 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Long-term Motion Embeddings for Efficient Kinematics Generation
Apr 13, 2026Understanding and predicting motion is a fundamental component of visual intelligence. Although modern video models exhibit strong comprehension of scene dynamics, exploring multiple possible futures through full video synthesis remains prohibitively inefficient. We model scene dynamics orders of magnitude more efficiently by directly operating on a long-term motion embedding that is learned from large-scale trajectories obtained from tracker models. This enables efficient generation of long, realistic motions that fulfill goals specified via text prompts or spatial pokes. To achieve this, we first learn a highly compressed motion embedding with a temporal compression factor of 64x. In this space, we train a conditional flow-matching model to generate motion latents conditioned on task descriptions. The resulting motion distributions outperform those of both state-of-the-art video models and specialized task-specific approaches.
STARFlow: Scaling Latent Normalizing Flows for High-resolution Image Synthesis
Jun 06, 2025
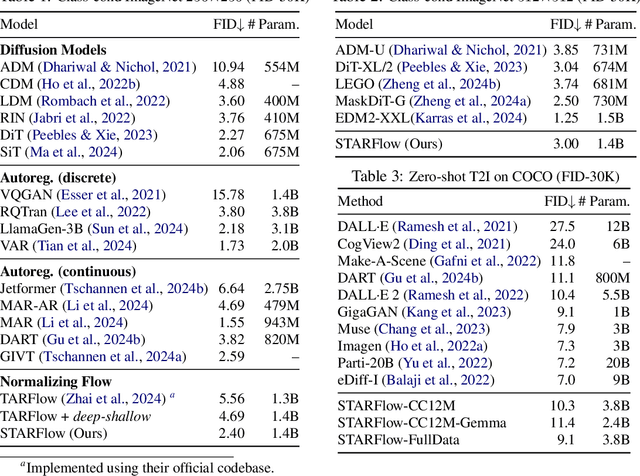
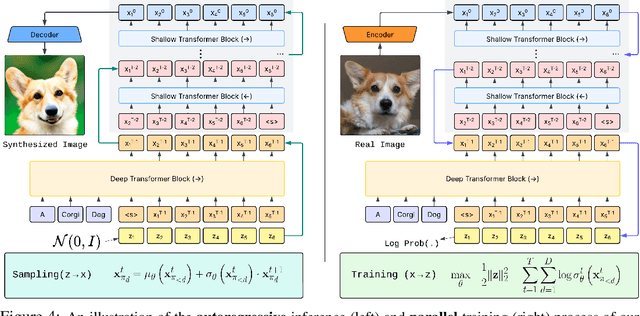
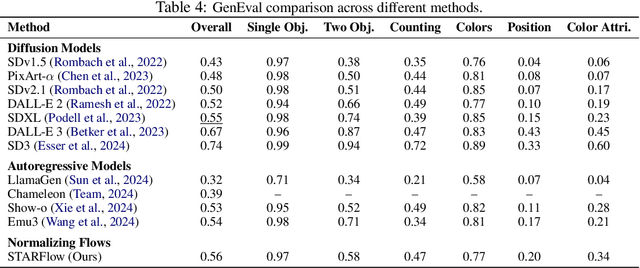
We present STARFlow, a scalable generative model based on normalizing flows that achieves strong performance in high-resolution image synthesis. The core of STARFlow is Transformer Autoregressive Flow (TARFlow), which combines the expressive power of normalizing flows with the structured modeling capabilities of Autoregressive Transformers. We first establish the theoretical universality of TARFlow for modeling continuous distributions. Building on this foundation, we introduce several key architectural and algorithmic innovations to significantly enhance scalability: (1) a deep-shallow design, wherein a deep Transformer block captures most of the model representational capacity, complemented by a few shallow Transformer blocks that are computationally efficient yet substantially beneficial; (2) modeling in the latent space of pretrained autoencoders, which proves more effective than direct pixel-level modeling; and (3) a novel guidance algorithm that significantly boosts sample quality. Crucially, our model remains an end-to-end normalizing flow, enabling exact maximum likelihood training in continuous spaces without discretization. STARFlow achieves competitive performance in both class-conditional and text-conditional image generation tasks, approaching state-of-the-art diffusion models in sample quality. To our knowledge, this work is the first successful demonstration of normalizing flows operating effectively at this scale and resolution.
Normalizing Flows are Capable Generative Models
Dec 10, 2024Normalizing Flows (NFs) are likelihood-based models for continuous inputs. They have demonstrated promising results on both density estimation and generative modeling tasks, but have received relatively little attention in recent years. In this work, we demonstrate that NFs are more powerful than previously believed. We present TarFlow: a simple and scalable architecture that enables highly performant NF models. TarFlow can be thought of as a Transformer-based variant of Masked Autoregressive Flows (MAFs): it consists of a stack of autoregressive Transformer blocks on image patches, alternating the autoregression direction between layers. TarFlow is straightforward to train end-to-end, and capable of directly modeling and generating pixels. We also propose three key techniques to improve sample quality: Gaussian noise augmentation during training, a post training denoising procedure, and an effective guidance method for both class-conditional and unconditional settings. Putting these together, TarFlow sets new state-of-the-art results on likelihood estimation for images, beating the previous best methods by a large margin, and generates samples with quality and diversity comparable to diffusion models, for the first time with a stand-alone NF model. We make our code available at https://github.com/apple/ml-tarflow.
Coordinate In and Value Out: Training Flow Transformers in Ambient Space
Dec 05, 2024



