matching: A Holistic Framework for Discrete Diffusion
Apr 23, 2025



Discrete diffusion is a promising framework for modeling and generating discrete data. In this work, we present Target Concrete Score Matching (TCSM), a novel and versatile objective for training and fine-tuning discrete diffusion models. TCSM provides a general framework with broad applicability. It supports pre-training discrete diffusion models directly from data samples, and many existing discrete diffusion approaches naturally emerge as special cases of our more general TCSM framework. Furthermore, the same TCSM objective extends to post-training of discrete diffusion models, including fine-tuning using reward functions or preference data, and distillation of knowledge from pre-trained autoregressive models. These new capabilities stem from the core idea of TCSM, estimating the concrete score of the target distribution, which resides in the original (clean) data space. This allows seamless integration with reward functions and pre-trained models, which inherently only operate in the clean data space rather than the noisy intermediate spaces of diffusion processes. Our experiments on language modeling tasks demonstrate that TCSM matches or surpasses current methods. Additionally, TCSM is versatile, applicable to both pre-training and post-training scenarios, offering greater flexibility and sample efficiency.
SAGE: Steering and Refining Dialog Generation with State-Action Augmentation
Mar 04, 2025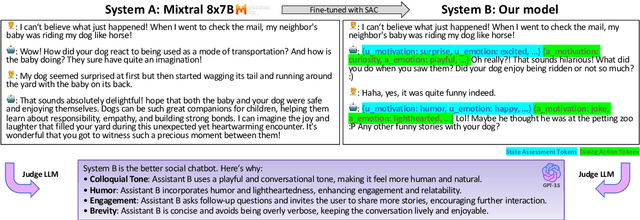
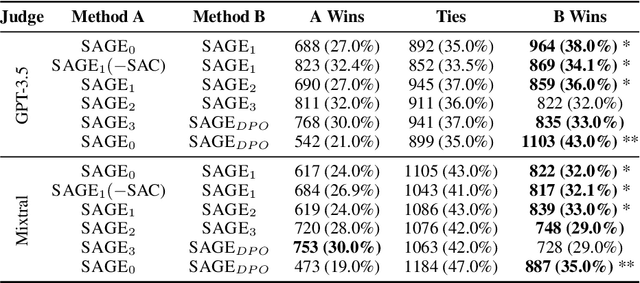
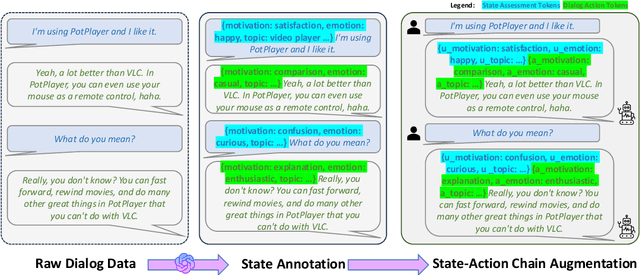
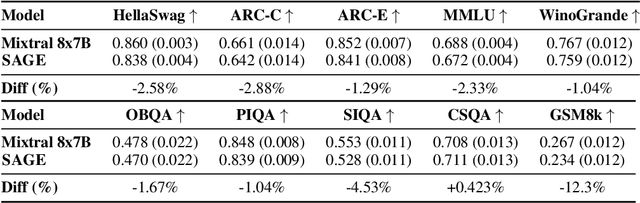
Recent advances in large language models have demonstrated impressive capabilities in task-oriented applications, yet building emotionally intelligent chatbots that can engage in natural, strategic conversations remains a challenge. We present a novel approach called SAGE that uses latent variables to control long-horizon behavior in dialogue generation. At the core of our method is the State-Action Chain (SAC), which augments standard language model fine-tuning by introducing latent variables that encapsulate emotional states and conversational strategies between dialogue turns. During inference, these variables are generated before each response, enabling coarse-grained control over dialogue progression while maintaining natural interaction patterns. We also introduce a self-improvement pipeline that leverages dialogue tree search, LLM-based reward modeling, and targeted fine-tuning to optimize conversational trajectories. Our experimental results show that models trained with this approach demonstrate improved performance in emotional intelligence metrics while maintaining strong capabilities on LLM benchmarks. The discrete nature of our latent variables facilitates search-based strategies and provides a foundation for future applications of reinforcement learning to dialogue systems, where learning can occur at the state level rather than the token level.