Flow matching models have emerged as a powerful method for generative modeling on domains like images or videos, and even on unstructured data like 3D point clouds. These models are commonly trained in two stages: first, a data compressor (i.e., a variational auto-encoder) is trained, and in a subsequent training stage a flow matching generative model is trained in the low-dimensional latent space of the data compressor. This two stage paradigm adds complexity to the overall training recipe and sets obstacles for unifying models across data domains, as specific data compressors are used for different data modalities. To this end, we introduce Ambient Space Flow Transformers (ASFT), a domain-agnostic approach to learn flow matching transformers in ambient space, sidestepping the requirement of training compressors and simplifying the training process. We introduce a conditionally independent point-wise training objective that enables ASFT to make predictions continuously in coordinate space. Our empirical results demonstrate that using general purpose transformer blocks, ASFT effectively handles different data modalities such as images and 3D point clouds, achieving strong performance in both domains and outperforming comparable approaches. ASFT is a promising step towards domain-agnostic flow matching generative models that can be trivially adopted in different data domains.
World-consistent Video Diffusion with Explicit 3D Modeling
Dec 02, 2024



Recent advancements in diffusion models have set new benchmarks in image and video generation, enabling realistic visual synthesis across single- and multi-frame contexts. However, these models still struggle with efficiently and explicitly generating 3D-consistent content. To address this, we propose World-consistent Video Diffusion (WVD), a novel framework that incorporates explicit 3D supervision using XYZ images, which encode global 3D coordinates for each image pixel. More specifically, we train a diffusion transformer to learn the joint distribution of RGB and XYZ frames. This approach supports multi-task adaptability via a flexible inpainting strategy. For example, WVD can estimate XYZ frames from ground-truth RGB or generate novel RGB frames using XYZ projections along a specified camera trajectory. In doing so, WVD unifies tasks like single-image-to-3D generation, multi-view stereo, and camera-controlled video generation. Our approach demonstrates competitive performance across multiple benchmarks, providing a scalable solution for 3D-consistent video and image generation with a single pretrained model.
CTRLorALTer: Conditional LoRAdapter for Efficient 0-Shot Control & Altering of T2I Models
May 13, 2024Text-to-image generative models have become a prominent and powerful tool that excels at generating high-resolution realistic images. However, guiding the generative process of these models to consider detailed forms of conditioning reflecting style and/or structure information remains an open problem. In this paper, we present LoRAdapter, an approach that unifies both style and structure conditioning under the same formulation using a novel conditional LoRA block that enables zero-shot control. LoRAdapter is an efficient, powerful, and architecture-agnostic approach to condition text-to-image diffusion models, which enables fine-grained control conditioning during generation and outperforms recent state-of-the-art approaches
Scalable Pre-training of Large Autoregressive Image Models
Jan 16, 2024