Reversal Blessing: Thinking Backward May Outpace Thinking Forward in Multi-choice Questions
Feb 25, 2025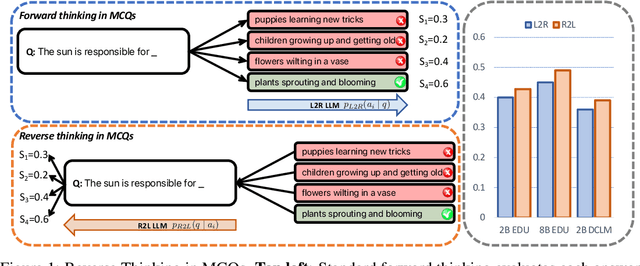
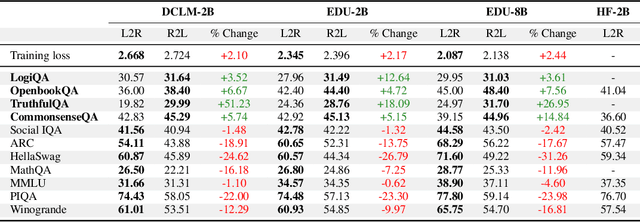
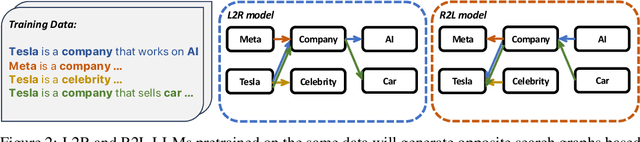
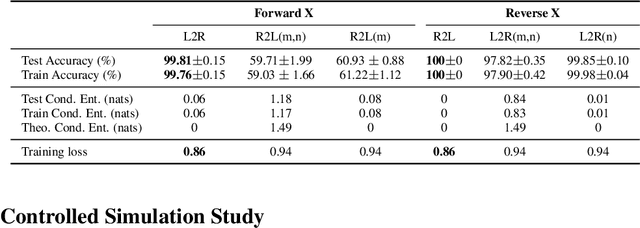
Language models usually use left-to-right (L2R) autoregressive factorization. However, L2R factorization may not always be the best inductive bias. Therefore, we investigate whether alternative factorizations of the text distribution could be beneficial in some tasks. We investigate right-to-left (R2L) training as a compelling alternative, focusing on multiple-choice questions (MCQs) as a test bed for knowledge extraction and reasoning. Through extensive experiments across various model sizes (2B-8B parameters) and training datasets, we find that R2L models can significantly outperform L2R models on several MCQ benchmarks, including logical reasoning, commonsense understanding, and truthfulness assessment tasks. Our analysis reveals that this performance difference may be fundamentally linked to multiple factors including calibration, computability and directional conditional entropy. We ablate the impact of these factors through controlled simulation studies using arithmetic tasks, where the impacting factors can be better disentangled. Our work demonstrates that exploring alternative factorizations of the text distribution can lead to improvements in LLM capabilities and provides theoretical insights into optimal factorization towards approximating human language distribution, and when each reasoning order might be more advantageous.
Eliciting In-context Retrieval and Reasoning for Long-context Large Language Models
Jan 14, 2025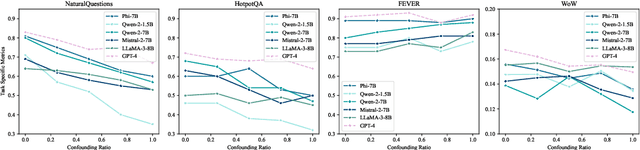

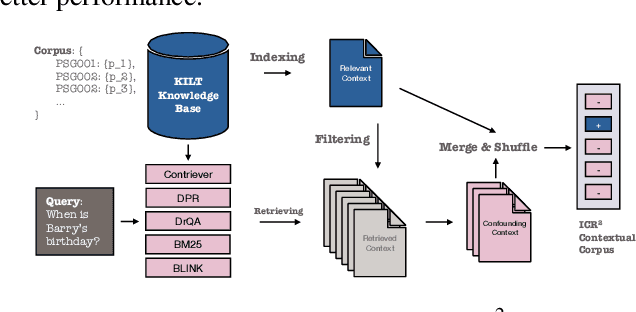
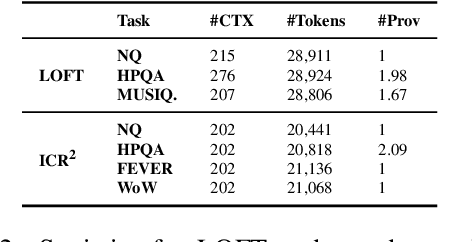
Recent advancements in long-context language models (LCLMs) promise to transform Retrieval-Augmented Generation (RAG) by simplifying pipelines. With their expanded context windows, LCLMs can process entire knowledge bases and perform retrieval and reasoning directly -- a capability we define as In-Context Retrieval and Reasoning (ICR^2). However, existing benchmarks like LOFT often overestimate LCLM performance by providing overly simplified contexts. To address this, we introduce ICR^2, a benchmark that evaluates LCLMs in more realistic scenarios by including confounding passages retrieved with strong retrievers. We then propose three methods to enhance LCLM performance: (1) retrieve-then-generate fine-tuning, (2) retrieval-attention-probing, which uses attention heads to filter and de-noise long contexts during decoding, and (3) joint retrieval head training alongside the generation head. Our evaluation of five well-known LCLMs on LOFT and ICR^2 demonstrates significant gains with our best approach applied to Mistral-7B: +17 and +15 points by Exact Match on LOFT, and +13 and +2 points on ICR^2, compared to vanilla RAG and supervised fine-tuning, respectively. It even outperforms GPT-4-Turbo on most tasks despite being a much smaller model.