This paper introduces AIM, a collection of vision models pre-trained with an autoregressive objective. These models are inspired by their textual counterparts, i.e., Large Language Models (LLMs), and exhibit similar scaling properties. Specifically, we highlight two key findings: (1) the performance of the visual features scale with both the model capacity and the quantity of data, (2) the value of the objective function correlates with the performance of the model on downstream tasks. We illustrate the practical implication of these findings by pre-training a 7 billion parameter AIM on 2 billion images, that achieves 84.0% on ImageNet-1k with a frozen trunk. Interestingly, even at this scale, we observe no sign of saturation in performance, suggesting that AIM potentially represents a new frontier for training large-scale vision models. The pre-training of AIM is similar to the pre-training of LLMs, and does not require any image-specific strategy to stabilize the training at scale.
Generating Molecular Conformer Fields
Dec 05, 2023



In this paper we tackle the problem of generating conformers of a molecule in 3D space given its molecular graph. We parameterize these conformers as continuous functions that map elements from the molecular graph to points in 3D space. We then formulate the problem of learning to generate conformers as learning a distribution over these functions using a diffusion generative model, called Molecular Conformer Fields (MCF). Our approach is simple and scalable, and achieves state-of-the-art performance on challenging molecular conformer generation benchmarks while making no assumptions about the explicit structure of molecules (e.g. modeling torsional angles). MCF represents an advance in extending diffusion models to handle complex scientific problems in a conceptually simple, scalable and effective manner.
Adaptivity and Modularity for Efficient Generalization Over Task Complexity
Oct 13, 2023



Can transformers generalize efficiently on problems that require dealing with examples with different levels of difficulty? We introduce a new task tailored to assess generalization over different complexities and present results that indicate that standard transformers face challenges in solving these tasks. These tasks are variations of pointer value retrieval previously introduced by Zhang et al. (2021). We investigate how the use of a mechanism for adaptive and modular computation in transformers facilitates the learning of tasks that demand generalization over the number of sequential computation steps (i.e., the depth of the computation graph). Based on our observations, we propose a transformer-based architecture called Hyper-UT, which combines dynamic function generation from hyper networks with adaptive depth from Universal Transformers. This model demonstrates higher accuracy and a fairer allocation of computational resources when generalizing to higher numbers of computation steps. We conclude that mechanisms for adaptive depth and modularity complement each other in improving efficient generalization concerning example complexity. Additionally, to emphasize the broad applicability of our findings, we illustrate that in a standard image recognition task, Hyper- UT's performance matches that of a ViT model but with considerably reduced computational demands (achieving over 70\% average savings by effectively using fewer layers).
Is Generalized Dynamic Novel View Synthesis from Monocular Videos Possible Today?
Oct 12, 2023



Rendering scenes observed in a monocular video from novel viewpoints is a challenging problem. For static scenes the community has studied both scene-specific optimization techniques, which optimize on every test scene, and generalized techniques, which only run a deep net forward pass on a test scene. In contrast, for dynamic scenes, scene-specific optimization techniques exist, but, to our best knowledge, there is currently no generalized method for dynamic novel view synthesis from a given monocular video. To answer whether generalized dynamic novel view synthesis from monocular videos is possible today, we establish an analysis framework based on existing techniques and work toward the generalized approach. We find a pseudo-generalized process without scene-specific appearance optimization is possible, but geometrically and temporally consistent depth estimates are needed. Despite no scene-specific appearance optimization, the pseudo-generalized approach improves upon some scene-specific methods.